


참고
Go to the end to download the full example code.
Captum을 사용하여 모델 해석하기#
번역: 정재민
Captum을 사용하면 데이터 특징(features)이 모델의 예측 또는 뉴런 활성화에 미치는 영향을 이해하고, 모델의 동작 방식을 알 수 있습니다.
그리고 Integrated Gradients와 Guided GradCam과 같은
최첨단의 feature attribution 알고리즘을 적용할 수 있습니다.
이 레시피에서는 Captum을 사용하여 다음을 수행하는 방법을 배웁니다:
이미지 분류기(classifier)의 예측을 해당 이미지의 특징(features)에 표시하기
속성(attribution) 결과를 시각화 하기
시작하기 전에#
Captum이 Python 환경에 설치되어 있는지 확인해야 합니다.
Captum은 Github에서 pip 패키지 또는 conda 패키지로 제공됩니다.
자세한 지침은 https://captum.ai/ 의 설치 안내서를 참조하면 됩니다.
모델의 경우, PyTorch에 내장 된 이미지 분류기(classifier)를 사용합니다. Captum은 샘플 이미지의 어떤 부분이 모델에 의해 만들어진 특정한 예측에 도움을 주는지 보여줍니다.
import torchvision
from torchvision import models, transforms
from PIL import Image
import requests
from io import BytesIO
model = torchvision.models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1).eval()
response = requests.get("https://image.freepik.com/free-photo/two-beautiful-puppies-cat-dog_58409-6024.jpg")
img = Image.open(BytesIO(response.content))
center_crop = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
])
normalize = transforms.Compose([
transforms.ToTensor(), # 이미지를 0에서 1사이의 값을 가진 Tensor로 변환
transforms.Normalize( # 0을 중심으로 하는 imagenet 픽셀의 RGB 분포를 따르는 정규화
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
input_img = normalize(center_crop(img)).unsqueeze(0)
속성(attribution) 계산하기#
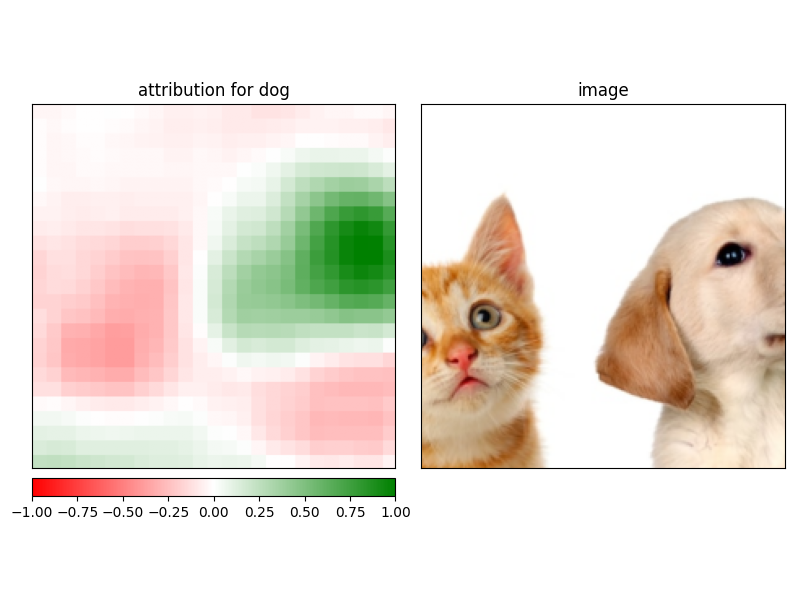
모델의 top-3 예측 중에는 개와 고양이에 해당하는 클래스 208과 283이 있습니다.
Captum의 Occlusion알고리즘을 사용하여 각 예측을 입력의 해당 부분에 표시합니다.
from captum.attr import Occlusion
occlusion = Occlusion(model)
strides = (3, 9, 9) # 작을수록 = 세부적인 속성이지만 느림
target=208, # ImageNet에서 Labrador의 인덱스
sliding_window_shapes=(3,45, 45) # 객체의 모양을 변화시키기에 충분한 크기를 선택
baselines = 0 # 이미지를 가릴 값, 0은 회색
attribution_dog = occlusion.attribute(input_img,
strides = strides,
target=target,
sliding_window_shapes=sliding_window_shapes,
baselines=baselines)
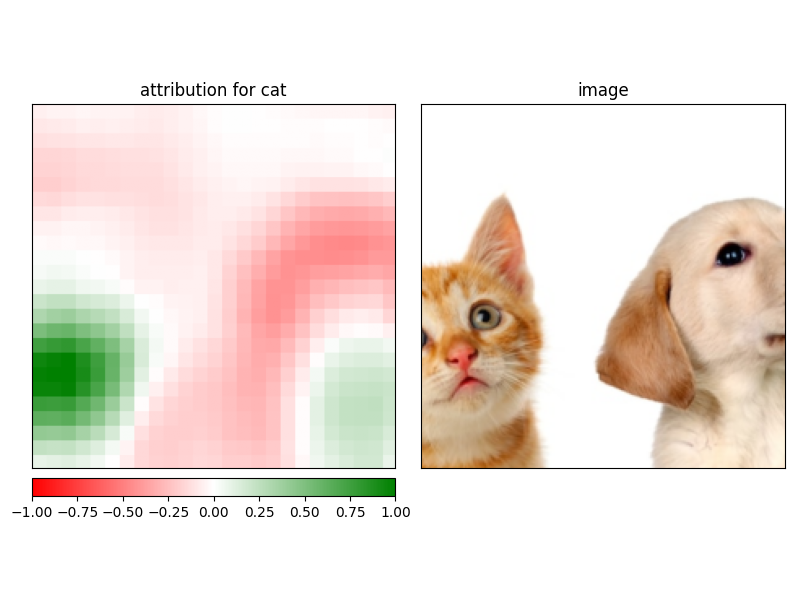
target=283, # ImageNet에서 Persian cat의 인덱스
attribution_cat = occlusion.attribute(input_img,
strides = strides,
target=target,
sliding_window_shapes=sliding_window_shapes,
baselines=0)
Captum은 Occlusion 외에도 Integrated Gradients, Deconvolution,
GuidedBackprop, Guided GradCam, DeepLift,
그리고 GradientShap과 같은 많은 알고리즘을 제공합니다.
이러한 모든 알고리즘은 초기화할 때 모델을 호출 가능한 forward_func으로 기대하며
속성(attribution) 결과를 통합해서 반환하는 attribute(...) 메소드를 가지는
Attribution 의 서브클래스 입니다.
이미지인 경우 속성(attribution) 결과를 시각화 해보겠습니다.
결과 시각화하기#
Captum의 visualization유틸리티는 그림과 텍스트 입력 모두에 대한
속성(attribution) 결과를 시각화 할 수 있는 즉시 사용가능한 방법을 제공합니다.
import numpy as np
from captum.attr import visualization as viz
# 계산 속성 Tensor를 이미지 같은 numpy 배열로 변환합니다.
attribution_dog = np.transpose(attribution_dog.squeeze().cpu().detach().numpy(), (1,2,0))
vis_types = ["heat_map", "original_image"]
vis_signs = ["all", "all"] # "positive", "negative", 또는 모두 표시하는 "all"
# positive 속성은 해당 영역의 존재가 예측 점수를 증가시킨다는 것을 의미합니다.
# negative 속성은 해당 영역의 존재가 예측 점수를 낮추는 오답 영역을 의미합니다.
_ = viz.visualize_image_attr_multiple(attribution_dog,
np.array(center_crop(img)),
vis_types,
vis_signs,
["attribution for dog", "image"],
show_colorbar = True
)
attribution_cat = np.transpose(attribution_cat.squeeze().cpu().detach().numpy(), (1,2,0))
_ = viz.visualize_image_attr_multiple(attribution_cat,
np.array(center_crop(img)),
["heat_map", "original_image"],
["all", "all"], # positive/negative 속성 또는 all
["attribution for cat", "image"],
show_colorbar = True
)
만약 데이터가 텍스트인 경우 visualization.visualize_text() 는
입력 텍스트 위에 속성(attribution)을 탐색할 수 있는 전용 뷰(view)를 제공합니다.
http://captum.ai/tutorials/IMDB_TorchText_Interpret 에서 자세한 내용을 확인하세요.
마지막 노트#
Captum은 이미지, 텍스트 등을 포함하여 다양한 방식으로 PyTorch에서 대부분의 모델 타입을 처리할 수 있습니다. Captum을 사용하면 다음을 수행할 수 있습니다. * 위에서 설명한 것처럼 특정한 출력을 모델 입력에 표시하기 * 특정한 출력을 은닉층의 뉴런에 표시하기 (Captum API reference를 보세요). * 모델 입력에 대한 은닉층 뉴런의 반응을 표시하기 (Captum API reference를 보세요).
지원되는 메소드의 전체 API와 튜토리얼의 목록은 http://captum.ai 를 참조하세요.
Gilbert Tanner의 또 다른 유용한 게시물 : https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum
Total running time of the script: (0 minutes 8.412 seconds)
