


참고
Go to the end to download the full example code.
텐서보드를 이용한 파이토치 프로파일러#
번역: 손동우
이 튜토리얼에서는 파이토치(PyTorch) 프로파일러(profiler)와 함께 텐서보드(TensorBoard) 플러그인(plugin)을 사용하여 모델의 성능 병목 현상을 탐지하는 방법을 보여 줍니다.
경고
TensorBoard와 PyTorch 프로파일러의 통합은 이제 더 이상 사용되지 않습니다.
대신 Perfetto 또는 Chrome 트레이스를 사용하여 trace.json 파일을 볼 수 있습니다.
트레이스 생성 후,
trace.json 파일을 Perfetto UI 또는 chrome://tracing 에 드래그하여 프로파일을 시각화할 수 있습니다.
소개#
파이토치(PyTorch) 1.8부터 GPU에서 CUDA 커널(kernel) 실행 뿐만 아니라 CPU 작업을 기록할 수 있는 업데이트된 프로파일러 API가 포함되어 있습니다. 프로파일러는 텐서보드 플러그인에서 이런 정보를 시각화하고 성능 병목 현상에 대한 분석을 제공할 수 있습니다.
이 튜토리얼에서는 간단한 Resnet 모델을 사용하여 텐서보드 플러그인을 활용한 모델 성능 분석 방법을 보여드리겠습니다.
준비#
아래 명령어를 실행하여 ``torch``와 ``torchvision``을 설치합니다:
pip install torch torchvision
과정#
데이터 및 모델 준비
프로파일러를 사용하여 실행 이벤트(execution events) 기록
프로파일러 실행
텐서보드를 사용하여 결과 확인 및 모델 성능 분석
프로파일러의 도움으로 성능 개선
다른 고급 기능으로 성능 분석
추가 연습: AMD GPU에서 PyTorch 프로파일링
1. 데이터 및 모델 준비#
먼저 필요한 라이브러리를 모두 불러옵니다:
import torch
import torch.nn
import torch.optim
import torch.profiler
import torch.utils.data
import torchvision.datasets
import torchvision.models
import torchvision.transforms as T
이후 입력 데이터를 준비합니다. 이 튜토리얼의 경우 CIFAR10 데이터셋을 사용합니다. 원하는 형식으로 변환하고 ``DataLoader``를 사용하여 각 배치(batch)를 로드합니다.
transform = T.Compose(
[T.Resize(224),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True)
0%| | 0.00/170M [00:00<?, ?B/s]
0%| | 32.8k/170M [00:00<14:23, 197kB/s]
0%| | 65.5k/170M [00:00<14:23, 197kB/s]
0%| | 98.3k/170M [00:00<14:18, 199kB/s]
0%| | 229k/170M [00:00<06:33, 432kB/s]
0%| | 459k/170M [00:00<03:39, 775kB/s]
1%| | 918k/170M [00:00<01:57, 1.45MB/s]
1%| | 1.84M/170M [00:01<01:00, 2.78MB/s]
2%|▏ | 3.70M/170M [00:01<00:30, 5.47MB/s]
4%|▍ | 7.14M/170M [00:01<00:16, 9.93MB/s]
6%|▌ | 10.0M/170M [00:01<00:13, 12.1MB/s]
8%|▊ | 13.1M/170M [00:01<00:11, 13.8MB/s]
9%|▉ | 16.0M/170M [00:02<00:10, 14.9MB/s]
11%|█ | 18.8M/170M [00:02<00:09, 15.5MB/s]
13%|█▎ | 21.8M/170M [00:02<00:09, 16.1MB/s]
14%|█▍ | 24.7M/170M [00:02<00:08, 16.2MB/s]
16%|█▋ | 27.8M/170M [00:02<00:08, 16.7MB/s]
18%|█▊ | 30.7M/170M [00:02<00:08, 16.9MB/s]
20%|█▉ | 33.7M/170M [00:03<00:07, 17.1MB/s]
22%|██▏ | 36.7M/170M [00:03<00:07, 17.2MB/s]
23%|██▎ | 39.6M/170M [00:03<00:07, 17.2MB/s]
25%|██▍ | 42.4M/170M [00:03<00:07, 17.1MB/s]
27%|██▋ | 45.3M/170M [00:03<00:07, 16.5MB/s]
28%|██▊ | 48.3M/170M [00:03<00:07, 16.7MB/s]
30%|███ | 51.2M/170M [00:04<00:07, 16.8MB/s]
32%|███▏ | 54.1M/170M [00:04<00:06, 16.9MB/s]
33%|███▎ | 57.0M/170M [00:04<00:06, 17.0MB/s]
35%|███▌ | 60.1M/170M [00:04<00:06, 17.2MB/s]
37%|███▋ | 63.0M/170M [00:04<00:06, 17.1MB/s]
39%|███▉ | 66.1M/170M [00:04<00:06, 17.2MB/s]
41%|████ | 69.2M/170M [00:05<00:05, 17.3MB/s]
42%|████▏ | 72.2M/170M [00:05<00:05, 17.3MB/s]
44%|████▍ | 75.2M/170M [00:05<00:05, 17.3MB/s]
46%|████▌ | 78.0M/170M [00:05<00:05, 17.1MB/s]
47%|████▋ | 81.0M/170M [00:05<00:05, 17.2MB/s]
49%|████▉ | 84.0M/170M [00:05<00:05, 17.2MB/s]
51%|█████ | 87.0M/170M [00:06<00:04, 17.2MB/s]
53%|█████▎ | 89.9M/170M [00:06<00:04, 17.2MB/s]
54%|█████▍ | 92.8M/170M [00:06<00:04, 17.2MB/s]
56%|█████▌ | 95.7M/170M [00:06<00:04, 17.1MB/s]
58%|█████▊ | 98.5M/170M [00:06<00:04, 17.0MB/s]
59%|█████▉ | 101M/170M [00:07<00:04, 17.0MB/s]
61%|██████ | 104M/170M [00:07<00:03, 17.1MB/s]
63%|██████▎ | 107M/170M [00:07<00:03, 17.0MB/s]
65%|██████▍ | 110M/170M [00:07<00:03, 17.2MB/s]
66%|██████▋ | 113M/170M [00:07<00:03, 17.2MB/s]
68%|██████▊ | 116M/170M [00:07<00:03, 17.1MB/s]
70%|██████▉ | 119M/170M [00:08<00:02, 17.1MB/s]
72%|███████▏ | 122M/170M [00:08<00:02, 17.1MB/s]
73%|███████▎ | 125M/170M [00:08<00:02, 17.2MB/s]
75%|███████▌ | 128M/170M [00:08<00:02, 17.2MB/s]
77%|███████▋ | 131M/170M [00:08<00:02, 17.0MB/s]
78%|███████▊ | 134M/170M [00:08<00:02, 17.0MB/s]
80%|████████ | 137M/170M [00:09<00:01, 17.0MB/s]
82%|████████▏ | 140M/170M [00:09<00:01, 17.0MB/s]
84%|████████▎ | 143M/170M [00:09<00:01, 17.1MB/s]
85%|████████▌ | 146M/170M [00:09<00:01, 17.3MB/s]
87%|████████▋ | 148M/170M [00:09<00:01, 17.1MB/s]
89%|████████▉ | 151M/170M [00:09<00:01, 17.2MB/s]
91%|█████████ | 154M/170M [00:10<00:00, 17.2MB/s]
92%|█████████▏| 157M/170M [00:10<00:00, 17.1MB/s]
94%|█████████▍| 160M/170M [00:10<00:00, 17.0MB/s]
96%|█████████▌| 163M/170M [00:10<00:00, 16.9MB/s]
97%|█████████▋| 166M/170M [00:10<00:00, 16.9MB/s]
99%|█████████▉| 169M/170M [00:10<00:00, 17.0MB/s]
100%|██████████| 170M/170M [00:10<00:00, 15.5MB/s]
그런 다음 Resnet 모델, 손실 함수 및 옵티마이저 객체를 생성합니다. GPU에서 실행하기 위해 모델 및 손실을 GPU 장치로 이동합니다.
device = torch.device("cuda:0")
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
criterion = torch.nn.CrossEntropyLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
각 입력 데이터 배치에 대한 학습 단계를 정의합니다.
def train(data):
inputs, labels = data[0].to(device=device), data[1].to(device=device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
2. 프로파일러를 사용하여 실행 이벤트 기록#
프로파일러는 컨텍스트(context) 관리자를 통해 활성화되고 몇 가지 매개변수를 사용할 수 있으며, 가장 유용한 것은 아래와 같습니다:
schedule- step (int)을 단일 매개변수로 받아들이고, 각 단계에서 수행할 프로파일러 작업을 반환하는 호출 가능한 함수입니다.이 예시에서는
wait=1, warmup=1, active=3, repeat=1로 설정되어 있으며, 프로파일러는 첫 번째 단계/반복(step/iteration)을 건너뜁니다. 두 번째부터 워밍업(warming up)을 시작하면, 다음 세 번의 반복을 기록하고, 그 후 추적(trace)을 사용할 수 있게 되고 on_trace_ready (설정된 경우)가 호출됩니다. 전체적으로 이 주기가 한 번 반복됩니다. 텐서보드 플러그인에서 각 주기는 “span”이라고 합니다.wait단계인 동안 프로파일러는 비활성화됩니다.warmup단계인 동안엔 프로파일러가 추적(tracing)을 시작하지만 결과는 무시됩니다. 이는 프로파일링 과부하(overhead)를 줄이기 위함입니다. 프로파일링을 시작할 때 과부하는 크고 프로파일링 결과에 왜곡을 가져오기 쉽습니다.active단계에선 프로파일러가 작동하며 이벤트를 기록합니다.on_trace_ready- 각 주기 마지막에 호출되는 함수입니다; 이 예시에서는torch.profiler.tensorboard_trace_handler``를 사용하여 텐서보드의 결과 파일을 생성합니다. 프로파일링 후 결과 파일은 ``./log/resnet18디렉토리에 저장됩니다. 텐서보드에서 프로파일(profile)을 분석하려면 이 디렉토리를logdir매개변수로 지정해야 합니다.record_shapes- 연산자 입력의 shape을 기록할지 여부를 나타냅니다.profile_memory- Track tensor memory 할당/할당 해제 여부를 나타냅니다. 주의, 1.10 이전 버전의 파이토치를 사용하는 경우 프로파일링 시간이 길다면 이 기능을 비활성화하거나 새 버전으로 업그레이드해 주세요.with_stack- ops에 대한 소스 정보(파일 및 라인 번호)를 기록 여부를 나타냅니다. 만약 VS Code에서 텐서보드를 실행하는 경우 (참고), 스택 프레임(stack frame)을 클릭하면 특정 코드 라인으로 이동합니다.
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, batch_data in enumerate(train_loader):
prof.step() # 각 단계에서 호출하여 프로파일러에게 단계의 경계를 알려야 합니다.
if step >= 1 + 1 + 3:
break
train(batch_data)
또한, 다음의 non-context 관리자(manager)는 시작(start)/정지(stop) 기능도 지원됩니다.
prof = torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),
record_shapes=True,
with_stack=True)
prof.start()
for step, batch_data in enumerate(train_loader):
prof.step()
if step >= 1 + 1 + 3:
break
train(batch_data)
prof.stop()
3. 프로파일러 실행#
위 코드를 실행합니다. 프로파일링 결과는 ./log/resnet18 디렉토리에 저장됩니다.
4. 텐서보드를 사용하여 결과 확인 및 모델 성능 분석#
참고
텐서보드 플러그인(Tensorboard Plugin) 지원이 중단되었으므로, 아래 기능들 중 일부는 이전처럼 동작하지 않을 수 있습니다. 이에 대한 대안으로 HTA 를 사용할 수 있습니다.
파이토치 프로파일러 텐서보드 플러그인을 설치합니다.
pip install torch_tb_profiler
텐서보드를 실행합니다.
tensorboard --logdir=./log
구글 크롬(Google Chrome) 브라우저 또는 마이크로소프트 엣지(Microsoft Edge) 브라우저에서 텐서보드 프로파일(profile) URL에 접속합니다. (Safari 브라우저는 지원하지 않습니다.)
http://localhost:6006/#pytorch_profiler
아래와 같이 프로파일러 플러그인 페이지를 볼 수 있습니다.
개요(Overview)
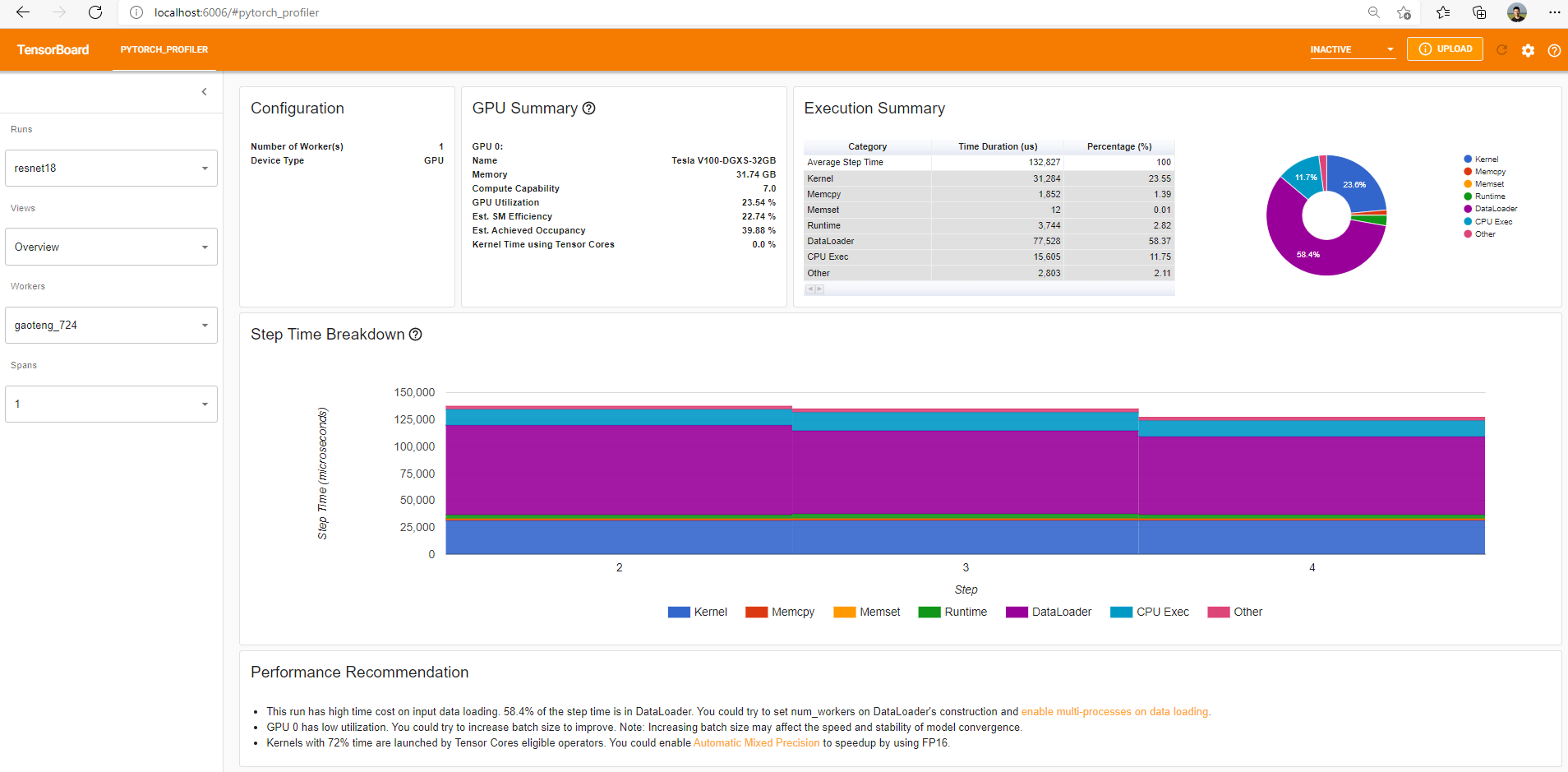
개요 페이지에는 모델 성능에 대한 대략적인 요약이 표시됩니다.
“GPU 요약(GPU Summary)” 패널에는 GPU 구성, GPU 사용량 및 Tensor 코어 사용량이 표시됩니다. 이 예제에서는 GPU 사용량이 낮습니다. 이러한 측정 지표(metrics)에 대한 자세한 내용은 여기 에서 확인해주세요.
“단계 시간 세분화(Step Time Breakdown)”는 각 단계에서 수행된 시간의 분포를 보여줍니다.
이 예제에서는 DataLoader 과부하가 상당한 것을 볼 수 있습니다.
하단의 “성능 권장사항(Performance Recommendation)”은 프로파일링 데이터를 사용하여 발생 가능한 병목 현상을 자동으로 강조하고, 실행 가능한 최적화 제안을 제공합니다.
왼쪽 “보기(Views)” 드롭다운(dropdown) 목록에서 보기 페이지를 변경할 수 있습니다.
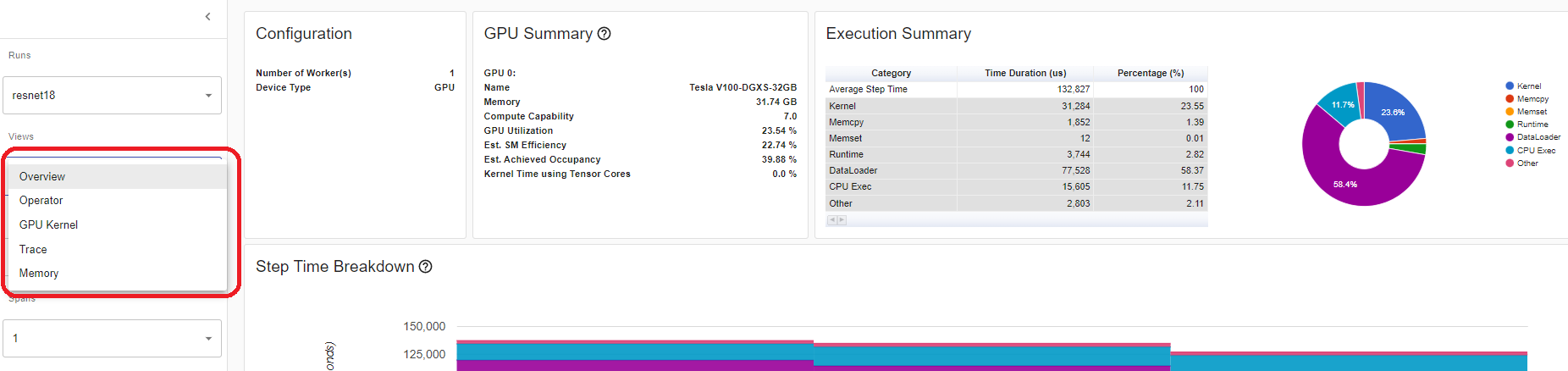
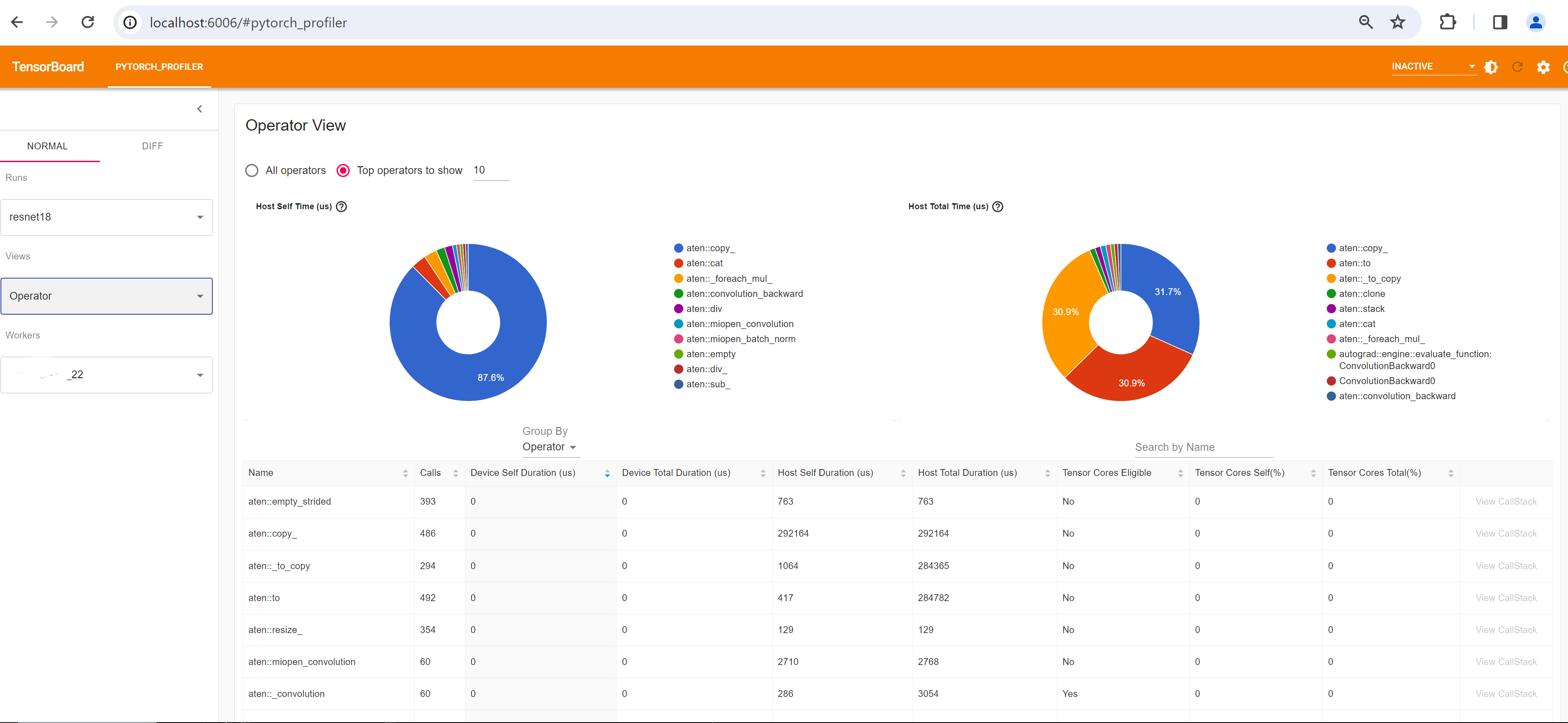
연산 보기(Operator view)
연산 보기는 호스트 또는 장치에서 실행되는 모든 파이토치 연산자의 성능을 표시합니다.
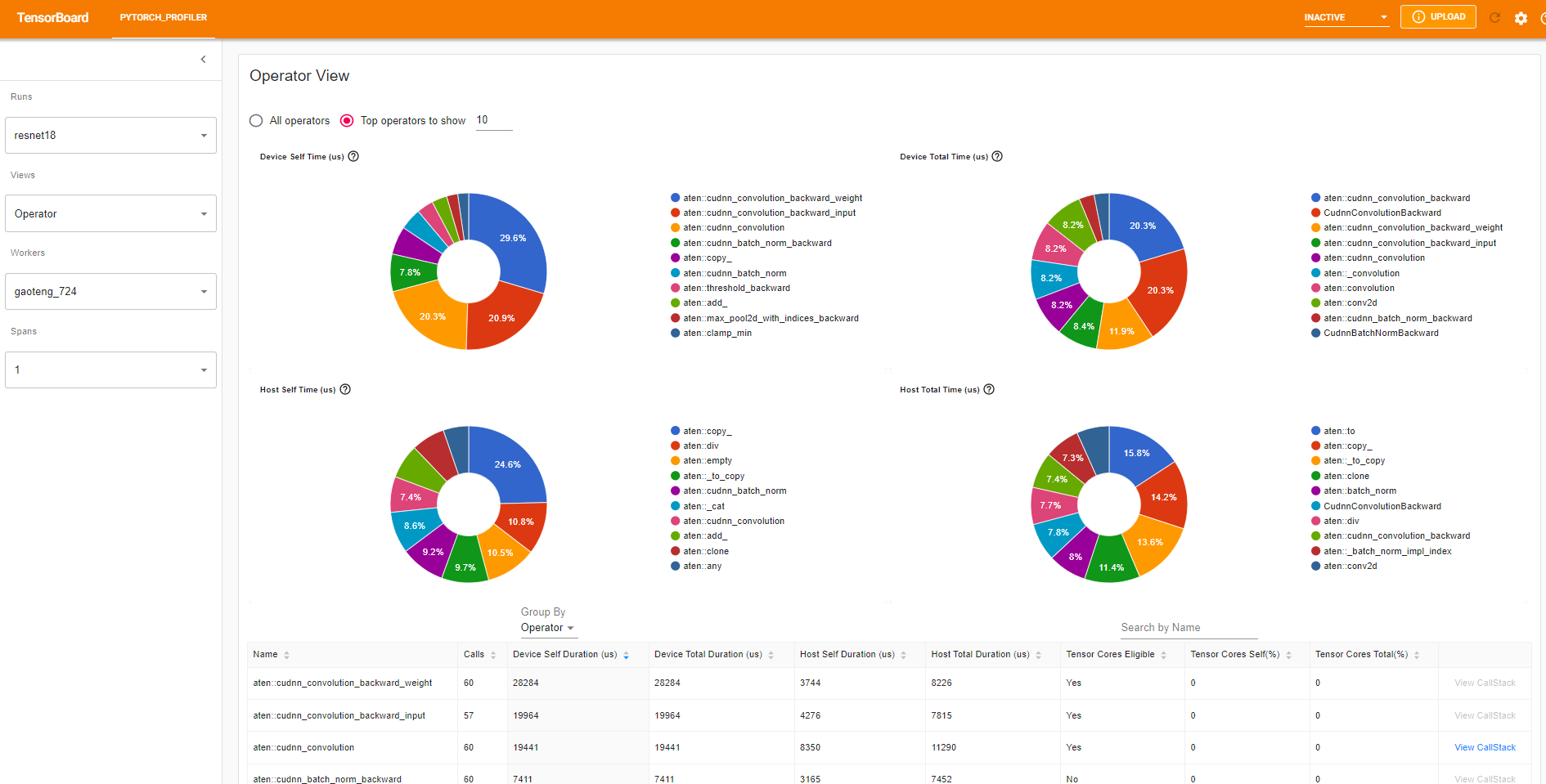
“셀프(Self)” 기간에는 하위 연산의 시간이 포함되지 않습니다. “전체(Total)” 기간에는 하위 연산의 시간이 포함됩니다.
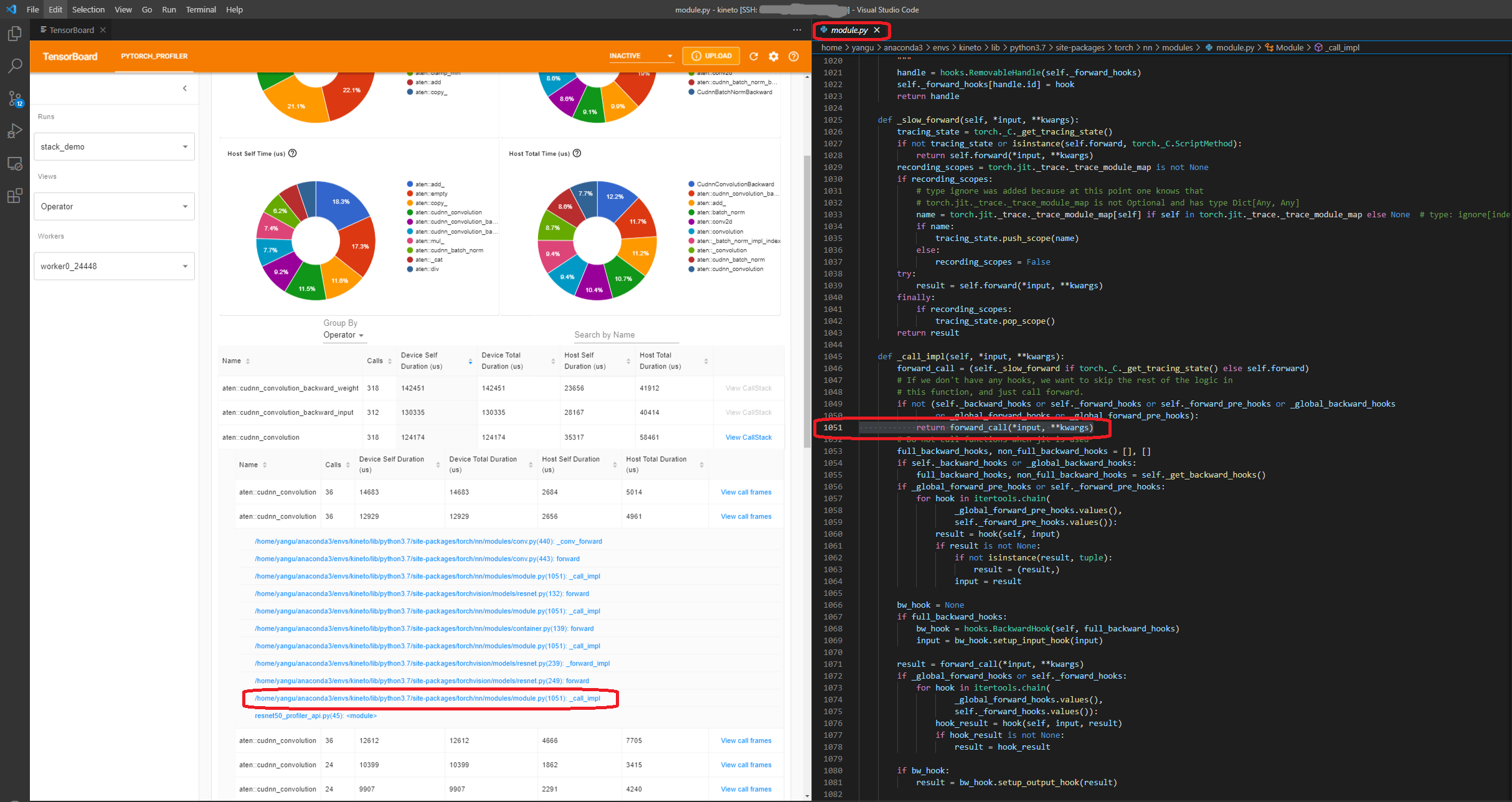
호출 스택 보기(View call stack)
연산자의 ``View Callstack``를 클릭하면, 이름은 같지만 서로 다른 연산자가 표시됩니다. 하위 테이블의 ``View Callstack``를 클릭하면, 호출 스택 프레임(call stack frames)이 표시됩니다.
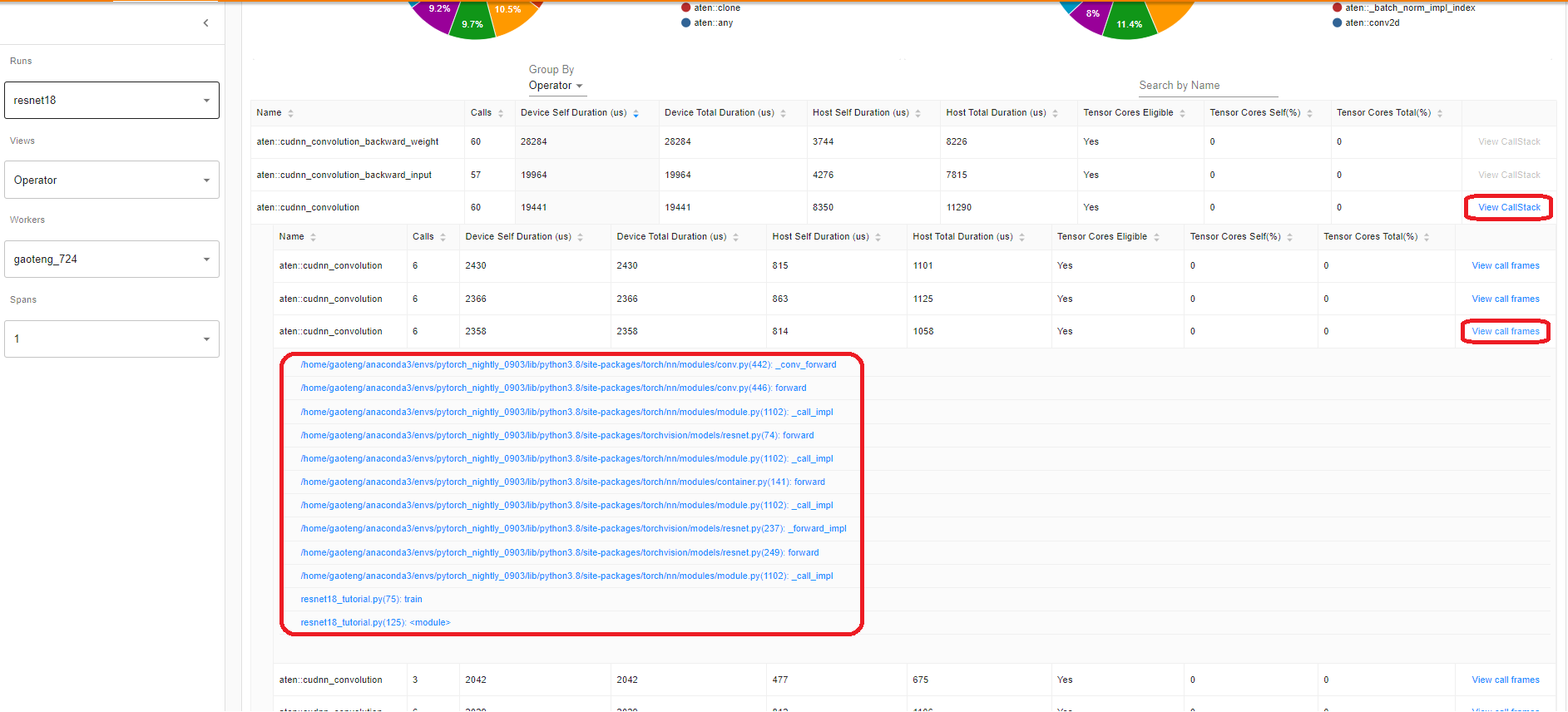
VS Code 내부에서 텐서보드가 실행되는 경우 (실행 가이드), 호출 스택 프레임(call stack frame)을 클릭하면 특정 코드 라인으로 이동합니다.
커널 보기(Kernel view)
GPU 커널 보기(GPU kernel view)는 모든 커널(kernel)이 GPU에 소비한 시간을 보여줍니다.
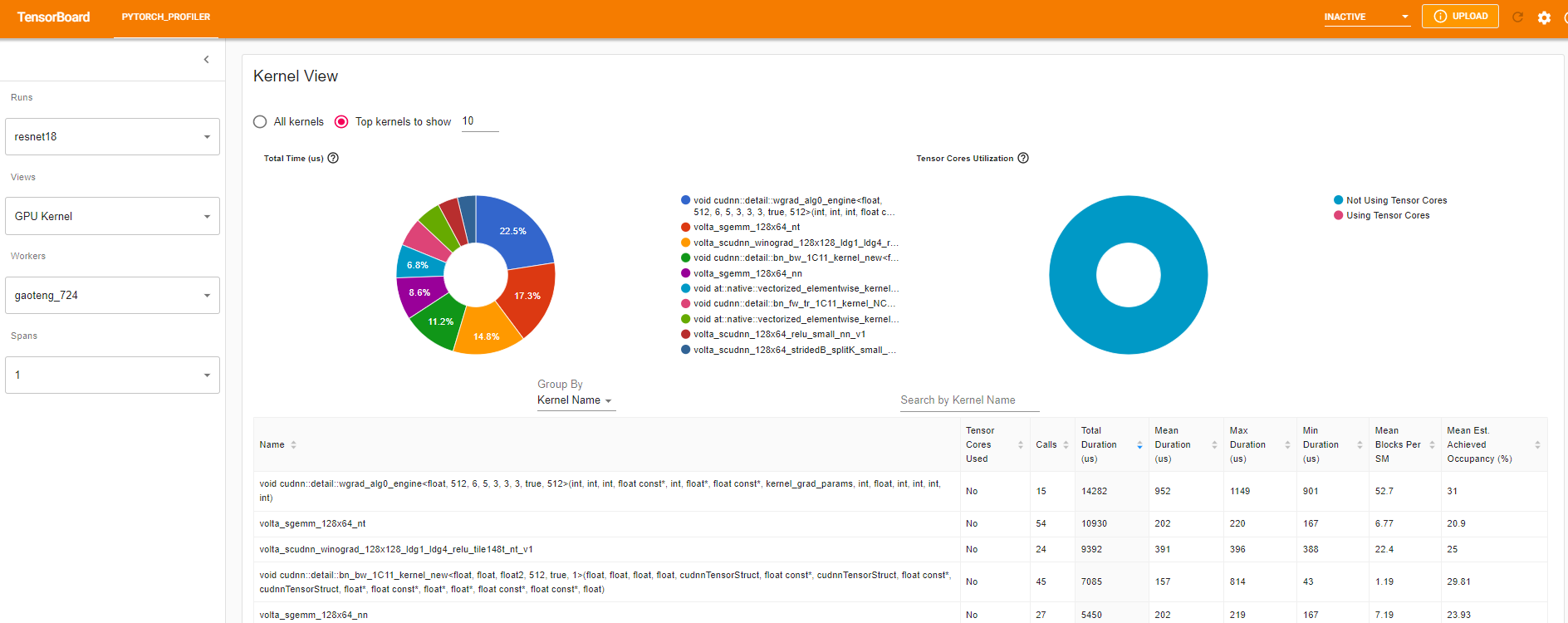
사용된 Tensor 코어: 이 커널(kernel)이 tensor 코어를 사용하는지 여부룰 나타냅니다.
SM당 평균 블럭 수: SM당 블럭 수 = 커널(kernel)의 블럭 / GPU의 SM 수. 이 수치가 1보다 작으면 GPU 멀티프로세서가 완전히 사용되지 않음을 나타냅니다. “SM당 평균 블럭 수(Mean Blocks per SM)”는 이 커널 이름의 모든 실행에 대한 가중 평균이고, 각 실행 기간을 가중치로 사용하였습니다.
평균 예상 달성 점유율(Mean Est. Achieved Occupancy): 예상 달성 점유율(Est. Achieved Occupancy)은 열의 툴팁(column’s tooltip)에 정의되어 있습니다. 메모리 대역폭 경계 커널과 같은 대부분의 경우, 높을수록 좋습니다. “평균 예상 달성 점유율(Mean Est. Achieved Occupancy)”은 커널 이름의 모든 실행에 대한 가중 평균이며, 각 실행의 지속 시간을 가중치로 사용합니다.
추적 보기(Trace view)
추적 보기는 프로파일된 연산자와 GPU 커널의 타임라인을 보여줍니다. 아래와 같이 선택하여 세부 정보를 확인할 수 있습니다.
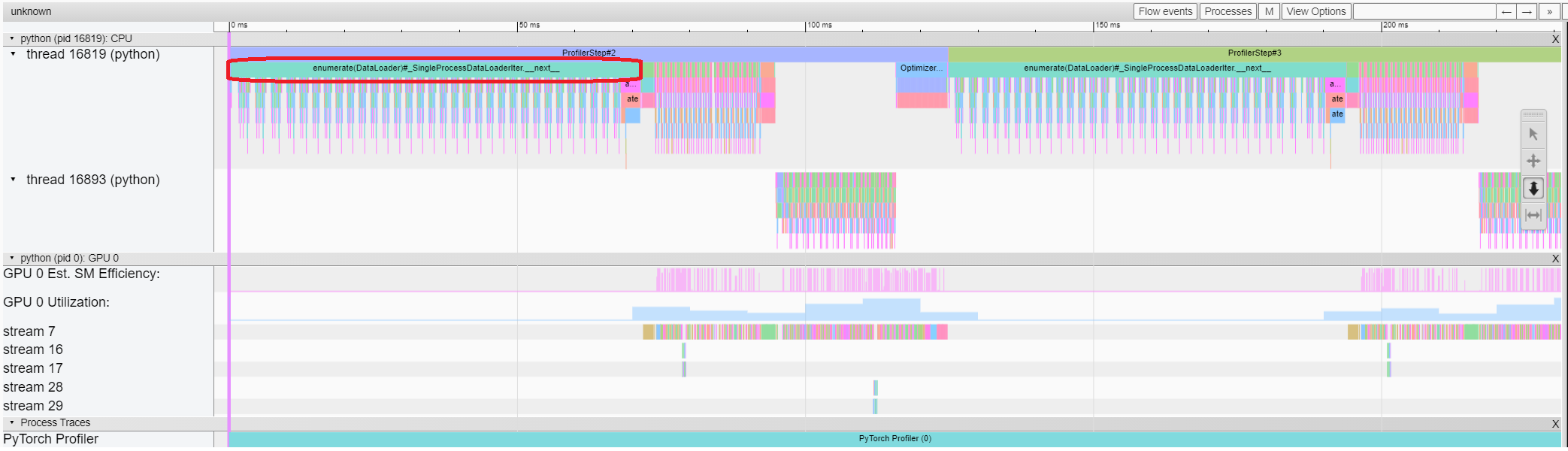
오른쪽 도구 모음을 사용하여 그래프를 이동하고 확대/축소할 수 있습니다. 또한 키보드를 사용하여 타임라인 안에서 확대/이동할 수 있습니다. ‘w’및 ‘s’ 키는 마우스 중심으로 확대되며, ‘a’와 ‘d’ 키는 타임라인을 좌우로 이동합니다. 읽을 수 있는 표현이 보일 때까지 이 키를 여러 번 누를 수 있습니다.
역방향 연산자(backward operator)의 “Incoming Flow” 필드가 “forward correspond to backward” 값인 경우, 텍스트를 클릭하여 시작되는 전진 연산자(forward operator)를 가져올 수 있습니다.
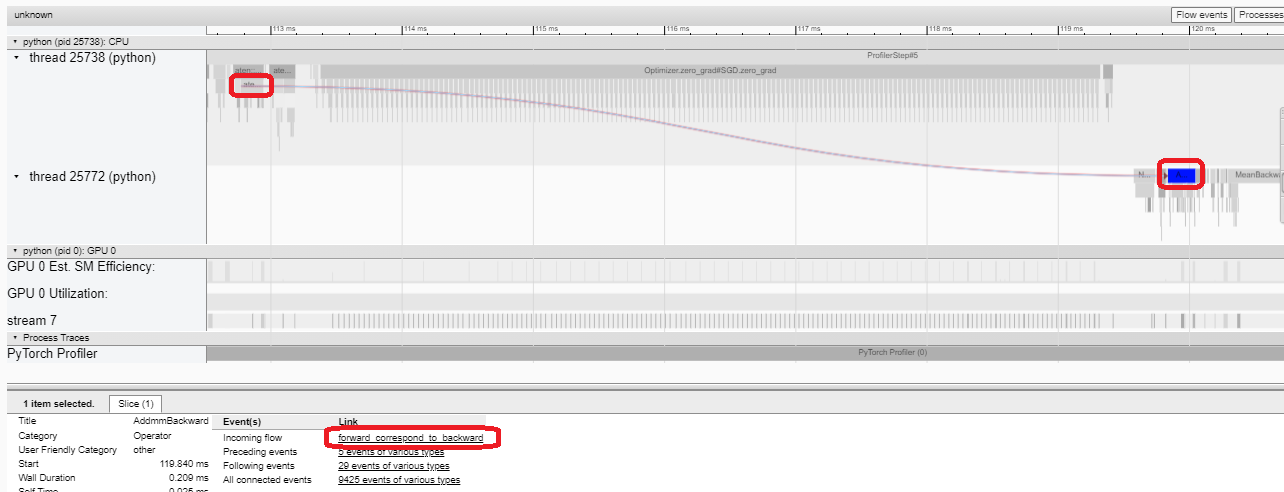
이 예시에서는 ``enumerate(DataLoader)``로 접두사가 붙은 이벤트에 많은 시간이 소요되는 것을 확인할 수 있습니다. 그리고 대부분의 기간 동안 GPU는 쉬는 상태입니다. 이 기능은 호스트 측에서 데이터를 로드하고 데이터를 변환하는 기능이기 때문에, GPU 리소스가 낭비됩니다.
5. 프로파일러의 도움으로 성능 개선#
“개요(Overview)” 페이지 하단의 “성능 추천(Performance Recommendation)” 제안은 병목 현상이 “ ``DataLoader``임을 암시합니다. 파이토치 ``DataLoader``는 기본적으로 단일 프로세스를 사용합니다. 사용자는 매개변수 ``num_workers``를 설정하여 다중 프로세스 데이터 로드를 활성화할 수 있습니다. 자세한 내용은 여기 에 있습니다.
이 예시에서 “성능 권장사항(Performance Recommendation)”에 따라 아래와 같이 ``num_workers``를 설정하고, ``./log/resnet18_4workers``와 같은 다른 이름을 ``tensorboard_trace_handler``로 전달한 후 다시 실행합니다.
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=4)
그런 다음 왼쪽 “실행(Runs)” 드롭다운(dropdown) 목록에서 최근 프로파일된 실행을 선택합니다.
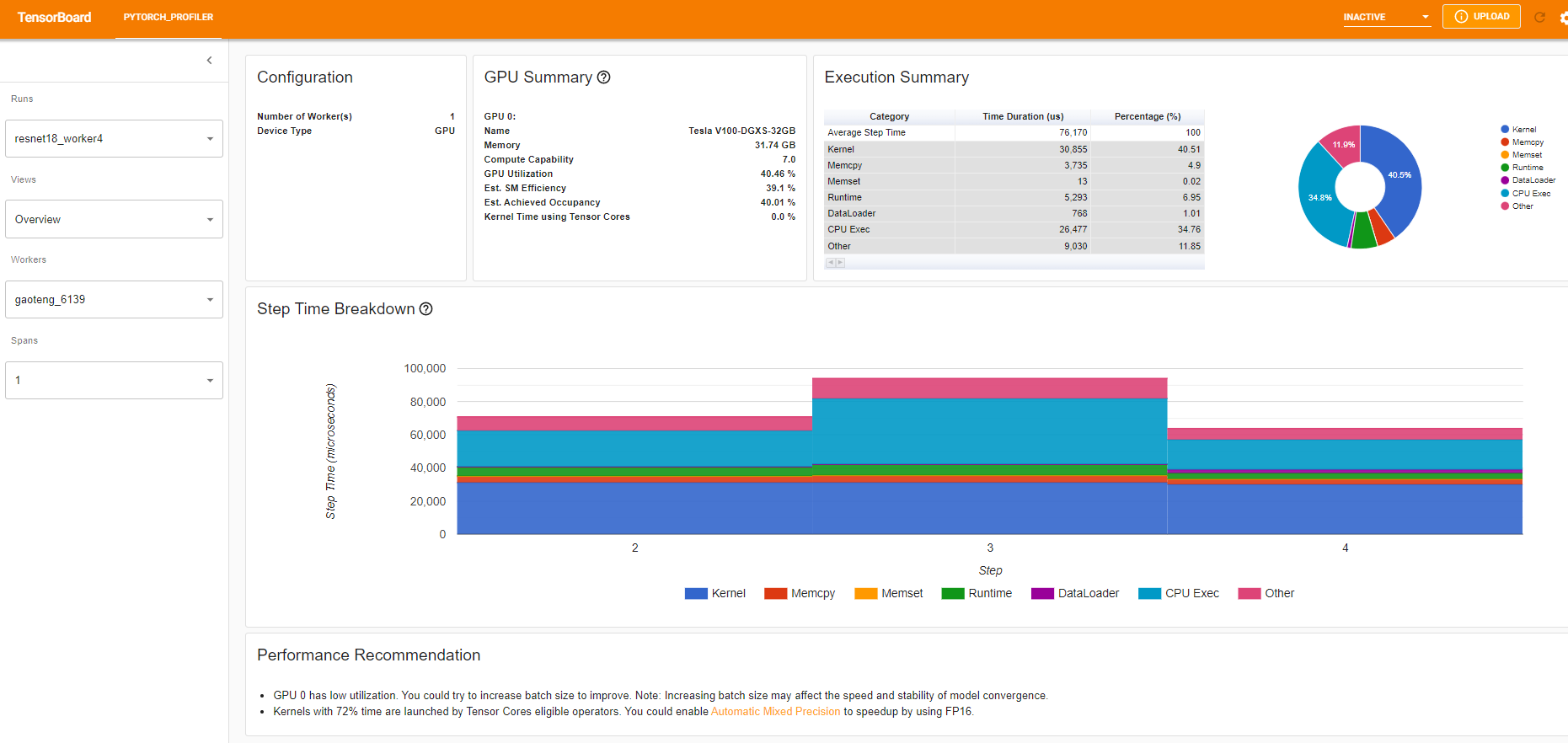
위의 보기(view)에서 이전 실행인 132ms에 비해 단계(step) 시간이 약 76ms로 감소하고, ``DataLoader``의 시간 감소가 주로 기여한다는 것을 알 수 있습니다.
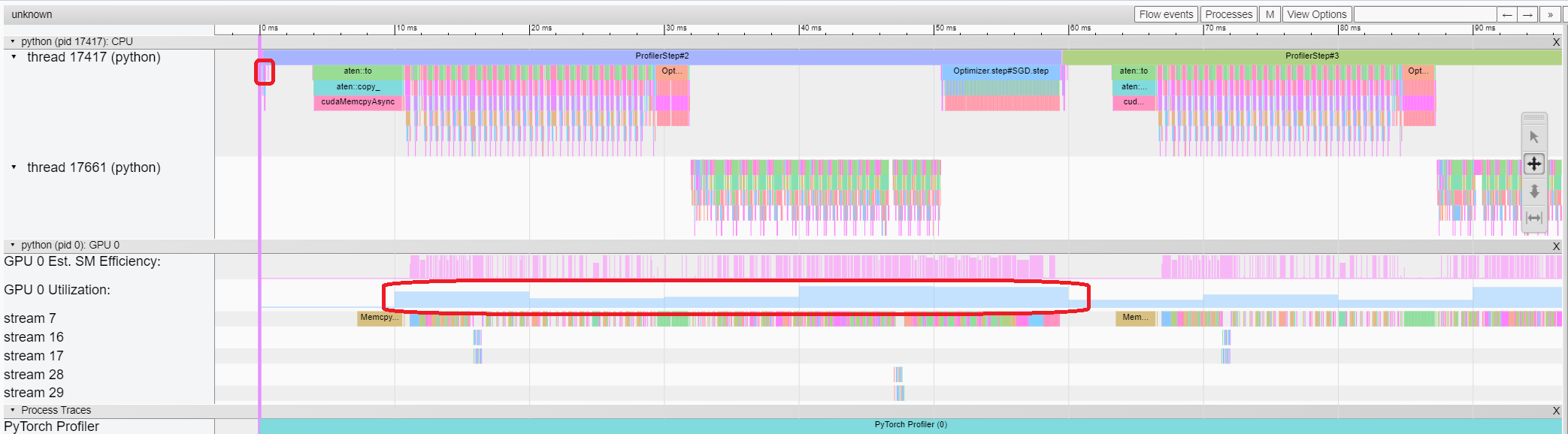
위의 보기(view)에서 ``enumerate(DataLoader)``의 런타임이 감소하고, GPU 활용도가 증가하는 것을 알 수 있습니다.
6. 다른 고급 기능으로 성능 분석#
메모리 보기(Memory view)
메모리 프로파일을 설정하려면 torch.profiler.profile 인수에서 ``profile_memory``를 ``True``로 설정해야 합니다.
Azure의 기존 예제를 사용해 볼 수 있습니다.
pip install azure-storage-blob
tensorboard --logdir=https://torchtbprofiler.blob.core.windows.net/torchtbprofiler/demo/memory_demo_1_10
프로파일러는 프로파일링 중에 모든 메모리 할당/해제 이벤트와 할당자의 내부 상태를 기록합니다. 메모리 보기(memory view)는 다음과 같이 세 가지 요소로 구성됩니다.
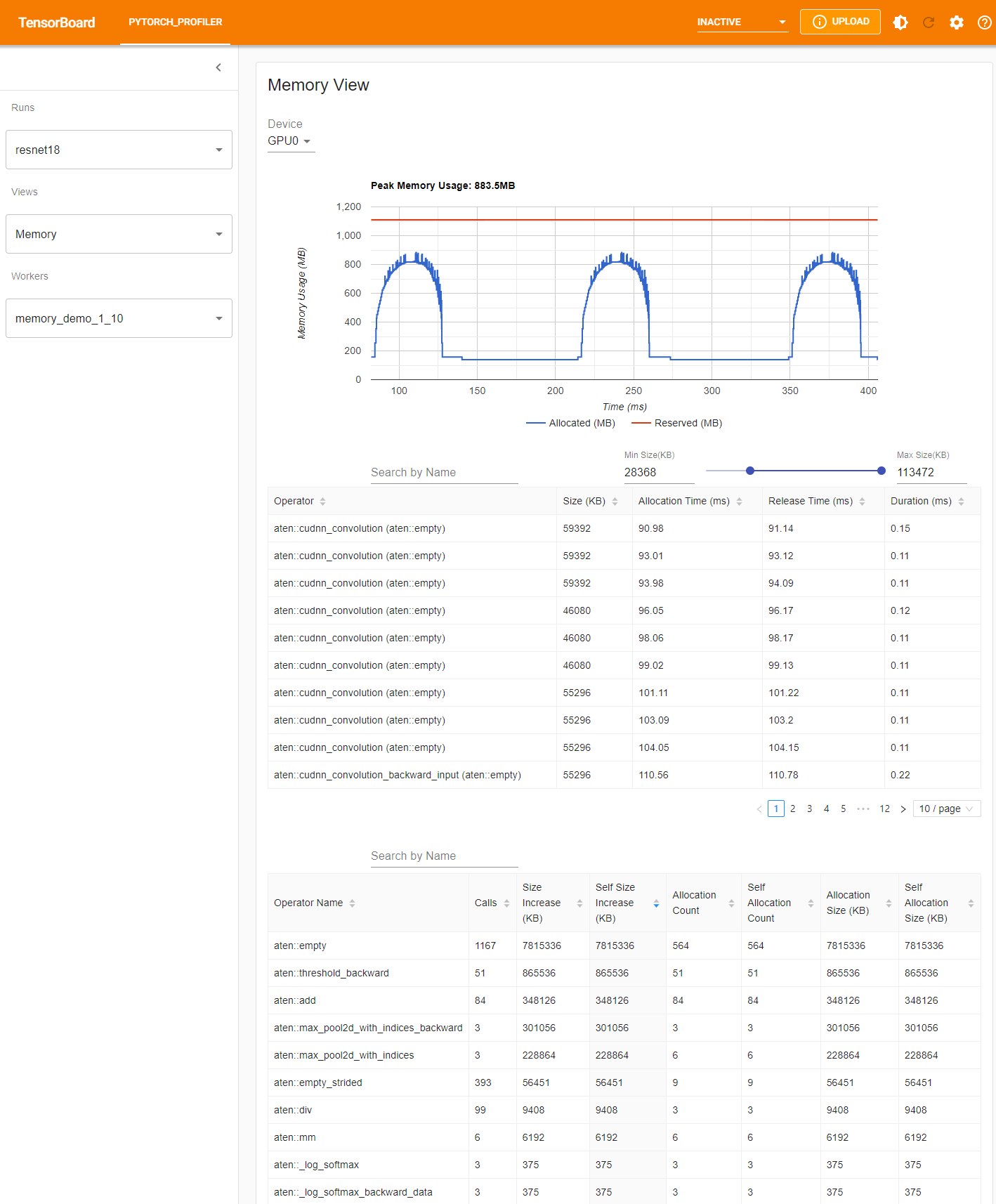
구성 요소는 각각 메모리 곡선 그래프, 메모리 이벤트 테이블 및 메모리 통계 테이블입니다.
메모리 유형은 “장치(Device)” 선택 상자에서 선택할 수 있습니다. 예를 들면, 다음 표에서 “GPU0”은 GPU 0에서의 각 연산자의 메로리 사용량만 보여주고, CPU 또는 다른 GPU를 포함하지 않는다는 것을 의미합니다.
메모리 곡선은 메모리 소비의 추세를 보여줍니다. “Allocated” 곡선은 실제 사용 중인 총 메모리, 예를 들면 tensor를 보여줍니다. 파이토치에서 캐싱 메커니즘(caching mechanism)은 CUDA 할당기 및 일부 다른 할당기에 사용됩니다. “Reserved” 곡선은 할당자에 의해 예약된 총 메모리를 보여줍니다. 그래프를 좌클릭하고 끌어서 원하는 범위의 이벤트를 선택할 수 있습니다:
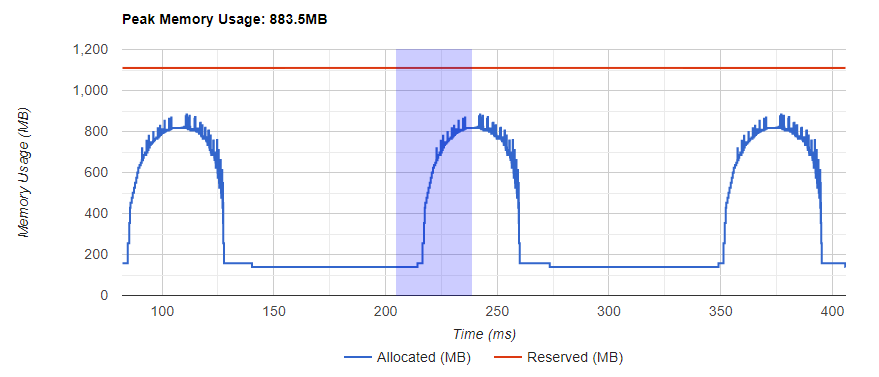
선택한 후에는 세 가지 구성 요소가 제한된 범위에 맞게 업데이트되어 자세한 정보를 얻을 수 있습니다. 이 프로세스를 반복하면, 매우 세분화된 세부 정보를 확대할 수 있습니다. 그래프를 우클릭하면 그래프가 초기 상태로 재설정됩니다.
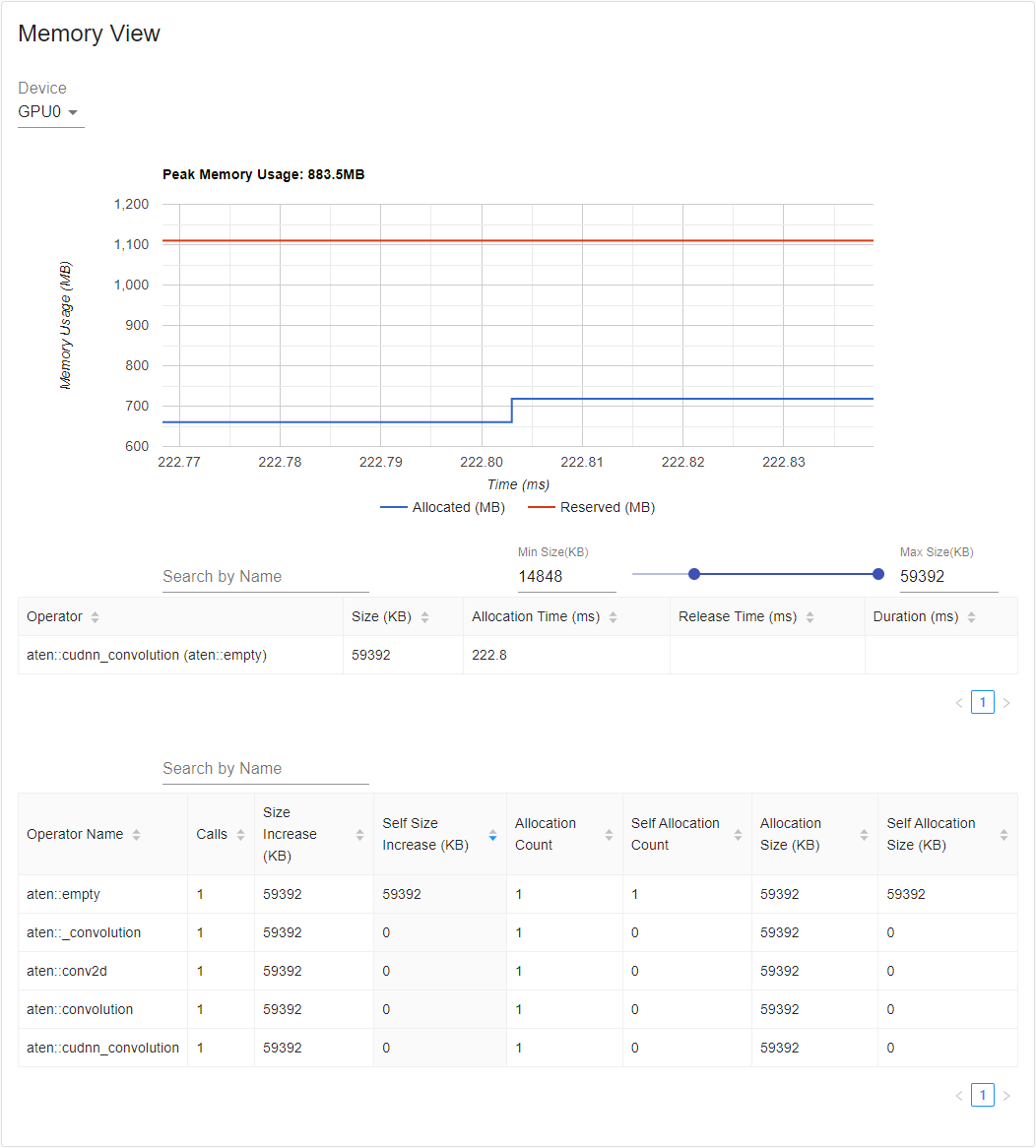
메모리 이벤트 테이블에서 할당 및 해제 이벤트는 하나의 항목으로 쌍으로 구성됩니다. “operator” 열에는
할당을 발생시키는 즉시 ATen 연산자가 표시됩니다. 파이토치에서 ATen 연산자는 일반적으로
aten::empty``를 사용하여 메모리를 할당합니다. 예를 들어, ``aten::ones``은 ``aten::empty 다음에
``aten::fill_``로 구현됩니다. 연산자 이름만 ``aten::empty``로 표시해도 별 도움이 되지 않습니다. 이 특수한 경우에는
``aten::ones (aten::empty)``로 표시됩니다. “할당 시간(Allocation Time)”, “해제 시간(Release Time)” 및 “기간(Duration)”은
이벤트가 시간 범위를 벗어나는 경우 열의 데이터가 누락될 수 있습니다.
메모리 통계 테이블에서, “크기 증가(Size Increase)” 열은 모든 할당 크기를 합산하고 모든 메모리 릴리스(release) 크기를 뺀 값, 즉, 이 연산자 이후의 메모리 사용량 순 증가 값입니다. “자체 크기 증가(Self Size Increase)” 열은 “크기 증가(Size Increase)”와 유사 하지만, 하위 연산자의 할당은 계산하지 않습니다. ATen 연산자의 구현 세부 사항과 관련하여, 일부 연산자는 다른 연산자를 호출할 수 있으므로, 메모리 할당은 콜 스택의 모든 수준에서 발생할 수 있습니다. 즉, “자체 크기 증가(Self Size Increase)”는 현재 수준의 콜 스택에서 메모리 사용량 증가만을 계산합니다. 마지막으로, “할당 크기(Allocation Size)” 열은 메모리 릴리스를 고려하지 않고 모든 할당을 합산합니다.
분산 보기(Distributed view)
이제 플러그인은 NCCL/GLOO를 백엔드로 사용하는 DDP 프로파일링에 대한 분산 보기를 지원합니다.
Azure의 기존 예제를 사용해 볼 수 있습니다:
pip install azure-storage-blob
tensorboard --logdir=https://torchtbprofiler.blob.core.windows.net/torchtbprofiler/demo/distributed_bert
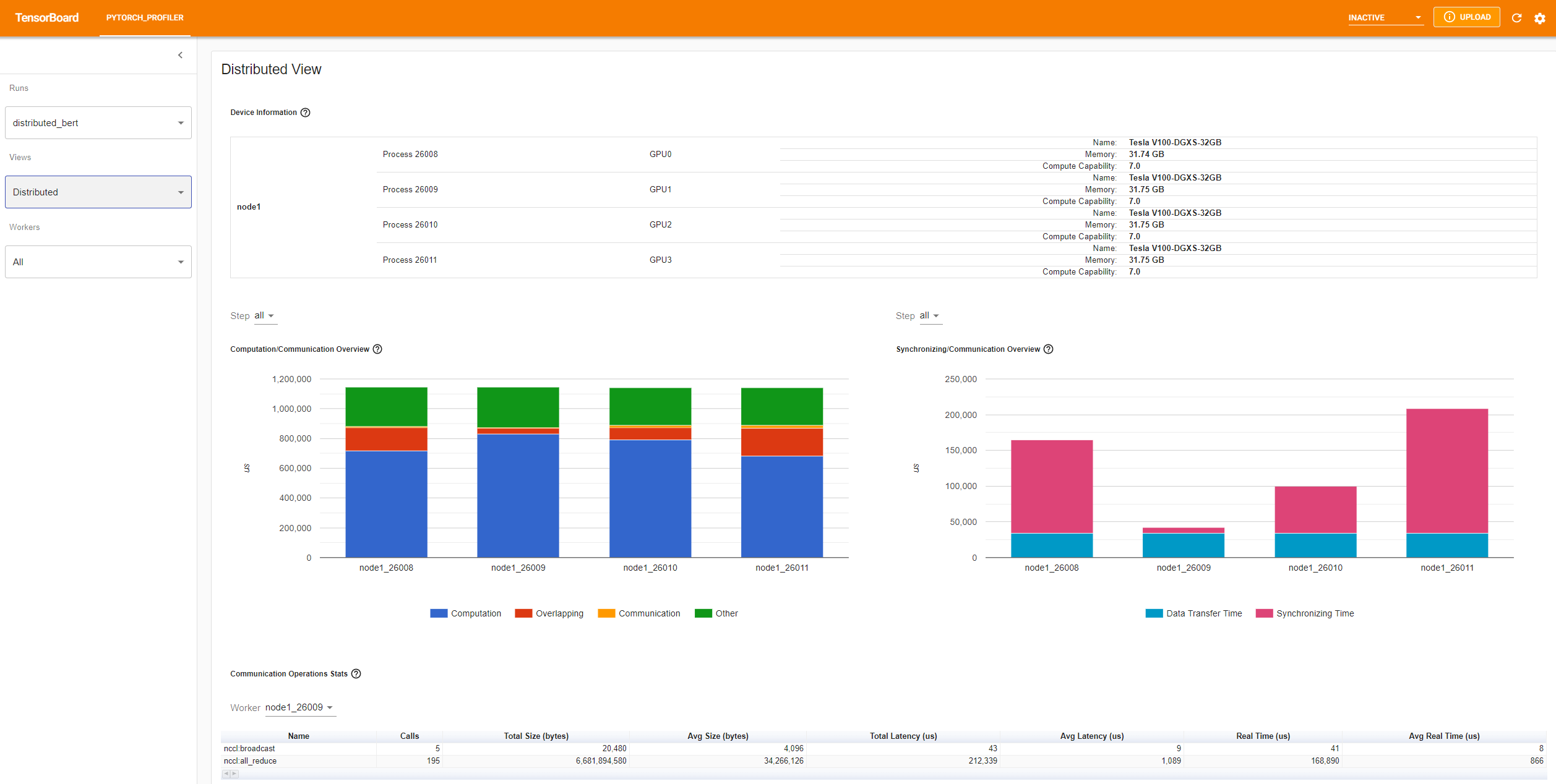
“컴퓨팅/커뮤니케이션 개요(Computation/Communication Overview)”에는 컴퓨팅/커뮤니케이션 비율과 중복 정도가 표시됩니다. 이 보기에서, 사용자는 작업자 간의 로드 밸런싱 문제를 파악할 수 있습니다. 예를 들어, 한 작업자의 연산 + 중복 시간이 다른 작업자보다 훨씬 큰 경우, 로드 밸런싱에 문제가 있거나 이 작업자가 낙오자(straggler)일 수 있습니다.
“동기화/커뮤니케이션 개요(Synchronizing/Communication Overview)”는 통신의 효율성을 보여줍니다. “데이터 교환 시간(Data Transfer Time)”은 실제 데이터를 교환하는 시간입니다. “동기화 시간(Synchronizing Time)”은 다른 작업자와 대기 및 동기화하는 시간입니다.
한 작업자의 “동기화 시간”이 다른 작업자 보다 훨씬 짧다면’, 이 작업자는 다른 작업자보다 더 많은 계산 작업량을 가질 수 있는 낙오자(straggler)일 수 있습니다’.
“커뮤니케이션 작업 통계(Communication Operations Stats)”는 각 작업자의 모든 통신 작업에 대한 세부 통계를 요약합니다.
7. 추가 연습: AMD GPU에서 PyTorch 프로파일링#
The AMD ROCm Platform is an open-source software stack designed for GPU computation, consisting of drivers, development tools, and APIs. We can run the above mentioned steps on AMD GPUs. In this section, we will use Docker to install the ROCm base development image before installing PyTorch.
For the purpose of example, let’s create a directory called profiler_tutorial, and save the code in Step 1 as test_cifar10.py in this directory.
mkdir ~/profiler_tutorial
cd profiler_tutorial
vi test_cifar10.py
At the time of this writing, the Stable(2.1.1) Linux version of PyTorch on ROCm Platform is ROCm 5.6.
Obtain a base Docker image with the correct user-space ROCm version installed from Docker Hub.
It is rocm/dev-ubuntu-20.04:5.6.
Start the ROCm base Docker container:
docker run -it --network=host --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 8G -v ~/profiler_tutorial:/profiler_tutorial rocm/dev-ubuntu-20.04:5.6
Inside the container, install any dependencies needed for installing the wheels package.
sudo apt update
sudo apt install libjpeg-dev python3-dev -y
pip3 install wheel setuptools
sudo apt install python-is-python3
Install the wheels:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.6
Install the
torch_tb_profiler, and then, run the Python filetest_cifar10.py:
pip install torch_tb_profiler
cd /profiler_tutorial
python test_cifar10.py
Now, we have all the data needed to view in TensorBoard:
tensorboard --logdir=./log
Choose different views as described in Step 4. For example, below is the Operator View:
At the time this section is written, Trace view does not work and it displays nothing. You can work around by typing chrome://tracing in your Chrome Browser.
Copy the
trace.jsonfile under~/profiler_tutorial/log/resnet18directory to the Windows.
You may need to copy the file by using scp if the file is located in a remote location.
Click Load button to load the trace JSON file from the
chrome://tracingpage in the browser.
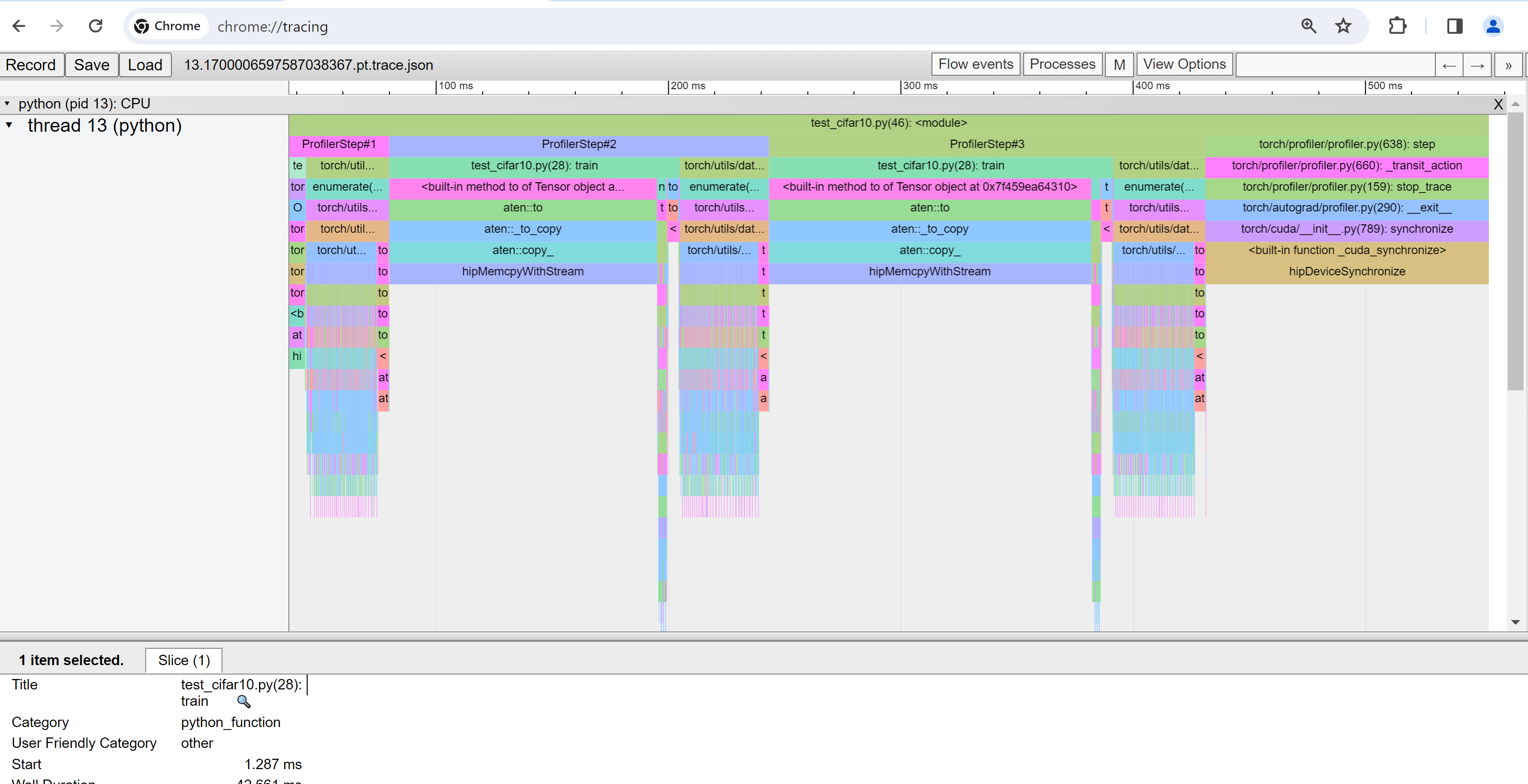
As mentioned previously, you can move the graph and zoom in and out.
You can also use keyboard to zoom and move around inside the timeline.
The w and s keys zoom in centered around the mouse,
and the a and d keys move the timeline left and right.
You can hit these keys multiple times until you see a readable representation.
더 알아보기#
학습을 계속하려면 다음 문서를 참조하시고, 여기 에서 자유롭게 이슈를 열어보세요.
Total running time of the script: (0 minutes 19.780 seconds)
