


Raspberry Pi 4 에서 실시간 추론(Inference) (30fps!)#
- Author: Tristan Rice
번역: 조윤진
파이토치(PyTorch)는 라즈베리 파이 4(Raspberry Pi 4)에서 별도의 설정 없이도 동작합니다. 이 튜토리얼은 Raspberry Pi 4에서 PyTorch를 설정하는 방법과 CPU에서 실시간(30fps 이상)으로 MobileNet v2 분류 모델을 실행하는 방법을 안내합니다.
이 튜토리얼은 모두 Raspberry Pi 4 Model B 4GB를 이용해 테스트 했지만 2GB 변형 모델(variant) 이나 3B에서도 낮은 성능으로 작동합니다.

준비물#
이 튜토리얼을 따라하려면 Raspberry Pi 4, 카메라, 기타 모든 표준 액세서리가 필요합니다.
방열판 및 팬 (선택사항이지만 사용하는 걸 권장합니다.)
5V 3A USB-C 전원 공급 장치
SD 카드 (최소 8GB)
SD 카드 리더기
Raspberry Pi 4 설정#
PyTorch는 Arm 64비트(aarch64)용 pip 패키지만 제공하므로 Raspberry Pi 에 64비트 버전의 OS를 설치해야 합니다.
https://downloads.raspberrypi.org/raspios_arm64/images/ 에서 최신 arm64 Raspberry Pi OS를 다운로드 후 rpi-imager를 통해 설치합니다.
32-bit Raspberry Pi OS 에서는 동작하지 않습니다.

설치는 인터넷 속도와 SD 카드 속도에 따라 최소 몇 분 이상 걸립니다. 완료되면 다음과 같이 보여야 합니다.
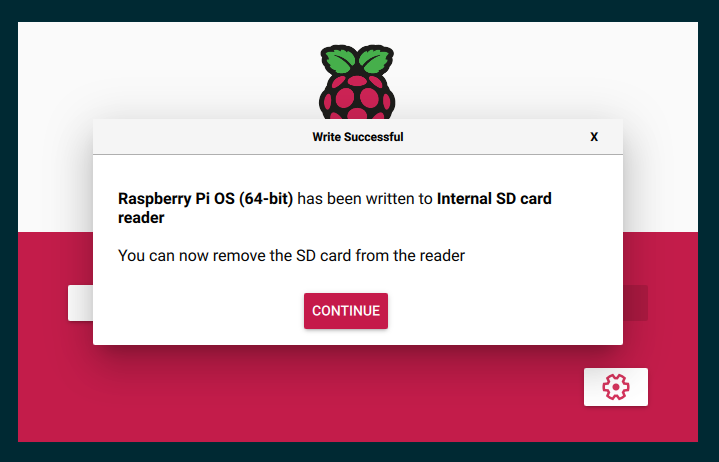
SD 카드를 Raspberry Pi 에 넣고 카메라를 연결하고 부팅합니다.
부팅 후 초기 설정을 완료하면 /boot/config.txt 파일을 편집하여 카메라를 활성화 해야 합니다.
# 카메라와 같은 확장 기능을 활성화 합니다.
start_x=1
# 카메라 처리를 위해 최소 128M 이상 되어야 하고 이보다 크면 그대로 두어도 됩니다.
gpu_mem=128
# OpenCV/V4L2를 이용한 촬영에 이슈를 발생시키기 때문에 기존 camera_auto_detect 줄을 주석 처리 하거나 삭제해야 합니다.
#camera_auto_detect=1
이후 재부팅 합니다. 재부팅이 완료된 후 video4linux2 장치 /dev/video0 가 존재해야 합니다.
PyTorch 및 OpenCV 설치#
이 튜토리얼에서 필요한 PyTorch와 다른 모든 라이브러리는 ARM 64-bit/aarch64 용(variants)이 있으므로 pip를 통해 설치하면 다른 Linux 장치처럼 작동합니다.
$ pip install torch torchvision torchaudio
$ pip install opencv-python
$ pip install numpy --upgrade
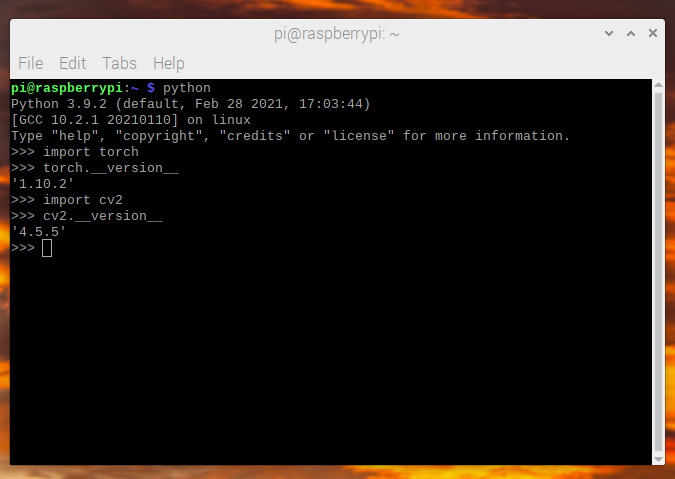
모든 것이 제대로 설치되었는지 확인합니다.
$ python -c "import torch; print(torch.__version__)"
영상 촬영#
영상 촬영의 경우 더 일반적으로 쓰이는 picamera 대신 OpenCV를 사용하여 영상 프레임을 스트리밍 할 것입니다.
picamera 는 64-bit Raspberry Pi OS에서 사용이 불가능하고 OpenCV보다 훨씬 느립니다.
OpenCV는 /dev/video0 장치에 직접 접근하여 프레임을 가져옵니다.
이 튜토리얼에서 사용하는 모델 (MobileNetV2) 은 224x224 크기의 이미지를 사용하므로 OpenCV에서 36fps를 직접 요청할 수 있습니다.
이 튜토리얼은 30fps를 목표로 하는 모델이지만 그보다 약간 더 높은 프레임 속도를 요청하여 항상 프레임이 충분하도록 합니다.
import cv2
from PIL import Image
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 224)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 224)
cap.set(cv2.CAP_PROP_FPS, 36)
OpenCV는 numpy 배열을 BGR로 반환하므로 이 배열을 읽고 약간의 섞는 작업을 거쳐 예상 가능한 RGB 형식으로 가져옵니다.
ret, image = cap.read()
# opencv 출력을 BGR에서 RGB로 변환합니다.
image = image[:, :, [2, 1, 0]]
데이터를 읽고 처리하는데 약 3.5ms 가 걸립니다.
이미지 처리#
프레임을 가져와서 예상하는 형식으로 변환해야 합니다. 이것은 표준 torchvision 변환을 사용하는 것과 동일한 처리입니다.
from torchvision import transforms
preprocess = transforms.Compose([
# 학습을 위해 프레임을 CHW torch tensor로 변환
transforms.ToTensor(),
# mobilenet_v2/3의 색 범위로 정규화
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(image)
# 모델은 여러 이미지를 동시에 처리할 수 있으므로
# 배치에 빈 차원을 추가해야 합니다.
# [3, 224, 224] -> [1, 3, 224, 224]
input_batch = input_tensor.unsqueeze(0)
모델 선정#
다양한 성능 특징을 가진 여러 모델이 있어 선택할 수 있습니다.
모든 모델이 사전 훈련된 qnnpack 을 제공하는 것은 아니므로
테스트용으로 그러한 것을 선택할 수 있지만 만약 직접 훈련하고 양자화 하는 경우
자신의 모델을 사용할 수 있습니다.
이 튜토리얼에서는 좋은 성능과 정확도를 가진 mobilenet_v2 를
사용합니다.
Raspberry Pi 4 벤치마크 결과:
모델 |
FPS |
전체 시간 (ms/frame) |
모델 시간 (ms/frame) |
qnnpack 사전훈련 |
|---|---|---|---|---|
mobilenet_v2 |
33.7 |
29.7 |
26.4 |
True |
mobilenet_v3_large |
29.3 |
34.1 |
30.7 |
True |
resnet18 |
9.2 |
109.0 |
100.3 |
False |
resnet50 |
4.3 |
233.9 |
225.2 |
False |
resnext101_32x8d |
1.1 |
892.5 |
885.3 |
False |
inception_v3 |
4.9 |
204.1 |
195.5 |
False |
googlenet |
7.4 |
135.3 |
132.0 |
False |
shufflenet_v2_x0_5 |
46.7 |
21.4 |
18.2 |
False |
shufflenet_v2_x1_0 |
24.4 |
41.0 |
37.7 |
False |
shufflenet_v2_x1_5 |
16.8 |
59.6 |
56.3 |
False |
shufflenet_v2_x2_0 |
11.6 |
86.3 |
82.7 |
False |
MobileNetV2: 양자화 그리고 JIT#
최적의 성능을 위해서는 양자화되고 융합된 모델이 필요합니다.
양자화되었다는 뜻은 표준 float32 연산보다 훨씬 성능이 좋은 int8을 사용하여 계산하는 것입니다.
융합되었다는 뜻은 가능한 경우 연속된 작업이 더 성능이 좋은 버전으로 함께 합쳐진 것을 말합니다.
일반적으로 활성화 (ReLU)와 같은 것들은 추론(inference)하는 동안 이전 레이어 (Conv2d)
에 병합될 수 있습니다.
aarch64 버전의 pytorch는 qnnpack 엔진을 사용해야 합니다.
import torch
torch.backends.quantized.engine = 'qnnpack'
이 예제에서는 torchvision에서 바로 사용할 수 있는 미리 양자화(prequantized)와 융합된(fused) 버전의 MobileNetV2를 사용합니다.
from torchvision import models
net = models.quantization.mobilenet_v2(pretrained=True, quantize=True)
다음으로 Python 오버헤드를 줄이고 모든 작업을 융합하기 위해 모델을 JIT합니다. JIT 없이는 ~20fps이지만 JIT를 사용하면 ~30fps입니다.
net = torch.jit.script(net)
모두 합치기#
위의 모든 코드를 합쳐 실행합니다.
import time
import torch
import numpy as np
from torchvision import models, transforms
import cv2
from PIL import Image
torch.backends.quantized.engine = 'qnnpack'
cap = cv2.VideoCapture(0, cv2.CAP_V4L2)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 224)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 224)
cap.set(cv2.CAP_PROP_FPS, 36)
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
net = models.quantization.mobilenet_v2(pretrained=True, quantize=True)
# ~20fps에서 ~30fps로 향상시키는 JIT 모델
net = torch.jit.script(net)
started = time.time()
last_logged = time.time()
frame_count = 0
with torch.no_grad():
while True:
# 영상 읽기
ret, image = cap.read()
if not ret:
raise RuntimeError("failed to read frame")
# OpenCV 출력을 BGR에서 RGB로 변환
image = image[:, :, [2, 1, 0]]
permuted = image
# 전처리(preprocessing)
input_tensor = preprocess(image)
# 모델에 의해 예상되는 미니 배치(mini-batch) 생성
input_batch = input_tensor.unsqueeze(0)
# 모델 실행
output = net(input_batch)
# output 출력 변수로 무언가를 처리 ...
# 모델 성능 기록
frame_count += 1
now = time.time()
if now - last_logged > 1:
print(f"{frame_count / (now-last_logged)} fps")
last_logged = now
frame_count = 0
실행하면 약 ~30fps가 나오는 것을 볼 수 있습니다.
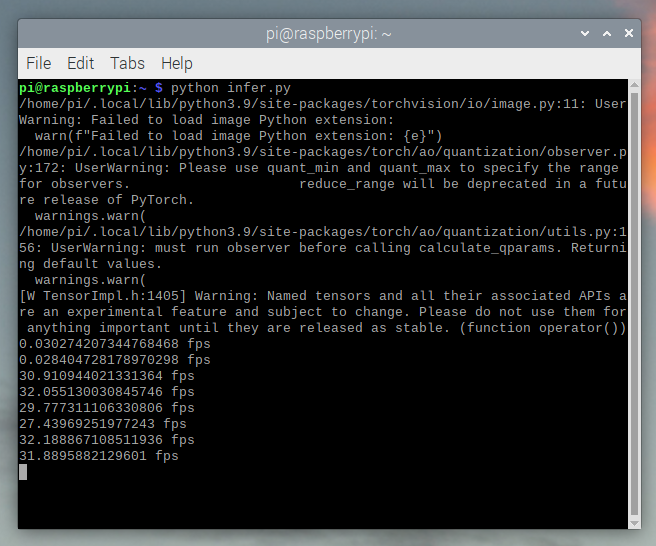
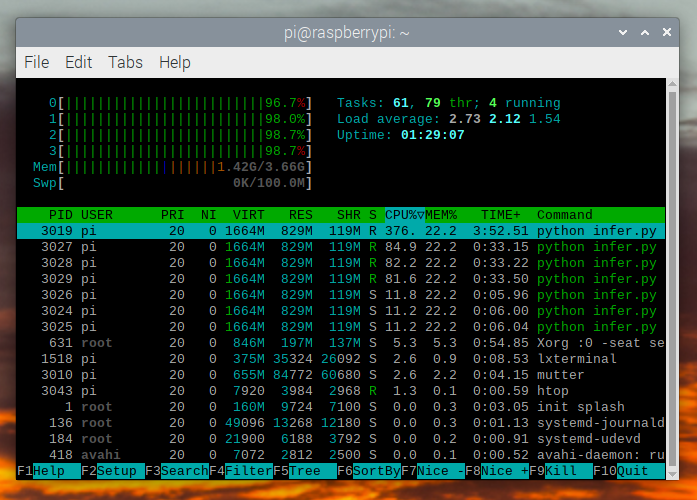
이는 Raspberry Pi OS의 기본 설정입니다. 만약 UI와 기본적으로 활성화된 다른 모든 백그라운드 서비스를 비활성화하면 더 성능이 좋고 안정적입니다.
htop 을 확인하면 거의 100% 활용하고 있는 것을 볼 수 있습니다.
처음부터 끝까지 작동하는 것을 확인하기 위해서는 클래스의 확률을 계산하고 ImageNet 클래스 레이블을 사용하여 탐지된 것을 출력할 수 있습니다.
top = list(enumerate(output[0].softmax(dim=0)))
top.sort(key=lambda x: x[1], reverse=True)
for idx, val in top[:10]:
print(f"{val.item()*100:.2f}% {classes[idx]}")
실시간 mobilenet_v3_large 동작:
오렌지 탐지:

머그컵 탐지:

문제 해결: 성능#
PyTorch는 기본적으로 사용 가능한 모든 코어를 사용합니다. 만약 Raspberry Pi의 백그라운드에서 돌아가고 있는 것이 있다면 모델 추론에서 경합(contention)이 발생하여 지연 시간 스파이크(spikes)가 발생할 수 있습니다. 이를 완화하기 위해서는 스레드 수를 줄여 약간의 성능 저하로 최대 지연 시간을 줄일 수 있습니다.
torch.set_num_threads(2)
shufflenet_v2_x1_5 의 경우 4개의 스레드 대신 2개의 스레드 를 사용시
최적의 상황에서 지연 시간이 60ms 에서 72ms 로 증가하지만
128ms 의 대기 시간 스파이크를 제거합니다.
다음 단계#
자신만의 모델을 만들거나 기존 모델을 미세 조정(finetune)할 수 있습니다. torchvision.models.quantized 의 모델 중 하나를 미세 조정하면 대부분의 양자화, 융합 작업이 이미 되어있어 Raspberry Pi에서 좋은 성능으로 직접 배포할 수 있습니다.
더보기:
Quantization 자신의 모델을 양자화 및 융합하는 방법에 대한 자세한 정보.
전이학습(Transfer Learning)을 사용하여 데이터셋에 맞게 기존 모델을 미세 조정하는 방법에 대한 전이 학습 튜토리얼 전이학습(Transfer Learning) 튜토리얼
