


참고
Go to the end to download the full example code.
Introduction || Tensors || Autograd || Building Models || TensorBoard Support || Training Models || Model Understanding
PyTorch 소개#
아래 영상이나 youtube 를 참고하세요.
PyTorch Tensors#
03:50 에 시작하는 영상을 시청하세요.
PyTorch를 import할 것입니다.
import torch
몇 가지 기본적인 tensor 조작을 알아보겠습니다. 처음으로, tensor들을 만드는 몇 가지 방법을 살펴보겠습니다:
z = torch.zeros(5, 3)
print(z)
print(z.dtype)
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
torch.float32
위에서, 0으로 채워진 5x3 행렬을 만들고, 파이토치의 기본 타입인, 0으로 채워진 32비트 부동소수점 데이터 타입인지 확인합니다.
만약 정수형 데이터 타입을 원한다면 기본값을 재정의할 수 있습니다:
i = torch.ones((5, 3), dtype=torch.int16)
print(i)
tensor([[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]], dtype=torch.int16)
dtype의 기본값을 변경하면 tensor가 출력될 때 데이터 타입을 확인할 수 있습니다.
학습 가중치를 무작위로 초기화하는 것이 일반적이며, 종종 결과의 재현성을 위해 PRNG에 대한 특정 시드로 초기화합니다.
torch.manual_seed(1729)
r1 = torch.rand(2, 2)
print('랜덤 tensor 값:')
print(r1)
r2 = torch.rand(2, 2)
print('\n다른 랜덤 tensor 값:')
print(r2) # 새로운 2x2 행렬 값
torch.manual_seed(1729)
r3 = torch.rand(2, 2)
print('\nr1과 일치:')
print(r3) # 동일한 시드값으로 인해 r1 값이 반복되어 행렬값으로 나옵니다.
랜덤 tensor 값:
tensor([[0.3126, 0.3791],
[0.3087, 0.0736]])
다른 랜덤 tensor 값:
tensor([[0.4216, 0.0691],
[0.2332, 0.4047]])
r1과 일치:
tensor([[0.3126, 0.3791],
[0.3087, 0.0736]])
PyTorch tensor는 산술 연산을 직관적으로 수행합니다. 유사한 shape의 tensor들이 더하거나 곱하거나 그 외 연산도 가능합니다. 스칼라를 사용한 연산은 tensor에 분산됩니다.
ones = torch.ones(2, 3)
print(ones)
twos = torch.ones(2, 3) * 2 # 모든 원소에 2를 곱합니다.
print(twos)
threes = ones + twos # shape이 비슷하기 때문에 더할 수 있습니다.
print(threes) # tensor의 원소별 더한 값이 결과로 나옵니다.
print(threes.shape) # 입력 tensor와 동일한 차원을 가지고 있습니다.
r1 = torch.rand(2, 3)
r2 = torch.rand(3, 2)
# 런타임 오류를 발생시키려면 아래 줄의 주석을 해제합니다.
# r3 = r1 + r2
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[2., 2., 2.],
[2., 2., 2.]])
tensor([[3., 3., 3.],
[3., 3., 3.]])
torch.Size([2, 3])
다음은 사용 가능한 작은 수학 연산 예제 입니다:
r = (torch.rand(2, 2) - 0.5) * 2 # -1과 1 사이의 값을 가집니다.
print('랜덤 행렬값, r:')
print(r)
# 일반적인 수학적 연산은 다음과 같이 지원됩니다:
print('\nr의 절대값:')
print(torch.abs(r))
# 삼각함수를 사용할 수 있습니다:
print('\nr의 역 사인 함수:')
print(torch.asin(r))
# 행렬식 및 특이값 분해와 같은 선형 대수 연산을 사용할 수 있습니다.
print('\nr의 행렬식:')
print(torch.det(r))
print('\nr의 특이값 분해:')
print(torch.svd(r))
# 통계 및 집합 연산 등을 사용할 수 있습니다:
print('\nr의 평균 및 표준편차:')
print(torch.std_mean(r))
print('\nr의 최대값:')
print(torch.max(r))
랜덤 행렬값, r:
tensor([[ 0.9956, -0.2232],
[ 0.3858, -0.6593]])
r의 절대값:
tensor([[0.9956, 0.2232],
[0.3858, 0.6593]])
r의 역 사인 함수:
tensor([[ 1.4775, -0.2251],
[ 0.3961, -0.7199]])
r의 행렬식:
tensor(-0.5703)
r의 특이값 분해:
torch.return_types.svd(
U=tensor([[-0.8353, -0.5497],
[-0.5497, 0.8353]]),
S=tensor([1.1793, 0.4836]),
V=tensor([[-0.8851, -0.4654],
[ 0.4654, -0.8851]]))
r의 평균 및 표준편차:
(tensor(0.7217), tensor(0.1247))
r의 최대값:
tensor(0.9956)
GPU에서 병렬 연산을 위해 설정하는 방법을 포함하여 PyTorch tensor의 강력함에 대해 알아야 할 것이 있습니다. 이 내용은 다른 영상에서 자세히 살펴보겠습니다.
PyTorch Models#
PyTorch Model 영상은 10:00 에 시작합니다.
PyTorch에서 Model을 표현할 수 있는 방법에 대해 알아보겠습니다.
import torch # PyTorch 모든 모듈 가져오기
import torch.nn as nn # torch.nn.Module의 경우 PyTorch model의 부모 객체
import torch.nn.functional as F # 활성화 함수 모듈 가져오기
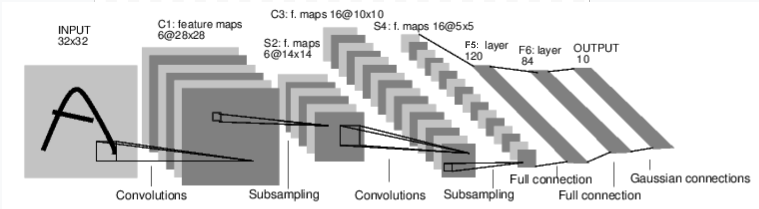
그림: LeNet-5
LeNet-5의 다이어그램은 초기 합성곱 신경망 중 하나이자 딥 러닝에서 폭발적인 인기를 일으킨 요인중 하나입니다. 손으로 쓴 숫자 이미지(MNIST 데이터셋)를 읽고 이미지에 어떤 숫자가 표현되었는지 정확하게 분류하기 위해 제작되었습니다.
LeNet-5가 어떻게 동작하는지에 대한 간단한 설명은 다음과 같습니다:
계층 C1은 합성곱 계층입니다. 즉, 입력 이미지에서 학습 중에 배웠던 특징을 검색합니다. 이미지에서 학습된 각 특징을 위치에 대한 출력 맵을 보여줍니다. 이 “활성화 맵” 으로 S2 계층에서 다운샘플링됩니다.
계층 C3는 다른 합성곱 계층으로, 이 시점은 특징들의 조합 을 위해 C1 활성화 맵 검색합니다. 또한, 계층 S4에서 다운샘플링된 이러한 특징 조합의 spatial locations을 제공합니다.
마지막으로, 완전 연결 계층(fully-connected layers)인 F5, F6, OUTPUT은 최종 활성화 맵을 가져와 십진수를 표현하는 10개의 bin 중 하나로 분류 하는 분류기입니다.
이 간단한 신경망을 코드로 어떻게 표현할 수 있을까요?
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 입력 이미지 채널, 6개의 output 채널, 5x5 정방 합성곱 커널을 사용합니다.
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 아핀 변환: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 이미지 차원
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 최대 풀링은 (2, 2) 윈도우 크기를 사용합니다.
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 크기가 정방 사이즈인 경우, 단일 숫자만 지정할 수 있습니다.
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 크기는 배치 차원을 제외한 모든 차원을 가져옵니다.
num_features = 1
for s in size:
num_features *= s
return num_features
코드를 살펴보면 구조적으로 위 다이어그램과 유사점을 발견할 수 있습니다.
다음은 일반적인 PyTorch 모델의 구조를 보여줍니다:
모듈은 중첩될 수 있으며
torch.nn.Module에서 상속됩니다. - 실제로,Conv2d와Linear계층 클래스도torch.nn.Module에서 상속됩니다.모델은 계층을 인스턴스화하고 필요한 데이터 아티팩트를 로드하는
__init__()함수를 가지고 있습니다. (예를들면 NLP 모델은 어휘를 불러올 수 있)모델은
forward()함수를 가지고 있다. 여기서 실제 계산이 수행됩니다. 입력은 네트워크 계층 및 다양한 기능들을 통과시켜 결과를 생성합니다.그 외에는 다른 파이썬 클래스처럼 모델 클래스를 구성할 수 있습니다. Python 클래스, 모델의 계산을 지원하는 데 필요한 속성 및 메서드를 추가합니다.
자 이제 만든 오브젝트를 인스턴스화하고 샘플 입력을 통해 실행합니다.
net = LeNet()
print(net) # 인스턴스한 객체를 출력하면 어떤 값을 보여줄까요?
input = torch.rand(1, 1, 32, 32) # 32x32 크기의 1채널의 흑백 이미지를 만듭니다.
print('\n이미지 배치 shape:')
print(input.shape)
output = net(input) # 객체로부터 직접 forward() 함수를 호출하지 않습니다.
print('\n:결과 값')
print(output)
print(output.shape)
LeNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
이미지 배치 shape:
torch.Size([1, 1, 32, 32])
:결과 값
tensor([[ 0.0898, 0.0318, 0.1485, 0.0301, -0.0085, -0.1135, -0.0296, 0.0164,
0.0039, 0.0616]], grad_fn=<AddmmBackward0>)
torch.Size([1, 10])
위에서 몇가지 중요한 일들이 일어나고 있습니다.
첫째, LeNet 클래스를 인스턴스화하고 net 객체를 출력합니다.
torch.nn.Module 의 하위 클래스는 생성된 레이어의 모양과 파라미터를 알려줍니다.
모델의 처리 결과를 얻으려는 경우, 모델의 편리한 기능을 제공할 수 있습니다.
아래에서 1 채널과 32x32 이미지크기를 가진 더미 입력을 생성합니다. 일반적으로 배치 이미지를읽어들이고,이미지와 같은 크기의 텐서로 변환합니다.
tensor 의 추가 차원인 batch 차원 을 알아챘을 수 있습니다.
PyTorch 모델은 데이터의 batch 에 작업한다고 가정합니다. 예를들어
16개 이미지의 배치는 (1, 1, 32, 32) 모양을 가질 것입니다.
이 샘플에서는 하나의 이미지만 사용하기 때문에 (1, 1, 32, 32) 모양을 가진
batch를 만듭니다.
모델을 함수처럼 net(input) 를 호출하여 추론을 요청합니다:
호출의 결과는 입력 이미지가 특정 숫자를 나타내는 모델의 신뢰도를 나타냅니다.
(모델의 인스턴스는 아직 아무것도 학습하지 않았기 때문에 출력에서 좋은 결과를
기대해서는 안 됩니다) output 결과를 확인해보면 batch 차원을 가지고 있다는
것을 알 수 있는데, 크기는 항상 입력 batch 차원과 일치해야 합니다.
만약 16개의 인스턴스로 이루어진 입력으로 모델을 통과했다면 output 는
(16, 10) 의 형태를 가지고 있습니다.
Datasets 및 Dataloaders#
14:00 에 시작하는 영상을 시청하세요.
아래 예제에서는 TorchVision에서 바로 다운로드할 수 있는 오픈 데이터셋 중 하나를 사용하여 모델을 통해 이미지를 변환하는 방법, DataLoader를 사용하여 모델에 데이터 배치를 제공하는 방법을 학습합니다.
첫 번째 할 일은 들어오는 이미지를 Pytorch tensor로 변환하는 것입니다.
#%matplotlib inline
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
여기서는 입력에 대한 두 가지 변환을 지정합니다:
``transforms.ToTensor()``는 Pillow 패키지를 사용하여 불러온 이미지를 PyTorch tensor 형태로 변환합니다.
transforms.Normalize()는 tensor의 평균이 0이고 표준 편차가 1.0이되도록 tensor의 값을 조정합니다. 대부분의 활성화 함수는 x = 0 부근에서 강한 기울기 값을 가지고 있어 데이터를 중앙으로 집중화하여 학습 속도를 높일 수 있습니다.
변환(transform)에 전달되는 값들은 각각 데이터셋에 있는 이미지들의 RGB 채널별 평균값(mean)들(첫번째 튜플)과 표준편차(standard deviation)들(두번째 튜플)입니다. 아래 몇 줄의 코드를 실행하여 직접 이 값을 계산해 볼 수 있습니다:
- ```
from torch.utils.data import ConcatDataset transform = transforms.Compose([transforms.ToTensor()]) trainset = torchvision.datasets.CIFAR10(root=’./data’, train=True,
download=True, transform=transform)
#stack all train images together into a tensor of shape #(50000, 3, 32, 32) x = torch.stack([sample[0] for sample in ConcatDataset([trainset])])
#get the mean of each channel mean = torch.mean(x, dim=(0,2,3)) #tensor([0.4914, 0.4822, 0.4465]) std = torch.std(x, dim=(0,2,3)) #tensor([0.2470, 0.2435, 0.2616])
transforms 는 cropping, centering, rotation, reflection를 포함하여 더 많은 변환이 가능합니다.
다음으로 CIFAR10 데이터셋의 인스턴스를 만듭니다. CIFAR10 데이터셋은 동물(새, 고양이, 사슴, 개, 개구리, 말) 6종과 차량(비행기, 자동차, 배, 트럭) 4종의 클래스로 이루어진 데이터셋입니다:
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
0%| | 0.00/170M [00:00<?, ?B/s]
0%| | 32.8k/170M [00:00<13:56, 204kB/s]
0%| | 65.5k/170M [00:00<13:59, 203kB/s]
0%| | 98.3k/170M [00:00<14:37, 194kB/s]
0%| | 197k/170M [00:00<08:02, 353kB/s]
0%| | 295k/170M [00:00<06:27, 439kB/s]
0%| | 360k/170M [00:00<06:34, 431kB/s]
0%| | 492k/170M [00:01<05:09, 550kB/s]
0%| | 590k/170M [00:01<04:59, 568kB/s]
0%| | 688k/170M [00:01<04:51, 582kB/s]
0%| | 786k/170M [00:01<04:46, 592kB/s]
1%| | 918k/170M [00:01<04:17, 658kB/s]
1%| | 1.05M/170M [00:01<04:02, 699kB/s]
1%| | 1.18M/170M [00:02<04:03, 696kB/s]
1%| | 1.31M/170M [00:02<03:52, 729kB/s]
1%| | 1.47M/170M [00:02<03:29, 808kB/s]
1%| | 1.61M/170M [00:02<03:27, 812kB/s]
1%| | 1.77M/170M [00:02<03:14, 868kB/s]
1%| | 1.93M/170M [00:02<03:04, 914kB/s]
1%| | 2.10M/170M [00:03<02:58, 943kB/s]
1%|▏ | 2.29M/170M [00:03<02:44, 1.02MB/s]
1%|▏ | 2.49M/170M [00:03<02:35, 1.08MB/s]
2%|▏ | 2.69M/170M [00:03<02:29, 1.12MB/s]
2%|▏ | 2.88M/170M [00:03<02:11, 1.28MB/s]
2%|▏ | 3.11M/170M [00:03<02:20, 1.19MB/s]
2%|▏ | 3.38M/170M [00:04<02:07, 1.31MB/s]
2%|▏ | 3.60M/170M [00:04<02:04, 1.34MB/s]
2%|▏ | 3.87M/170M [00:04<01:56, 1.42MB/s]
2%|▏ | 4.13M/170M [00:04<01:52, 1.48MB/s]
3%|▎ | 4.42M/170M [00:04<01:44, 1.58MB/s]
3%|▎ | 4.72M/170M [00:04<01:40, 1.65MB/s]
3%|▎ | 5.05M/170M [00:05<01:33, 1.76MB/s]
3%|▎ | 5.37M/170M [00:05<01:29, 1.84MB/s]
3%|▎ | 5.70M/170M [00:05<01:25, 1.92MB/s]
4%|▎ | 6.06M/170M [00:05<01:14, 2.22MB/s]
4%|▍ | 6.46M/170M [00:05<01:19, 2.06MB/s]
4%|▍ | 6.85M/170M [00:05<01:15, 2.16MB/s]
4%|▍ | 7.27M/170M [00:06<01:10, 2.30MB/s]
5%|▍ | 7.73M/170M [00:06<01:06, 2.45MB/s]
5%|▍ | 8.19M/170M [00:06<01:03, 2.56MB/s]
5%|▌ | 8.68M/170M [00:06<00:59, 2.70MB/s]
5%|▌ | 9.18M/170M [00:06<00:51, 3.13MB/s]
6%|▌ | 9.73M/170M [00:06<00:55, 2.90MB/s]
6%|▌ | 10.3M/170M [00:07<00:52, 3.07MB/s]
6%|▋ | 10.9M/170M [00:07<00:49, 3.24MB/s]
7%|▋ | 11.5M/170M [00:07<00:46, 3.42MB/s]
7%|▋ | 12.2M/170M [00:07<00:44, 3.59MB/s]
8%|▊ | 12.8M/170M [00:07<00:41, 3.79MB/s]
8%|▊ | 13.6M/170M [00:07<00:39, 4.00MB/s]
8%|▊ | 14.3M/170M [00:07<00:37, 4.20MB/s]
9%|▉ | 15.1M/170M [00:08<00:35, 4.39MB/s]
9%|▉ | 16.0M/170M [00:08<00:33, 4.63MB/s]
10%|▉ | 16.8M/170M [00:08<00:28, 5.38MB/s]
10%|█ | 17.7M/170M [00:08<00:27, 5.47MB/s]
11%|█ | 18.7M/170M [00:08<00:24, 6.09MB/s]
11%|█▏ | 19.3M/170M [00:08<00:25, 5.81MB/s]
12%|█▏ | 20.0M/170M [00:08<00:28, 5.33MB/s]
12%|█▏ | 20.8M/170M [00:09<00:27, 5.47MB/s]
13%|█▎ | 21.9M/170M [00:09<00:22, 6.59MB/s]
14%|█▎ | 23.0M/170M [00:09<00:19, 7.46MB/s]
14%|█▍ | 23.8M/170M [00:09<00:20, 7.02MB/s]
14%|█▍ | 24.6M/170M [00:09<00:22, 6.42MB/s]
15%|█▌ | 25.6M/170M [00:09<00:21, 6.63MB/s]
16%|█▌ | 26.9M/170M [00:09<00:17, 8.09MB/s]
17%|█▋ | 28.2M/170M [00:09<00:15, 9.16MB/s]
17%|█▋ | 29.2M/170M [00:10<00:17, 8.26MB/s]
18%|█▊ | 30.0M/170M [00:10<00:18, 7.65MB/s]
18%|█▊ | 31.5M/170M [00:10<00:16, 8.19MB/s]
19%|█▉ | 33.1M/170M [00:10<00:13, 9.91MB/s]
20%|██ | 34.4M/170M [00:10<00:12, 10.9MB/s]
21%|██ | 35.6M/170M [00:10<00:13, 9.75MB/s]
22%|██▏ | 36.7M/170M [00:10<00:14, 9.23MB/s]
23%|██▎ | 38.5M/170M [00:11<00:11, 11.4MB/s]
23%|██▎ | 40.0M/170M [00:11<00:10, 12.3MB/s]
24%|██▍ | 41.3M/170M [00:11<00:11, 11.1MB/s]
25%|██▌ | 42.7M/170M [00:11<00:11, 11.0MB/s]
26%|██▋ | 44.8M/170M [00:11<00:09, 13.3MB/s]
27%|██▋ | 46.2M/170M [00:11<00:09, 13.6MB/s]
28%|██▊ | 47.6M/170M [00:11<00:09, 12.4MB/s]
29%|██▉ | 49.6M/170M [00:11<00:09, 13.2MB/s]
31%|███ | 52.1M/170M [00:11<00:07, 15.6MB/s]
32%|███▏ | 53.7M/170M [00:12<00:07, 15.7MB/s]
32%|███▏ | 55.3M/170M [00:12<00:08, 14.3MB/s]
34%|███▍ | 57.7M/170M [00:12<00:07, 15.4MB/s]
36%|███▌ | 60.6M/170M [00:12<00:06, 18.1MB/s]
37%|███▋ | 62.4M/170M [00:12<00:06, 17.9MB/s]
38%|███▊ | 64.2M/170M [00:12<00:06, 16.5MB/s]
39%|███▉ | 67.0M/170M [00:12<00:05, 18.0MB/s]
41%|████ | 70.1M/170M [00:13<00:06, 16.1MB/s]
43%|████▎ | 72.9M/170M [00:13<00:05, 16.4MB/s]
44%|████▍ | 75.8M/170M [00:13<00:05, 16.6MB/s]
46%|████▌ | 78.8M/170M [00:13<00:05, 16.9MB/s]
48%|████▊ | 81.8M/170M [00:13<00:05, 17.0MB/s]
50%|████▉ | 84.7M/170M [00:13<00:05, 17.1MB/s]
51%|█████▏ | 87.7M/170M [00:14<00:04, 17.2MB/s]
53%|█████▎ | 90.5M/170M [00:14<00:04, 17.1MB/s]
55%|█████▍ | 93.6M/170M [00:14<00:04, 17.3MB/s]
57%|█████▋ | 96.5M/170M [00:14<00:04, 17.3MB/s]
58%|█████▊ | 99.3M/170M [00:14<00:04, 17.1MB/s]
60%|█████▉ | 102M/170M [00:14<00:03, 17.2MB/s]
62%|██████▏ | 105M/170M [00:15<00:03, 17.3MB/s]
64%|██████▎ | 108M/170M [00:15<00:03, 17.4MB/s]
65%|██████▌ | 111M/170M [00:15<00:03, 17.3MB/s]
67%|██████▋ | 114M/170M [00:15<00:03, 17.4MB/s]
69%|██████▊ | 117M/170M [00:15<00:03, 17.3MB/s]
70%|███████ | 120M/170M [00:15<00:02, 17.3MB/s]
72%|███████▏ | 123M/170M [00:16<00:02, 17.3MB/s]
74%|███████▍ | 126M/170M [00:16<00:02, 17.4MB/s]
75%|███████▌ | 129M/170M [00:16<00:02, 17.3MB/s]
77%|███████▋ | 132M/170M [00:16<00:02, 17.3MB/s]
79%|███████▉ | 135M/170M [00:16<00:02, 17.3MB/s]
81%|████████ | 138M/170M [00:16<00:01, 17.4MB/s]
82%|████████▏ | 140M/170M [00:17<00:01, 17.4MB/s]
84%|████████▍ | 144M/170M [00:17<00:01, 17.5MB/s]
86%|████████▌ | 146M/170M [00:17<00:01, 17.3MB/s]
88%|████████▊ | 149M/170M [00:17<00:01, 17.1MB/s]
89%|████████▉ | 152M/170M [00:17<00:01, 17.1MB/s]
91%|█████████ | 155M/170M [00:17<00:00, 17.1MB/s]
93%|█████████▎| 158M/170M [00:18<00:00, 17.1MB/s]
94%|█████████▍| 161M/170M [00:18<00:00, 17.2MB/s]
96%|█████████▌| 164M/170M [00:18<00:00, 17.3MB/s]
98%|█████████▊| 167M/170M [00:18<00:00, 17.3MB/s]
99%|█████████▉| 170M/170M [00:18<00:00, 17.2MB/s]
100%|██████████| 170M/170M [00:18<00:00, 9.05MB/s]
PyTorch에서 데이터셋 객체를 만드는 예제입니다. 다운로드 가능한 데이터셋
(CIFAR-10과 같은)는 torch.utils.data.Dataset 의 하위 클래스입니다.
PyTorch의 Dataset 클래스에는 TorchVision, Torchtext 및 TorchAudio 등
다운로드 가능한 데이터셋 뿐 아니라 레이블된 이미지의 폴더를 읽는
torchvision.datasets.ImageFolder 와 같은 유틸리티 데이터셋 클래스가
포함됩니다. 또한, Dataset 의 하위 클래스를 직접 만들 수 있습니다.
데이터셋을 인스턴스화할 때 몇 가지 파라미터를 선언해야 합니다.
데이터를 저장하려는 파일 시스템 경로입니다.
데이터셋을 학습에 사용하는지 여부를 확인하여 대부분의 데이터셋은 학습 및 테스트 데이터셋으로 분할됩니다.
데이터셋을 다운로드할지에 대한 여부를 확인합니다.
데이터에 적용하려는 변환 객체를 넣어줍니다.
데이터셋 다운로드가 끝나면 ``DataLoader``에 사용할 수 있습니다:
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
Dataset 하위 클래스는 데이터 접근에 대한 클래스를 포함하며, 해당 서브
클래스가 제공하는 데이터 유형에 특화되어 있습니다.
DataLoader 는 데이터에 대해 아무것도 알지 못하지만
Dataset 이 제공하는 입력 tensor를 사용자가 지정한 파라미터로 구성합니다.
위 예제에서 DataLoader 에서에서 무작위 추출( shuffle=True )한 4개의
batch 이미지를 trainset 에서 추출하고 disk에서 데이터를 로드하기
위해 2개의 workers를 spin up 했습니다.
DataLoader 가 제공하는 batch 이미지를 시각화 하는것은 좋은 연습입니다:
import matplotlib.pyplot as plt
import numpy as np
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
img = img / 2 + 0.5 # 역정규화
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# 무작위로 학습 이미지 추출하기
dataiter = iter(trainloader)
images, labels = next(dataiter)
# 이미지 보여주기
imshow(torchvision.utils.make_grid(images))
# labels 출력하기
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-0.49473685..1.5632443].
ship car horse ship
위 셀 스크립트를 실행하면 4개의 이미지와 각 이미지에 대한 정답 label이 출력됩니다.
PyTorch 모델 학습#
17:10 에 시작하는 영상을 참고하세요.
위에서 다뤘던 내용들을 종합하여 모델을 학습시키겠습니다:
#%matplotlib inline
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
첫째로, 학습 및 테스트 데이터셋이 필요합니다. 아직 다운로드하지 않은 경우, 아래 셀을 실행하여 데이터셋이 다운로드 되었는지 확인하세요.(다운로드 시 수 분정도 소요됩니다)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
DataLoader 출력을 확인해보겠습니다:
import matplotlib.pyplot as plt
import numpy as np
# 아래 함수는 이미지를 시각화하여 보여주는 함수입니다.
def imshow(img):
img = img / 2 + 0.5 # 역정규화
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# 무작위로 학습 이미지를 가져오기
dataiter = iter(trainloader)
images, labels = next(dataiter)
# 이미지 시각화하기
imshow(torchvision.utils.make_grid(images))
# 정답 label 출력하기
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

cat cat deer frog
이제 모델을 학습시킬 차례입니다. 만약 모델 구조가 익숙하게 보인다면, 이 모델은 이번 영상에서 앞서 다뤄진 3채널(color) 이미지에 맞게 변형된 LeNet 모델이기 때문입니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
아래는 마지막으로 학습에 필요한 손실 함수 및 최적화 방법입니다.
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
손실 함수(loss function)는 데이터 기반으로 모델이 예측한 정답 값이 얼마나 차이가 나는지를 표현하는 지표입니다. Cross-entropy 손실 함수는 일반적인 분류 모델의 전형적인 손실 함수입니다.
optimizer 는 학습의 필수요소입니다. 아래 예제에서 간단한 최적화 알고리즘인
stochastic gradient descent 를 구현하겠습니다. SGD 알고리즘은 학습 속도인
(lr) 및 momentum 과 같은 매개 변수 외에도 모델의 모든 학습 가중치 값인
net.parameters() 를 전달하는데, 이 함수는 최적화를 위해 파라미터를 조정합니다.
마지막으로, 모든 것이 학습 loop에 들어갑니다. 이제 아래 셀을 실행하세요. 실행 시 몇 분 정도 걸릴 수 있습니다:
for epoch in range(2): # 데이터셋을 여러 번 반복 학습합니다.
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 데이터를 통해 이미지와 정답값을 받습니다.
inputs, labels = data
# 초기 기울기 파라미터를 0으로 설정합니다
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# epoch 및 loss 값을 출력합니다
running_loss += loss.item()
if i % 2000 == 1999: # 2000 mini-batches 마다 값을 출력합니다
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
[1, 2000] loss: 2.195
[1, 4000] loss: 1.878
[1, 6000] loss: 1.657
[1, 8000] loss: 1.577
[1, 10000] loss: 1.518
[1, 12000] loss: 1.460
[2, 2000] loss: 1.416
[2, 4000] loss: 1.366
[2, 6000] loss: 1.330
[2, 8000] loss: 1.328
[2, 10000] loss: 1.316
[2, 12000] loss: 1.256
Finished Training
이 예제에서 학습 에폭 2번 만 반복합니다(1번째 ) - 즉, 학습 데이터셋을 두 번 모델에 통과시킵니다. 각 패스에는 iterates over the training data (4번째 라인)의 내부 루프가 있어 변환된 입력 이미지의 batch와 올바른 레이블을 제공합니다.
기울기 값 초기화 (9번째 라인) 은 중요한 단계입니다. 기울기는 batch에 걸쳐 누적됩니다. 모든 batch에 대해 기울기 값을 재설정하지 않으면 기울기 값이 계속 누적되어 잘못된 기울기 값을 제공하여 학습이 불가능합니다.
12번째 라인에서는 batch 데이터를 모델에게 예측을 요청 합니다. 다음 13번째라인에서 모델의 결과 값과 정답 값 차이인 손실값을 계산합니다.
14번째 라인에서는 backward() 를 통해 모델의 학습 기울기를 계산합니다.
15번째 라인에서는 학습 단계의 최적화를 수행하는데 backward()
를 통해 손실 값을 줄일 수 있는 방향으로 학습 가중치들을 조정합니다.
루프의 나머지 부분은 epoch 횟수, 학습 루프를 통해 수집된 손실 값을 출력합니다.
위 셀을 실행하면 다음과 같은 출력이 나타날 것입니다:
[1, 2000] loss: 2.235
[1, 4000] loss: 1.940
[1, 6000] loss: 1.713
[1, 8000] loss: 1.573
[1, 10000] loss: 1.507
[1, 12000] loss: 1.442
[2, 2000] loss: 1.378
[2, 4000] loss: 1.364
[2, 6000] loss: 1.349
[2, 8000] loss: 1.319
[2, 10000] loss: 1.284
[2, 12000] loss: 1.267
Finished Training
손실 값은 단조롭게 감소하며, 이는 모델이 훈련 데이터셋에서 성능을 계속 향상시키고 있음을 보여줍니다.
마지막 단계로 모델이 단순하게 학습 데이터셋을 “기억” 하는 것이 아니라 실제로 일반화 학습을 잘 수행하고 있는 확인해야 합니다. 이를 과적합 이라 부르며 일반적으로 데이터셋이 너무 작거나, 모델이 데이터셋 을 올바르게 모델링하는 데 필요한 것보다 더 많은 학습 파라미터 변수를 가지고 있음을 보여줍니다. (일반적인 학습에 충분한 예제가 아닙니다)
위와 같이 데이터셋이 학습 및 테스트 데이터셋으로 분할되는 이유입니다. 모델의 일반성을 테스트하기 위해 학습되지 않은 데이터에 대해 예측하도록 요청합니다:
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('10000개 테스트 이미지에서 모델 정확도: %d %%' % (
100 * correct / total))
10000개 테스트 이미지에서 모델 정확도: 54 %
위 내용을 잘 실습하셨다면 모델의 정확도가 약 50% 정도 나온다는 것을 확인 할 수 있습니다. 이것은 정확히 최신 기술은 아니지만, 무작위 결과에서 기대할 수 있는 정확도 보다 10% 정도 좋은 결과를 보여줍니다. 이 결과는 모델에서 일반적인 학습이 발생했음을 보여줍니다.
Total running time of the script: (4 minutes 54.425 seconds)
