Implementing Batch RPC Processing Using Asynchronous Executions#
Author: Shen Li
참고
 View and edit this tutorial in github.
View and edit this tutorial in github.
Prerequisites:
This tutorial demonstrates how to build batch-processing RPC applications with the @rpc.functions.async_execution decorator, which helps to speed up training by reducing the number of blocked RPC threads and consolidating CUDA operations on the callee.
참고
This tutorial requires PyTorch v1.6.0 or above.
Basics#
Previous tutorials have shown the steps to build distributed training applications using torch.distributed.rpc, but they didn’t elaborate on what happens on the callee side when processing an RPC request. As of PyTorch v1.5, each RPC request will block one thread on the callee to execute the function in that request until that function returns. This works for many use cases, but there is one caveat. If the user function blocks on IO, e.g., with nested RPC invocation, or signaling, e.g., waiting for a different RPC request to unblock, the RPC thread on the callee will have to idle waiting until the IO finishes or the signaling event occurs. As a result, RPC callees are likely to use more threads than necessary. The cause of this problem is that RPC treats user functions as black boxes, and knows very little about what happens in the function. To allow user functions to yield and free RPC threads, more hints need to be provided to the RPC system.
Since v1.6.0, PyTorch addresses this problem by introducing two new concepts:
A torch.futures.Future type that encapsulates an asynchronous execution, which also supports installing callback functions.
An @rpc.functions.async_execution decorator that allows applications to tell the callee that the target function will return a future and can pause and yield multiple times during execution.
With these two tools, the application code can break a user function into
multiple smaller functions, chain them together as callbacks on Future
objects, and return the Future that contains the final result. On the callee
side, when getting the Future object, it installs subsequent RPC response
preparation and communication as callbacks as well, which will be triggered
when the final result is ready. In this way, the callee no longer needs to block
one thread and wait until the final return value is ready. Please refer to the
API doc of
@rpc.functions.async_execution
for simple examples.
Besides reducing the number of idle threads on the callee, these tools also help to make batch RPC processing easier and faster. The following two sections of this tutorial demonstrate how to build distributed batch-updating parameter server and batch-processing reinforcement learning applications using the @rpc.functions.async_execution decorator.
Batch-Updating Parameter Server#
Consider a synchronized parameter server training application with one parameter
server (PS) and multiple trainers. In this application, the PS holds the
parameters and waits for all trainers to report gradients. In every iteration,
it waits until receiving gradients from all trainers and then updates all
parameters in one shot. The code below shows the implementation of the PS class.
The update_and_fetch_model method is decorated using
@rpc.functions.async_execution and will be called by trainers. Each
invocation returns a Future object that will be populated with the updated
model. Invocations launched by most trainers just accumulate gradients to the
.grad field, return immediately, and yield the RPC thread on the PS. The
last arriving trainer will trigger the optimizer step and consume all previously
reported gradients. Then it sets the future_model with the updated model,
which in turn notifies all previous requests from other trainers through the
Future object and sends out the updated model to all trainers.
import threading
import torchvision
import torch
import torch.distributed.rpc as rpc
from torch import optim
num_classes, batch_update_size = 30, 5
class BatchUpdateParameterServer(object):
def __init__(self, batch_update_size=batch_update_size):
self.model = torchvision.models.resnet50(num_classes=num_classes)
self.lock = threading.Lock()
self.future_model = torch.futures.Future()
self.batch_update_size = batch_update_size
self.curr_update_size = 0
self.optimizer = optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
for p in self.model.parameters():
p.grad = torch.zeros_like(p)
def get_model(self):
return self.model
@staticmethod
@rpc.functions.async_execution
def update_and_fetch_model(ps_rref, grads):
# Using the RRef to retrieve the local PS instance
self = ps_rref.local_value()
with self.lock:
self.curr_update_size += 1
# accumulate gradients into .grad field
for p, g in zip(self.model.parameters(), grads):
p.grad += g
# Save the current future_model and return it to make sure the
# returned Future object holds the correct model even if another
# thread modifies future_model before this thread returns.
fut = self.future_model
if self.curr_update_size >= self.batch_update_size:
# update the model
for p in self.model.parameters():
p.grad /= self.batch_update_size
self.curr_update_size = 0
self.optimizer.step()
self.optimizer.zero_grad()
# by settiing the result on the Future object, all previous
# requests expecting this updated model will be notified and
# the their responses will be sent accordingly.
fut.set_result(self.model)
self.future_model = torch.futures.Future()
return fut
For the trainers, they are all initialized using the same set of
parameters from the PS. In every iteration, each trainer first runs the forward
and the backward passes to generate gradients locally. Then, each trainer
reports its gradients to the PS using RPC, and fetches back the updated
parameters through the return value of the same RPC request. In the trainer’s
implementation, whether the target function is marked with
@rpc.functions.async_execution or not makes no difference. The
trainer simply calls update_and_fetch_model using rpc_sync which will
block on the trainer until the updated model is returned.
batch_size, image_w, image_h = 20, 64, 64
class Trainer(object):
def __init__(self, ps_rref):
self.ps_rref, self.loss_fn = ps_rref, torch.nn.MSELoss()
self.one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
def get_next_batch(self):
for _ in range(6):
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, self.one_hot_indices, 1)
yield inputs.cuda(), labels.cuda()
def train(self):
name = rpc.get_worker_info().name
# get initial model parameters
m = self.ps_rref.rpc_sync().get_model().cuda()
# start training
for inputs, labels in self.get_next_batch():
self.loss_fn(m(inputs), labels).backward()
m = rpc.rpc_sync(
self.ps_rref.owner(),
BatchUpdateParameterServer.update_and_fetch_model,
args=(self.ps_rref, [p.grad for p in m.cpu().parameters()]),
).cuda()
We skip the code that launches multiple processes in this tutorial and please refer to the examples repo for the full implementation. Note that, it is possible to implement batch processing without the @rpc.functions.async_execution decorator. However, that would require either blocking more RPC threads on the PS or use another round of RPC to fetch updated models, where the latter would add both more code complexity and more communication overhead.
This section uses a simple parameter sever training example to show how to implement batch RPC applications using the @rpc.functions.async_execution decorator. In the next section, we re-implement the reinforcement learning example in the previous Getting started with Distributed RPC Framework tutorial using batch processing, and demonstrate its impact on the training speed.
Batch-Processing CartPole Solver#
This section uses CartPole-v1 from OpenAI Gym as
an example to show the performance impact of batch processing RPC. Please note
that since the goal is to demonstrate the usage of
@rpc.functions.async_execution
instead of building the best CartPole solver or solving most different RL
problems, we use very simple policies and reward calculation strategies and
focus on the multi-observer single-agent batch RPC implementation. We use a
similar Policy model as the previous tutorial which is shown below. Compared
to the previous tutorial, the difference is that its constructor takes an
additional batch argument which controls the dim parameter for
F.softmax because with batching, the x argument in the forward
function contains states from multiple observers and hence the dimension needs
to change properly. Everything else stays intact.
import argparse
import torch.nn as nn
import torch.nn.functional as F
parser = argparse.ArgumentParser(description='PyTorch RPC Batch RL example')
parser.add_argument('--gamma', type=float, default=1.0, metavar='G',
help='discount factor (default: 1.0)')
parser.add_argument('--seed', type=int, default=543, metavar='N',
help='random seed (default: 543)')
parser.add_argument('--num-episode', type=int, default=10, metavar='E',
help='number of episodes (default: 10)')
args = parser.parse_args()
torch.manual_seed(args.seed)
class Policy(nn.Module):
def __init__(self, batch=True):
super(Policy, self).__init__()
self.affine1 = nn.Linear(4, 128)
self.dropout = nn.Dropout(p=0.6)
self.affine2 = nn.Linear(128, 2)
self.dim = 2 if batch else 1
def forward(self, x):
x = self.affine1(x)
x = self.dropout(x)
x = F.relu(x)
action_scores = self.affine2(x)
return F.softmax(action_scores, dim=self.dim)
The constructor of the Observer adjusts accordingly as well. It also takes a
batch argument, which governs which Agent function it uses to select
actions. In batch mode, it calls select_action_batch function on Agent
which will be presented shortly, and this function will be decorated with
@rpc.functions.async_execution.
import gym
import torch.distributed.rpc as rpc
class Observer:
def __init__(self, batch=True):
self.id = rpc.get_worker_info().id - 1
self.env = gym.make('CartPole-v1')
self.env.seed(args.seed)
self.select_action = Agent.select_action_batch if batch else Agent.select_action
Compared to the previous tutorial
Getting started with Distributed RPC Framework,
observers behave a little differently. Instead of exiting when the environment
is stopped, it always runs n_steps iterations in every episode. When the
environment returns, the observer simply resets the environment and start over
again. With this design, the agent will receive a fixed number of states from
every observer and hence can pack them into a fixed-size tensor. In every
step, the Observer uses RPC to send its state to the Agent and fetches
the action through the return value. At the end of every episode, it returns the
rewards of all steps to Agent. Note that this run_episode function will
be called by the Agent using RPC. So the rpc_sync call in this function
will be a nested RPC invocation. We could mark this function as @rpc.functions.async_execution
too to avoid blocking one thread on the Observer. However, as the bottleneck
is the Agent instead of the Observer, it should be OK to block one
thread on the Observer process.
import torch
class Observer:
...
def run_episode(self, agent_rref, n_steps):
state, ep_reward = self.env.reset(), NUM_STEPS
rewards = torch.zeros(n_steps)
start_step = 0
for step in range(n_steps):
state = torch.from_numpy(state).float().unsqueeze(0)
# send the state to the agent to get an action
action = rpc.rpc_sync(
agent_rref.owner(),
self.select_action,
args=(agent_rref, self.id, state)
)
# apply the action to the environment, and get the reward
state, reward, done, _ = self.env.step(action)
rewards[step] = reward
if done or step + 1 >= n_steps:
curr_rewards = rewards[start_step:(step + 1)]
R = 0
for i in range(curr_rewards.numel() -1, -1, -1):
R = curr_rewards[i] + args.gamma * R
curr_rewards[i] = R
state = self.env.reset()
if start_step == 0:
ep_reward = min(ep_reward, step - start_step + 1)
start_step = step + 1
return [rewards, ep_reward]
The constructor of the Agent also takes a batch argument, which controls
how action probs are batched. In batch mode, the saved_log_probs contains a
list of tensors, where each tensor contains action robs from all observers in
one step. Without batching, the saved_log_probs is a dictionary where the
key is the observer id and the value is a list of action probs for that
observer.
import threading
from torch.distributed.rpc import RRef
class Agent:
def __init__(self, world_size, batch=True):
self.ob_rrefs = []
self.agent_rref = RRef(self)
self.rewards = {}
self.policy = Policy(batch).cuda()
self.optimizer = optim.Adam(self.policy.parameters(), lr=1e-2)
self.running_reward = 0
for ob_rank in range(1, world_size):
ob_info = rpc.get_worker_info(OBSERVER_NAME.format(ob_rank))
self.ob_rrefs.append(rpc.remote(ob_info, Observer, args=(batch,)))
self.rewards[ob_info.id] = []
self.states = torch.zeros(len(self.ob_rrefs), 1, 4)
self.batch = batch
self.saved_log_probs = [] if batch else {k:[] for k in range(len(self.ob_rrefs))}
self.future_actions = torch.futures.Future()
self.lock = threading.Lock()
self.pending_states = len(self.ob_rrefs)
The non-batching select_acion simply runs the state throw the policy, saves
the action prob, and returns the action to the observer right away.
from torch.distributions import Categorical
class Agent:
...
@staticmethod
def select_action(agent_rref, ob_id, state):
self = agent_rref.local_value()
probs = self.policy(state.cuda())
m = Categorical(probs)
action = m.sample()
self.saved_log_probs[ob_id].append(m.log_prob(action))
return action.item()
With batching, the state is stored in a 2D tensor self.states, using the
observer id as the row id. Then, it chains a Future by installing a callback
function to the batch-generated self.future_actions Future object, which
will be populated with the specific row indexed using the id of that observer.
The last arriving observer runs all batched states through the policy in one
shot and set self.future_actions accordingly. When this occurs, all the
callback functions installed on self.future_actions will be triggered and
their return values will be used to populate the chained Future object,
which in turn notifies the Agent to prepare and communicate responses for
all previous RPC requests from other observers.
class Agent:
...
@staticmethod
@rpc.functions.async_execution
def select_action_batch(agent_rref, ob_id, state):
self = agent_rref.local_value()
self.states[ob_id].copy_(state)
future_action = self.future_actions.then(
lambda future_actions: future_actions.wait()[ob_id].item()
)
with self.lock:
self.pending_states -= 1
if self.pending_states == 0:
self.pending_states = len(self.ob_rrefs)
probs = self.policy(self.states.cuda())
m = Categorical(probs)
actions = m.sample()
self.saved_log_probs.append(m.log_prob(actions).t()[0])
future_actions = self.future_actions
self.future_actions = torch.futures.Future()
future_actions.set_result(actions.cpu())
return future_action
Now let’s define how different RPC functions are stitched together. The Agent
controls the execution of every episode. It first uses rpc_async to kick off
the episode on all observers and block on the returned futures which will be
populated with observer rewards. Note that the code below uses the RRef helper
ob_rref.rpc_async() to launch the run_episode function on the owner
of the ob_rref RRef with the provided arguments.
It then converts the saved action probs and returned observer rewards into
expected data format, and launch the training step. Finally, it resets all
states and returns the reward of the current episode. This function is the entry
point to run one episode.
class Agent:
...
def run_episode(self, n_steps=0):
futs = []
for ob_rref in self.ob_rrefs:
# make async RPC to kick off an episode on all observers
futs.append(ob_rref.rpc_async().run_episode(self.agent_rref, n_steps))
# wait until all obervers have finished this episode
rets = torch.futures.wait_all(futs)
rewards = torch.stack([ret[0] for ret in rets]).cuda().t()
ep_rewards = sum([ret[1] for ret in rets]) / len(rets)
# stack saved probs into one tensor
if self.batch:
probs = torch.stack(self.saved_log_probs)
else:
probs = [torch.stack(self.saved_log_probs[i]) for i in range(len(rets))]
probs = torch.stack(probs)
policy_loss = -probs * rewards / len(rets)
policy_loss.sum().backward()
self.optimizer.step()
self.optimizer.zero_grad()
# reset variables
self.saved_log_probs = [] if self.batch else {k:[] for k in range(len(self.ob_rrefs))}
self.states = torch.zeros(len(self.ob_rrefs), 1, 4)
# calculate running rewards
self.running_reward = 0.5 * ep_rewards + 0.5 * self.running_reward
return ep_rewards, self.running_reward
The rest of the code is normal processes launching and logging which are similar to other RPC tutorials. In this tutorial, all observers passively waiting for commands from the agent. Please refer to the examples repo for the full implementation.
def run_worker(rank, world_size, n_episode, batch, print_log=True):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
if rank == 0:
# rank0 is the agent
rpc.init_rpc(AGENT_NAME, rank=rank, world_size=world_size)
agent = Agent(world_size, batch)
for i_episode in range(n_episode):
last_reward, running_reward = agent.run_episode(n_steps=NUM_STEPS)
if print_log:
print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format(
i_episode, last_reward, running_reward))
else:
# other ranks are the observer
rpc.init_rpc(OBSERVER_NAME.format(rank), rank=rank, world_size=world_size)
# observers passively waiting for instructions from agents
rpc.shutdown()
def main():
for world_size in range(2, 12):
delays = []
for batch in [True, False]:
tik = time.time()
mp.spawn(
run_worker,
args=(world_size, args.num_episode, batch),
nprocs=world_size,
join=True
)
tok = time.time()
delays.append(tok - tik)
print(f"{world_size}, {delays[0]}, {delays[1]}")
if __name__ == '__main__':
main()
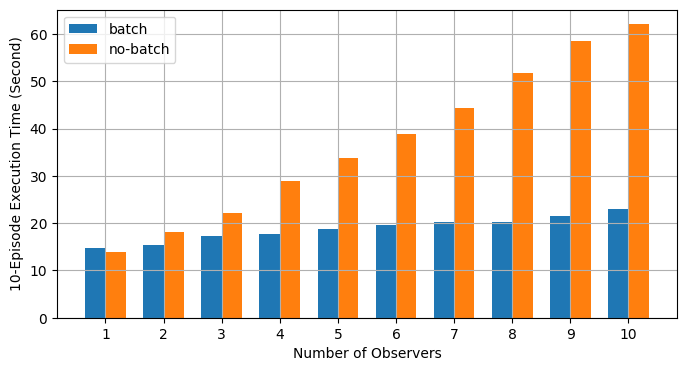
Batch RPC helps to consolidate the action inference into less CUDA operations,
and hence reduces the amortized overhead. The above main function runs the
same code on both batch and no-batch modes using different numbers of observers,
ranging from 1 to 10. The figure below plots the execution time of different
world sizes using default argument values. The results confirmed our expectation
that batch processing helped to speed up training.