


PyTorch로 분산 어플리케이션 개발하기#
- Author: Séb Arnold
번역: 박정환
참고
 이 튜토리얼의 소스 코드는 GitHub 에서 확인하고 변경해 볼 수 있습니다.
이 튜토리얼의 소스 코드는 GitHub 에서 확인하고 변경해 볼 수 있습니다.
선수과목(Prerequisites):
이 짧은 튜토리얼에서는 PyTorch의 분산 패키지를 둘러볼 예정입니다. 여기에서는 어떻게 분산 환경을 설정하는지와 서로 다른 통신 방법을 사용하는지를 알아보고, 패키지 내부도 일부 살펴보도록 하겠습니다.
설정(Setup)#
PyTorch에 포함된 분산 패키지(예. torch.distributed)는 연구자와 실무자가
여러 프로세스와 클러스터의 기기에서 계산을 쉽게 병렬화 할 수 있게 합니다.
이를 위해, 각 프로세스가 다른 프로세스와 데이터를 교환할 수 있도록 메시지 교환
규약(messaging passing semantics)을 활용합니다. 멀티프로세싱(torch.multiprocessing)
패키지와 달리, 프로세스는 다른 커뮤니케이션 백엔드(backend)를 사용할 수 있으며
동일 기기 상에서 실행되는 것에 제약이 없습니다.
이 튜토리얼을 시작하기 위해 여러 프로세스를 동시에 실행할 수 있어야 합니다. 연산 클러스터에 접근하는 경우에는 시스템 관리자에게 확인하거나 선호하는 코디네이션 도구(coordination tool)를 사용하시면 됩니다. (예. pdsh, clustershell, 또는 slurm). 이 튜토리얼에서는 다음 템플릿을 사용하여 단일 기기에서 여러 프로세스를 생성(fork)하겠습니다.
"""run.py:"""
#!/usr/bin/env python
import os
import sys
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank, size):
""" Distributed function to be implemented later. """
pass
def init_process(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
if __name__ == "__main__":
world_size = 2
processes = []
if "google.colab" in sys.modules:
print("Running in Google Colab")
mp.get_context("spawn")
else:
mp.set_start_method("spawn")
for rank in range(world_size):
p = mp.Process(target=init_process, args=(rank, world_size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
위 스크립트는 2개의 프로세스를 생성(spawn)하여 각자 다른 분산 환경을 설정하고,
프로세스 그룹(dist.init_process_group)을 초기화하고, 최종적으로는 run
함수를 실행합니다.
이제 init_process 함수를 살펴보도록 하겠습니다. 이 함수는 모든 프로세스가
마스터를 통해 조정(coordinate)될 수 있도록 동일한 IP 주소와 포트를 사용합니다.
여기에서는 gloo 백엔드를 사용하였으나 다른 백엔드들도 사용이 가능합니다.
(섹션 5.1 참고) 이 튜토리얼의 마지막 부분에 있는
dist.init_process_group 에서 일어나는 놀라운 일을 살펴볼 것이지만, 기본적으로는
프로세스가 자신의 위치를 공유함으로써 서로 통신할 수 있도록 합니다.
점-대-점 간(Point-to-Point) 통신#
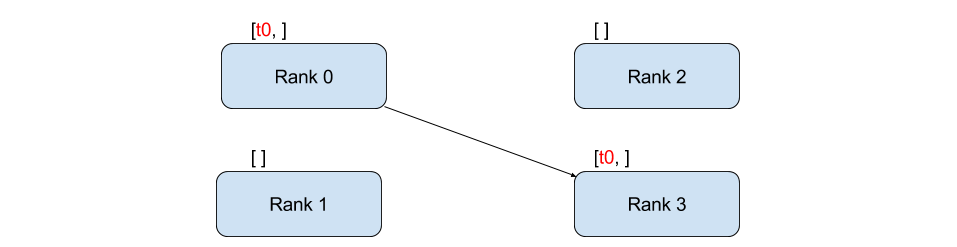
송신과 수신#
하나의 프로세스에서 다른 프로세스로 데이터를 전송하는 것을 점-대-점 간 통신이라고 합니다.
지점간 통신은 send/recv 함수 또는 즉시 응답하는(immediate counter-parts)
isend 와 irecv 를 사용합니다.
"""블로킹(blocking) 점-대-점 간 통신"""
def run(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 1
# Send the tensor to process 1
dist.send(tensor=tensor, dst=1)
else:
# Receive tensor from process 0
dist.recv(tensor=tensor, src=0)
print('Rank ', rank, ' has data ', tensor[0])
위 예제에서 두 프로세스는 값이 0인 Tensor로 시작한 후, 0번 프로세스가 Tensor의 값을 증가시킨 후 1번 프로세스로 보내서 둘 다 1.0으로 종료됩니다. 이 때, 프로세스 1은 수신한 데이터를 저장할 메모리를 할당해두어야 합니다.
또한 send/recv 는 모두 블로킹 입니다: 두 프로세스는 통신이 완료될 때까지
멈춰있습니다. 반면에 즉시 응답하는 것이 논-블로킹 입니다; 스크립트는 실행을
계속하고 메소드는 wait() 를 선택할 수 있는 Work 객체를 반환합니다.
"""논-블로킹(non-blocking) 점-대-점 간 통신"""
def run(rank, size):
tensor = torch.zeros(1)
req = None
if rank == 0:
tensor += 1
# Send the tensor to process 1
req = dist.isend(tensor=tensor, dst=1)
print('Rank 0 started sending')
else:
# Receive tensor from process 0
req = dist.irecv(tensor=tensor, src=0)
print('Rank 1 started receiving')
req.wait()
print('Rank ', rank, ' has data ', tensor[0])
즉시 응답하는 함수들을 사용할 때는 Tensor를 어떻게 주고 받을지를 주의해야 합니다.
데이터가 언제 다른 프로세스로 송수신되는지 모르기 때문에, req.wait() 가 완료되기
전에는 전송된 Tensor를 수정하거나 수신된 Tensor에 접근해서는 안됩니다.
dist.isend()다음에tensor에 쓰면 정의되지 않은 동작이 발생합니다.req.wait()가 실행되기 전까지,dist.irecv()다음에tensor를 읽으면 정의되지 않은 동작이 발생합니다.
그러나, req.wait() 를 실행한 후에는 통신이 이루어진 것을 보장받을 수 있기 때문에,
tensor[0] 에 저장된 값은 1.0이 됩니다.
점-대-점 간 통신은 프로세스 간 통신에 대한 더 세밀한 제어를 원할 때 유용합니다. 바이두(Baidu)의 DeepSpeech 나 페이스북(Facebook)의 대규모 실험 에서 사용하는 것과 같은 멋진 알고리즘을 구현할 때 사용할 수 있습니다. (섹션 4.1 참고)
집합 통신(Collective Communication)#
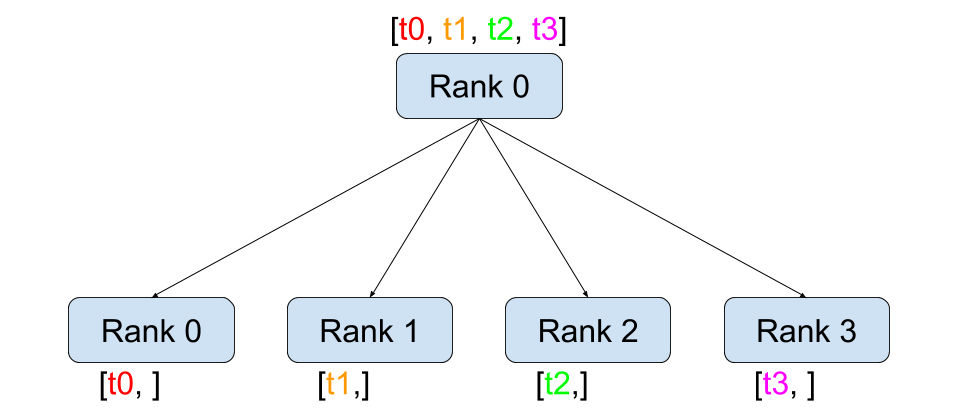
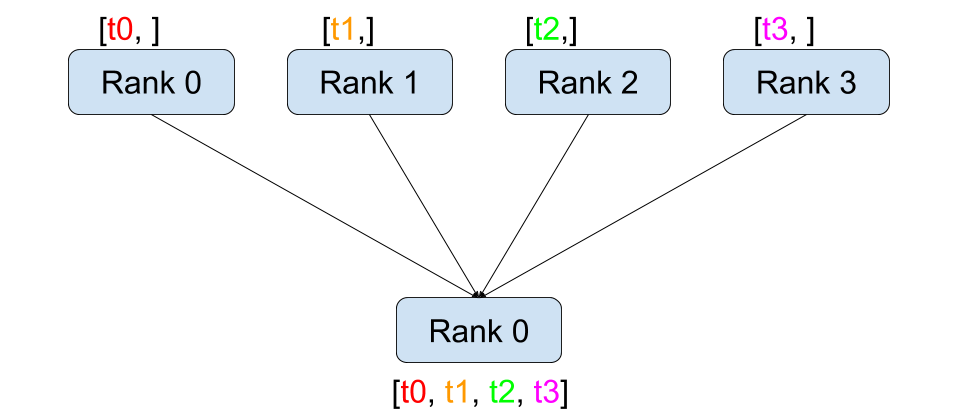
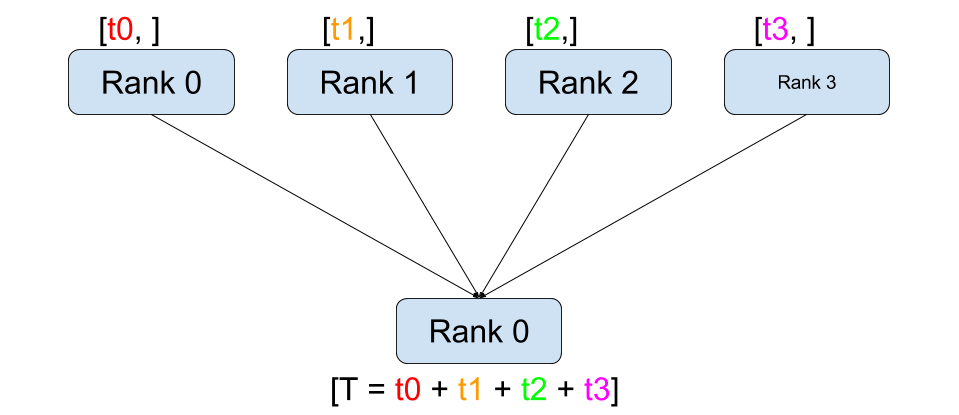
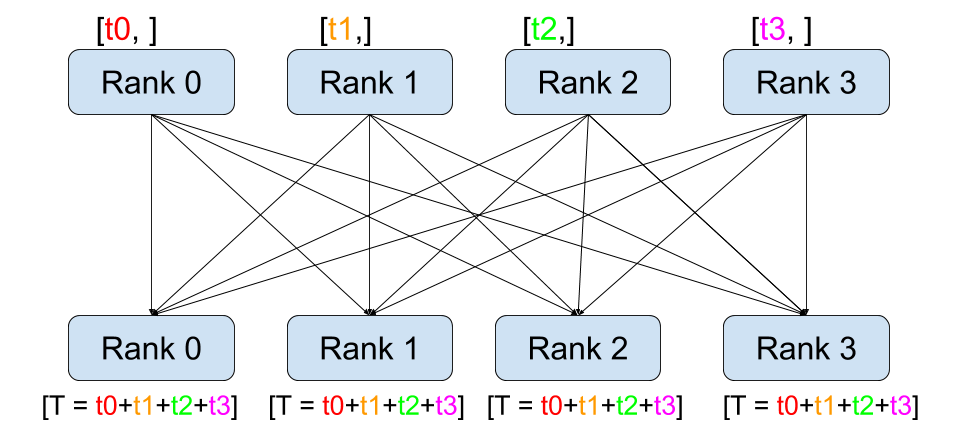
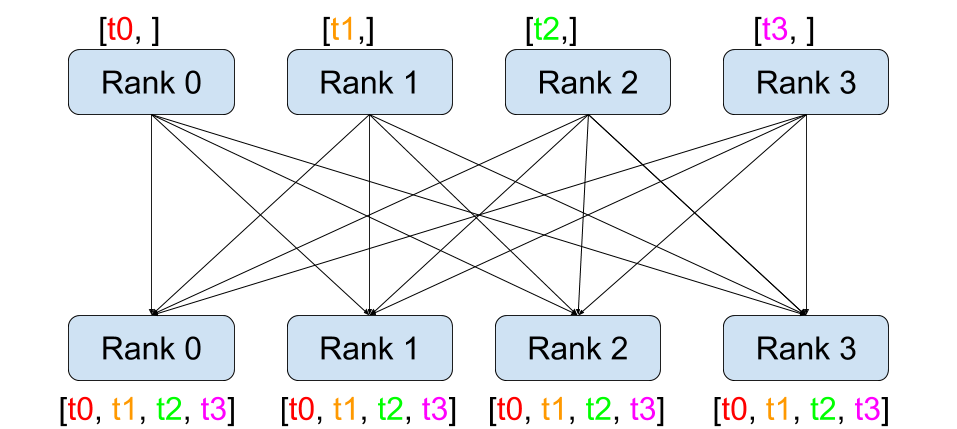
점-대-점 간 통신과 달리 집합 통신은 그룹 의 모든 프로세스에 걸친 통신 패턴을
허용합니다. 그룹은 모든 프로세스의 부분 집합입니다. 그룹을 생성하기 위해서는
dist.new_group(group) 에 순서(rank) 목록을 전달합니다. 기본적으로, 집합 통신은
월드(world) 라고 부르는 전체 프로세스에서 실행됩니다. 예를 들어, 모든 프로세스에
존재하는 모든 Tensor들의 합을 얻기 위해서는 dist.all_reduce(tensor, op, group) 을
사용하면 됩니다.
""" All-Reduce 예제 """
def run(rank, size):
""" 간단한 집합 통신 """
group = dist.new_group([0, 1])
tensor = torch.ones(1)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor[0])
그룹 내의 모든 Tensor들의 합이 필요하기 때문에, dist.ReduceOp.SUM 을
리듀스(reduce) 연산자로 사용하였습니다. 일반적으로, 교환 법칙이 허용되는(commutative)
모든 수학 연산을 연산자로 사용할 수 있습니다. PyTorch는 요소별(element-wise)로
동작하는 기본적으로 4개의 연산자를 제공합니다.
dist.ReduceOp.SUM,dist.ReduceOp.PRODUCT,dist.ReduceOp.MAX,dist.ReduceOp.MIN,dist.ReduceOp.BAND,dist.ReduceOp.BOR,dist.ReduceOp.BXOR,dist.ReduceOp.PREMUL_SUM.
지원하는 연산의 전체 목록은 여기 에서 확인할 수 있습니다.
PyTorch에는 현재 dist.all_reduce(tensor, op, group) 외에도 많은 추가적인 집합 통신이
구현되어 있습니다. 여기 몇 가지 지원되는 집합 통신을 소개합니다.
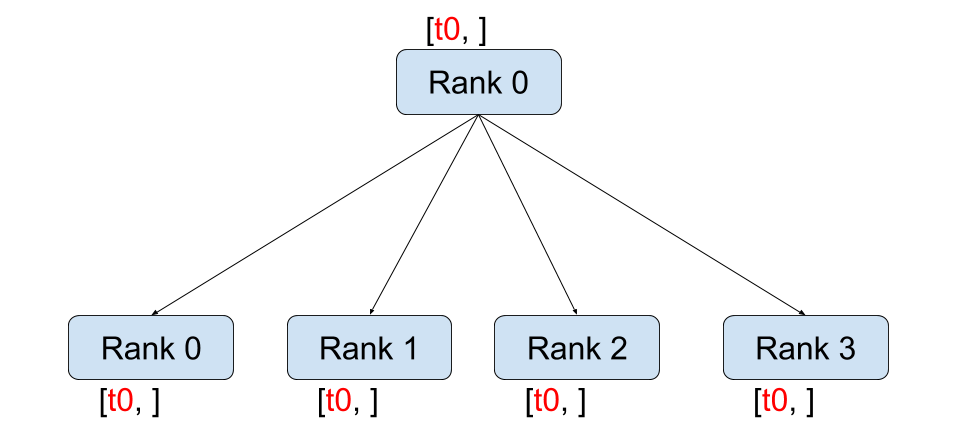
dist.broadcast(tensor, src, group):src의tensor를 모든 프로세스의tensor에 복사합니다.dist.reduce(tensor, dst, op, group):op를 모든tensor에 적용한 뒤 결과를dst프로세스의tensor에 저장합니다.dist.all_reduce(tensor, op, group): 리듀스와 동일하지만, 결과가 모든 프로세스의tensor에 저장됩니다.dist.scatter(tensor, scatter_list, src, group): \(i^{\text{번째}}\) Tensorscatter_list[i]를 \(i^{\text{번째}}\) 프로세스의tensor에 복사합니다.dist.gather(tensor, gather_list, dst, group): 모든 프로세스의tensor를dst프로세스의gather_list에 복사합니다.dist.all_gather(tensor_list, tensor, group): 모든 프로세스의tensor를 모든 프로세스의tensor_list에 복사합니다.dist.barrier(group): group 내의 모든 프로세스가 이 함수에 진입할 때까지 group 내의 모든 프로세스를 멈춥(block)니다.dist.all_to_all(output_tensor_list, input_tensor_list, group): group 내의 모든 프로세스에 input_tensor_list 의 Tensor들을 분산하고, output_tensor_list 에 수집된 Tensor들을 반환합니다.
지원되는 집합 통신의 전체 목록은 PyTorch Distributed의 최신 문서 (링크) 를 참고하세요.
분산 학습(Distributed Training)#
참고: 이 섹션의 예제 스크립트들은 이 GitHub 저장소 에서 찾아보실 수 있습니다.
이제 분산 모듈이 어떻게 동작하는지 이해했으므로, 유용한 뭔가를 작성해보겠습니다. DistributedDataParallel 의 기능을 복제해보는 것이 목표입니다. 물론, 이것은 교훈적인(didactic) 예제이므로 실제 상황에서는 위에 링크된 잘 테스트되고 최적화된 공식 버전을 사용해야 합니다.
매우 간단하게 확률적 경사 하강법(SGD)의 분산 버전을 구현해보겠습니다. 스크립트는 모든 프로세스가 각자의 데이터 배치(batch)에서 각자의 모델의 변화도(gradient)를 계산한 후 평균을 계산합니다. 프로세스의 수를 변경해도 유사한 수렴 결과를 보장하기 위해, 먼저 데이터셋을 분할해야 합니다. (아래 코드 대신 torch.utils.data.random_split 을 사용해도 됩니다.)
""" 데이터셋 분할 헬퍼(helper) """
class Partition(object):
def __init__(self, data, index):
self.data = data
self.index = index
def __len__(self):
return len(self.index)
def __getitem__(self, index):
data_idx = self.index[index]
return self.data[data_idx]
class DataPartitioner(object):
def __init__(self, data, sizes=[0.7, 0.2, 0.1], seed=1234):
self.data = data
self.partitions = []
rng = Random() # from random import Random
rng.seed(seed)
data_len = len(data)
indexes = [x for x in range(0, data_len)]
rng.shuffle(indexes)
for frac in sizes:
part_len = int(frac * data_len)
self.partitions.append(indexes[0:part_len])
indexes = indexes[part_len:]
def use(self, partition):
return Partition(self.data, self.partitions[partition])
위 코드를 사용하여 어떤 데이터셋도 몇 줄의 코드로 간단히 분할할 수 있습니다:
""" MNIST 데이터셋 분할 """
def partition_dataset():
dataset = datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
size = dist.get_world_size()
bsz = 128 // size
partition_sizes = [1.0 / size for _ in range(size)]
partition = DataPartitioner(dataset, partition_sizes)
partition = partition.use(dist.get_rank())
train_set = torch.utils.data.DataLoader(partition,
batch_size=bsz,
shuffle=True)
return train_set, bsz
2개의 복제본이 있다고 가정하고, 각각의 프로세스가 60000 / 2 = 30000 샘플의
train_set 을 가질 것입니다. 또한 전체 배치 크기를 128로 유지하기 위해
배치 크기를 복제본 수로 나누도록 하겠습니다.
이제 일반적인 순전파-역전파-최적화 학습 코드를 작성하고, 모델의 변화도 평균을 계산하는 함수를 추가하겠습니다. (아래 코드는 공식 PyTorch MNIST 예제 에서 많은 부분을 차용하였습니다.)
""" 분산 동기(synchronous) SGD 예제 """
def run(rank, size):
torch.manual_seed(1234)
train_set, bsz = partition_dataset()
model = Net()
optimizer = optim.SGD(model.parameters(),
lr=0.01, momentum=0.5)
num_batches = ceil(len(train_set.dataset) / float(bsz))
for epoch in range(10):
epoch_loss = 0.0
for data, target in train_set:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
epoch_loss += loss.item()
loss.backward()
average_gradients(model)
optimizer.step()
print('Rank ', dist.get_rank(), ', epoch ',
epoch, ': ', epoch_loss / num_batches)
모델을 받아 전체 월드(world)의 평균 변화도를 계산하는 average_gradients(model)
함수를 구현하는 것이 남았습니다.
""" 변화도 평균 계산하기 """
def average_gradients(model):
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
param.grad.data /= size
완성(Et voilà)! 분산 동기(synchronous) SGD를 성공적으로 구현했으며 어떤 모델도 대형 연산 클러스터에서 학습할 수 있습니다.
참고: 마지막 문장은 기술적으로는 참이지만, 동기식 SGD를 상용 수준(production-level)으로 구현하기 위해서는 더 많은 트릭 이 필요합니다. 다시 말씀드리지만, 테스트되고 최적화된 것을 사용하십시오.
사용자 정의 링-올리듀스(Ring-Allreduce)#
추가로 DeepSpeech의 효율적인 링 올리듀스(ring allreduce)를 구현하고 싶다고 가정해보겠습니다. 이것은 점-대-점 집합 통신(point-to-point collectives)으로 쉽게 구현할 수 있습니다.
""" 링-리듀스(ring-reduce) 구현 """
def allreduce(send, recv):
rank = dist.get_rank()
size = dist.get_world_size()
send_buff = send.clone()
recv_buff = send.clone()
accum = send.clone()
left = ((rank - 1) + size) % size
right = (rank + 1) % size
for i in range(size - 1):
if i % 2 == 0:
# Send send_buff
send_req = dist.isend(send_buff, right)
dist.recv(recv_buff, left)
accum[:] += recv_buff[:]
else:
# Send recv_buff
send_req = dist.isend(recv_buff, right)
dist.recv(send_buff, left)
accum[:] += send_buff[:]
send_req.wait()
recv[:] = accum[:]
위 스크립트에서, allreduce(send, recv) 함수는 PyTorch에 있는 것과는 약간
다른 특징을 가지고 있습니다. 이는 recv Tensor를 받은 후 모든 send Tensor의
합을 저장합니다. 여기에서 구현한 것과 DeepSpeech와는 다른 부분이 여전히 다른 부분이
있는데, 이것은 숙제로 남겨두도록 하겠습니다: DeepSpeech의 구현은 통신 대역폭을
최적으로 확용하기 위해 변화도 Tensor를 덩어리(chunk) 로 나눕니다.
(힌트: torch.chunk)
고급 주제(Advanced Topics)#
이제 torch.distributed 보다 진보된 기능들을 살펴볼 준비가 되었습니다.
다루어야 할 주제들이 많으므로, 이 섹션을 다음과 같이 2개의 하위 섹션으로 나누도록
하겠습니다:
통신 백엔드: GPU와 GPU 간의 통신을 위해 MPI와 Gloo를 어떻게 사용해야 할지 배웁니다.
초기화 방법:
dist.init_process_group()에서 초기 구성 단계를 잘 설정하는 방법을 이해합니다.
통신 백엔드(Communication Backends)#
torch.distributed 의 가장 우아한 면 중 하나는 다른 백엔드를 기반으로 추상화하고
구축하는 기능입니다. 앞에서 언급한 것처럼 현재 PyTorch에는 여러 백엔드들이 구현되어 있습니다.
이러한 백엔드들은 서로 다른 가속기(accelerator) 유형들에 해당하는 인터페이스를 제공하는
Accelerator API 를
사용하여 쉽게 선택할 수 있습니다. 일반적으로는 Gloo, NCLL 및 MPI를 많이 하숑합니다.
각각은 원하는 사용 사례에 따라 서로 다른 스펙과 트레이드오프(tradeoffs)를 갖습니다. 지원하는 기능의 비교표는
여기
에서 찾아보실 수 있습니다.
Gloo 백엔드
지금껏 우리는 Gloo backend 를 광범위하게 사용했습니다. 이것은 미리 컴파일된 PyTorch 바이너리가 포함되어 있으며 Linux(0.2 이상)와 macOS(1.3 이상)을 모두 지원하고 있어 개발 플랫폼으로 매우 편리합니다. 또한 CPU에서는 모든 저짐-대-지점 및 집합 연산들을, GPU에서는 집합 연산을 지원합니다. CUDA Tensor에 대한 집합 연산 구현은 NCCL 백엔드에서 제공하는 것만큼 최적화되어 있지는 않습니다.
알고 계시겠지만, 위에서 만든 분산 SGD 예제는 GPU에 model 을 올리면 동작하지
않습니다. 여러 GPU를 사용하기 위해서는 아래와 같이 수정이 필요합니다:
가속기(Accelerator) API 사용:
device_type = torch.accelerator.current_accelerator()torch.device(f"{device_type}:{rank}")사용model = Net()\(\rightarrow\)model = Net().to(device)data, target = data.to(device), target.to(device)사용
위와 같이 변경하고 나면 이제 2개의 GPU에서 모델이 학습을 하며, watch nvidia-smi
로 사용률을 모니터링할 수 있습니다.
MPI 백엔드
MPI(Message Passing Interface)는 고성능 컴퓨팅 분야의 표준 도구입니다.
이는 점-대-점 간 통신과 집합 통신을 허용하며 torch.distributed 의 API에
영감을 주었습니다. 다양한 목적에 따라 최적화된 몇몇 MPI 구현체들(예.
Open-MPI,
MVAPICH2,
Intel MPI )이 있습니다.
MPI 백엔드를 사용하는 이점은 대규모 연산 클러스에서의 MPI의 폭넓은 가용성(과 높은
수준의 최적화)에 있습니다. 또한, 일부
최신
구현체들 은 CPU를 통한 메모리 복사를 방지하기 위해
CUDA IPC와 GPU Direct 기술을 활용하고 있습니다.
불행하게도 PyTorch 바이너리는 MPI 구현을 포함할 수 없으므로 직접 재컴파일해야 합니다. 다행히도 이 과정은 매우 간단해서 PyTorch가 스스로 사용 가능한 MPI 구현체를 찾아볼 것입니다. 다음 단계들은 PyTorch를 소스로부터 설치함으로써 MPI 백엔드를 설치하는 과정입니다.
아나콘다(Anaconda) 환경을 생성하고 활성화한 뒤 이 가이드 를 따라서 모든 필요 사항들을 설치하시되,
python setup.py install은 아직 실행하지 마십시오.선호하는 MPI 구현체를 선택하고 설치하십시오. CUDA를 인식하는 MPI를 활성화하기 위해서는 추가적인 단계가 필요할 수 있습니다. 여기에서는 Open-MPI를 GPU 없이 사용하도록 하겠습니다:
conda install -c conda-forge openmpi이제, 복제해둔 PyTorch 저장소로 가서
python setup.py install을 실행하겠습니다.
새로 설치한 백엔드를 테스트해보기 위해, 약간의 수정을 해보겠습니다.
if __name__ == '__main__':아래 내용을init_process(0, 0, run, backend='mpi')으로 변경합니다.mpirun -n 4 python myscript.py을 실행합니다.
이러한 변경 사항은 MPI가 프로세스를 생성(spawn)하기 전에 자체적인 환경을 만들기
위해 필요합니다. MPI는 자신의 프로세스를 생성하고 초기화 방법
에 설명된 핸드쉐이크(handshake)를 수행하여 init_process_group 의 rank 와
size 인자를 불필요하게 만듭니다. 이는 각 프로세스에 연산 리소스를 조절(tailor)할
수 있도록 추가적인 인자를 mpirun 으로 전달할 수 있기 때문에 매우 강력합니다.
(프로세스당 코어 개수, 장비(machine)의 우선 순위 수동 할당 및
기타 다른 것)
이렇게 함으로써, 다른 통신 백엔드와 같은 유사한 결과를 얻을 수 있습니다.
NCCL 백엔드
NCCL 백엔드 는 CUDA Tensor들에 대한 집합 연산의 최적화된 구현체를 제공합니다. 집합 연산에 CUDA Tensor만 사용하는 경우, 동급 최고 성능을 위해 이 백엔드를 사용하는 것을 고려해보시기 바랍니다. NCCL 백엔드는 미리 빌드(pre-built)된 바이너리에 CUDA 지원과 함께 포함되어 있습니다.
XCCL 백엔드
XCCL 백엔드 는 XPU Tensor들에 대한 집합 연산의 최적화된 구현체를 제공합니다. 만약 집합 연산에 XPU Tensor만 사용하는 경우, 이 백엔드는 동급 최고(Best-in-Class) 성능을 제공합니다. XCCL 백엔드는 XPU 지원과 함께 미리 빌드(pre-built)된 바이너리에 포함되어 있습니다.
초기화 방법(Initialization Methods)#
마지막으로, 처음 호출했던 함수를 살펴보겠습니다: dist.init_process_group(backend, init_method)
특히, 각 프로세스 간의 초기 조정(initial coordination) 단계를 담당하는 다양한 초기화
방법들을 살펴보도록 하겠습니다. 이러한 방법들은 어떻게 이러한 조정이 수행되는지를
정의할 수 있게 합니다. 초기화 방법의 선택은 하드웨어 설정에 따라 다르며, 하나의 방법이 다른 방법보다 더 적합할 수 있습니다.
다음 섹션 외에도 공식 문서
를 참고하실 수 있습니다.
환경 변수
이 튜토리얼에서 지금까지는 환경 변수의 초기화 메소드를 사용해왔습니다. 모든 기기에서 아래 네가지 환경 변수를 설정하게 되면, 모든 프로세스들이 마스터(master)에 적합하게 연결하고, 다른 프로세스들의 정보를 얻은 후 핸드쉐이크까지 할 수 있습니다.
MASTER_PORT: 0-순위의 프로세스를 호스트할 기기의 비어있는 포트 번호(free port)MASTER_ADDR: 0-순위의 프로세스를 호스트할 기기의 IP 주소WORLD_SIZE: 전체 프로세스 수 - 마스터가 얼마나 많은 워커들을 기다릴지 알 수 있습니다RANK: 각 프로세스의 우선순위 - 워커 또는 마스터 여부를 확인할 수 있습니다.
공유 파일 시스템
공유 파일 시스템은 모든 프로세스가 공유된 파일에의 접근 및 프로세스들간의 공유 파일을 조정(coordinate)하기 위해 필요합니다. 이것은 각 프로세스가 파일을 열고, 정보를 쓰고, 다른 프로세스들이 작업을 완료할 때까지 기다리게 하는 것을 뜻합니다. 필요한 모든 정보는 모든 프로세스들이 쉽게 사용할 수 있도록 합니다. 경쟁 조건(race conditions)을 피하기 위해, 파일 시스템은 반드시 fcntl 을 이용한 잠금을 지원해야 합니다.
dist.init_process_group(
init_method='file:///mnt/nfs/sharedfile',
rank=args.rank,
world_size=4)
TCP
0-순위 프로세스의 IP 주소와 접근 가능한 포트 번호가 있으면 TCP를 통한 초기화를 할 수 있습니다. 모든 워커들은 0-순위의 프로세스에 연결하고 서로 정보를 교환하는 방법에 대한 정보를 공유합니다.
dist.init_process_group(
init_method='tcp://10.1.1.20:23456',
rank=args.rank,
world_size=4)
감사의 말
PyTorch 개발자분들께 구현, 문서화 및 테스트를 잘해주신 것에 감사드립니다. 코드가 불분명할 때는 언제나 문서 또는 테스트 에서 답을 찾을 수 있었습니다. 또한 튜토리얼 초안에 대해 통찰력있는 의견과 질문에 답변을 해주신 Soumith Chintala, Adam Paszke 그리고 Natalia Gimelshei께도 감사드립니다.
