


참고
Go to the end to download the full example code.
Pendulum: Writing your environment and transforms with TorchRL#
Author: Vincent Moens
Creating an environment (a simulator or an interface to a physical control system) is an integrative part of reinforcement learning and control engineering.
TorchRL provides a set of tools to do this in multiple contexts. This tutorial demonstrates how to use PyTorch and TorchRL code a pendulum simulator from the ground up. It is freely inspired by the Pendulum-v1 implementation from OpenAI-Gym/Farama-Gymnasium control library.

Simple Pendulum#
Key learnings:
How to design an environment in TorchRL: - Writing specs (input, observation and reward); - Implementing behavior: seeding, reset and step.
Transforming your environment inputs and outputs, and writing your own transforms;
How to use
TensorDictto carry arbitrary data structures through thecodebase.In the process, we will touch three crucial components of TorchRL:
To give a sense of what can be achieved with TorchRL’s environments, we will be designing a stateless environment. While stateful environments keep track of the latest physical state encountered and rely on this to simulate the state-to-state transition, stateless environments expect the current state to be provided to them at each step, along with the action undertaken. TorchRL supports both types of environments, but stateless environments are more generic and hence cover a broader range of features of the environment API in TorchRL.
Modeling stateless environments gives users full control over the input and outputs of the simulator: one can reset an experiment at any stage or actively modify the dynamics from the outside. However, it assumes that we have some control over a task, which may not always be the case: solving a problem where we cannot control the current state is more challenging but has a much wider set of applications.
Another advantage of stateless environments is that they can enable batched execution of transition simulations. If the backend and the implementation allow it, an algebraic operation can be executed seamlessly on scalars, vectors, or tensors. This tutorial gives such examples.
This tutorial will be structured as follows:
We will first get acquainted with the environment properties: its shape (
batch_size), its methods (mainlystep(),reset()andset_seed()) and finally its specs.After having coded our simulator, we will demonstrate how it can be used during training with transforms.
We will explore new avenues that follow from the TorchRL’s API, including: the possibility of transforming inputs, the vectorized execution of the simulation and the possibility of backpropagation through the simulation graph.
Finally, we will train a simple policy to solve the system we implemented.
from collections import defaultdict
from typing import Optional
import numpy as np
import torch
import tqdm
from tensordict import TensorDict, TensorDictBase
from tensordict.nn import TensorDictModule
from torch import nn
from torchrl.data import BoundedTensorSpec, CompositeSpec, UnboundedContinuousTensorSpec
from torchrl.envs import (
CatTensors,
EnvBase,
Transform,
TransformedEnv,
UnsqueezeTransform,
)
from torchrl.envs.transforms.transforms import _apply_to_composite
from torchrl.envs.utils import check_env_specs, step_mdp
DEFAULT_X = np.pi
DEFAULT_Y = 1.0
There are four things you must take care of when designing a new environment class:
EnvBase._reset(), which codes for the resetting of the simulator at a (potentially random) initial state;EnvBase._step()which codes for the state transition dynamic;EnvBase._set_seed`()which implements the seeding mechanism;the environment specs.
Let us first describe the problem at hand: we would like to model a simple pendulum over which we can control the torque applied on its fixed point. Our goal is to place the pendulum in upward position (angular position at 0 by convention) and having it standing still in that position. To design our dynamic system, we need to define two equations: the motion equation following an action (the torque applied) and the reward equation that will constitute our objective function.
For the motion equation, we will update the angular velocity following:
where \(\dot{\theta}\) is the angular velocity in rad/sec, \(g\) is the gravitational force, \(L\) is the pendulum length, \(m\) is its mass, \(\theta\) is its angular position and \(u\) is the torque. The angular position is then updated according to
We define our reward as
which will be maximized when the angle is close to 0 (pendulum in upward position), the angular velocity is close to 0 (no motion) and the torque is 0 too.
Coding the effect of an action: _step()#
The step method is the first thing to consider, as it will encode
the simulation that is of interest to us. In TorchRL, the
EnvBase class has a EnvBase.step()
method that receives a tensordict.TensorDict
instance with an "action" entry indicating what action is to be taken.
To facilitate the reading and writing from that tensordict and to make sure
that the keys are consistent with what’s expected from the library, the
simulation part has been delegated to a private abstract method _step()
which reads input data from a tensordict, and writes a new tensordict
with the output data.
The _step() method should do the following:
Read the input keys (such as
"action") and execute the simulation based on these;Retrieve observations, done state and reward;
Write the set of observation values along with the reward and done state at the corresponding entries in a new
TensorDict.
Next, the step() method will merge the output
of step() in the input tensordict to enforce
input/output consistency.
Typically, for stateful environments, this will look like this:
>>> policy(env.reset())
>>> print(tensordict)
TensorDict(
fields={
action: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=cpu,
is_shared=False)
>>> env.step(tensordict)
>>> print(tensordict)
TensorDict(
fields={
action: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=cpu,
is_shared=False),
observation: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=cpu,
is_shared=False)
Notice that the root tensordict has not changed, the only modification is the
appearance of a new "next" entry that contains the new information.
In the Pendulum example, our _step() method will read the relevant
entries from the input tensordict and compute the position and velocity of
the pendulum after the force encoded by the "action" key has been applied
onto it. We compute the new angular position of the pendulum
"new_th" as the result of the previous position "th" plus the new
velocity "new_thdot" over a time interval dt.
Since our goal is to turn the pendulum up and maintain it still in that
position, our cost (negative reward) function is lower for positions
close to the target and low speeds.
Indeed, we want to discourage positions that are far from being “upward”
and/or speeds that are far from 0.
In our example, EnvBase._step() is encoded as a static method since our
environment is stateless. In stateful settings, the self argument is
needed as the state needs to be read from the environment.
def _step(tensordict):
th, thdot = tensordict["th"], tensordict["thdot"] # th := theta
g_force = tensordict["params", "g"]
mass = tensordict["params", "m"]
length = tensordict["params", "l"]
dt = tensordict["params", "dt"]
u = tensordict["action"].squeeze(-1)
u = u.clamp(-tensordict["params", "max_torque"], tensordict["params", "max_torque"])
costs = angle_normalize(th) ** 2 + 0.1 * thdot**2 + 0.001 * (u**2)
new_thdot = (
thdot
+ (3 * g_force / (2 * length) * th.sin() + 3.0 / (mass * length**2) * u) * dt
)
new_thdot = new_thdot.clamp(
-tensordict["params", "max_speed"], tensordict["params", "max_speed"]
)
new_th = th + new_thdot * dt
reward = -costs.view(*tensordict.shape, 1)
done = torch.zeros_like(reward, dtype=torch.bool)
out = TensorDict(
{
"th": new_th,
"thdot": new_thdot,
"params": tensordict["params"],
"reward": reward,
"done": done,
},
tensordict.shape,
)
return out
def angle_normalize(x):
return ((x + torch.pi) % (2 * torch.pi)) - torch.pi
Resetting the simulator: _reset()#
The second method we need to care about is the
_reset() method. Like
_step(), it should write the observation entries
and possibly a done state in the tensordict it outputs (if the done state is
omitted, it will be filled as False by the parent method
reset()). In some contexts, it is required that
the _reset method receives a command from the function that called
it (for example, in multi-agent settings we may want to indicate which agents need
to be reset). This is why the _reset() method
also expects a tensordict as input, albeit it may perfectly be empty or
None.
The parent EnvBase.reset() does some simple checks like the
EnvBase.step() does, such as making sure that a "done" state
is returned in the output tensordict and that the shapes match what is
expected from the specs.
For us, the only important thing to consider is whether
EnvBase._reset() contains all the expected observations. Once more,
since we are working with a stateless environment, we pass the configuration
of the pendulum in a nested tensordict named "params".
In this example, we do not pass a done state as this is not mandatory
for _reset() and our environment is non-terminating, so we always
expect it to be False.
def _reset(self, tensordict):
if tensordict is None or tensordict.is_empty():
# if no ``tensordict`` is passed, we generate a single set of hyperparameters
# Otherwise, we assume that the input ``tensordict`` contains all the relevant
# parameters to get started.
tensordict = self.gen_params(batch_size=self.batch_size)
high_th = torch.tensor(DEFAULT_X, device=self.device)
high_thdot = torch.tensor(DEFAULT_Y, device=self.device)
low_th = -high_th
low_thdot = -high_thdot
# for non batch-locked environments, the input ``tensordict`` shape dictates the number
# of simulators run simultaneously. In other contexts, the initial
# random state's shape will depend upon the environment batch-size instead.
th = (
torch.rand(tensordict.shape, generator=self.rng, device=self.device)
* (high_th - low_th)
+ low_th
)
thdot = (
torch.rand(tensordict.shape, generator=self.rng, device=self.device)
* (high_thdot - low_thdot)
+ low_thdot
)
out = TensorDict(
{
"th": th,
"thdot": thdot,
"params": tensordict["params"],
},
batch_size=tensordict.shape,
)
return out
Environment metadata: env.*_spec#
The specs define the input and output domain of the environment. It is important that the specs accurately define the tensors that will be received at runtime, as they are often used to carry information about environments in multiprocessing and distributed settings. They can also be used to instantiate lazily defined neural networks and test scripts without actually querying the environment (which can be costly with real-world physical systems for instance).
There are four specs that we must code in our environment:
EnvBase.observation_spec: This will be aCompositeSpecinstance where each key is an observation (aCompositeSpeccan be viewed as a dictionary of specs).EnvBase.action_spec: It can be any type of spec, but it is required that it corresponds to the"action"entry in the inputtensordict;EnvBase.reward_spec: provides information about the reward space;EnvBase.done_spec: provides information about the space of the done flag.
TorchRL specs are organized in two general containers: input_spec which
contains the specs of the information that the step function reads (divided
between action_spec containing the action and state_spec containing
all the rest), and output_spec which encodes the specs that the
step outputs (observation_spec, reward_spec and done_spec).
In general, you should not interact directly with output_spec and
input_spec but only with their content: observation_spec,
reward_spec, done_spec, action_spec and state_spec.
The reason if that the specs are organized in a non-trivial way
within output_spec and
input_spec and neither of these should be directly modified.
In other words, the observation_spec and related properties are
convenient shortcuts to the content of the output and input spec containers.
TorchRL offers multiple TensorSpec
subclasses to
encode the environment’s input and output characteristics.
Specs shape#
The environment specs leading dimensions must match the environment batch-size. This is done to enforce that every component of an environment (including its transforms) have an accurate representation of the expected input and output shapes. This is something that should be accurately coded in stateful settings.
For non batch-locked environments, such as the one in our example (see below), this is irrelevant as the environment batch size will most likely be empty.
def _make_spec(self, td_params):
# Under the hood, this will populate self.output_spec["observation"]
self.observation_spec = CompositeSpec(
th=BoundedTensorSpec(
low=-torch.pi,
high=torch.pi,
shape=(),
dtype=torch.float32,
),
thdot=BoundedTensorSpec(
low=-td_params["params", "max_speed"],
high=td_params["params", "max_speed"],
shape=(),
dtype=torch.float32,
),
# we need to add the ``params`` to the observation specs, as we want
# to pass it at each step during a rollout
params=make_composite_from_td(td_params["params"]),
shape=(),
)
# since the environment is stateless, we expect the previous output as input.
# For this, ``EnvBase`` expects some state_spec to be available
self.state_spec = self.observation_spec.clone()
# action-spec will be automatically wrapped in input_spec when
# `self.action_spec = spec` will be called supported
self.action_spec = BoundedTensorSpec(
low=-td_params["params", "max_torque"],
high=td_params["params", "max_torque"],
shape=(1,),
dtype=torch.float32,
)
self.reward_spec = UnboundedContinuousTensorSpec(shape=(*td_params.shape, 1))
def make_composite_from_td(td):
# custom function to convert a ``tensordict`` in a similar spec structure
# of unbounded values.
composite = CompositeSpec(
{
key: make_composite_from_td(tensor)
if isinstance(tensor, TensorDictBase)
else UnboundedContinuousTensorSpec(
dtype=tensor.dtype, device=tensor.device, shape=tensor.shape
)
for key, tensor in td.items()
},
shape=td.shape,
)
return composite
Reproducible experiments: seeding#
Seeding an environment is a common operation when initializing an experiment.
The only goal of EnvBase._set_seed() is to set the seed of the contained
simulator. If possible, this operation should not call reset() or interact
with the environment execution. The parent EnvBase.set_seed() method
incorporates a mechanism that allows seeding multiple environments with a
different pseudo-random and reproducible seed.
def _set_seed(self, seed: Optional[int]):
rng = torch.manual_seed(seed)
self.rng = rng
Wrapping things together: the EnvBase class#
We can finally put together the pieces and design our environment class.
The specs initialization needs to be performed during the environment
construction, so we must take care of calling the _make_spec() method
within PendulumEnv.__init__().
We add a static method PendulumEnv.gen_params() which deterministically
generates a set of hyperparameters to be used during execution:
def gen_params(g=10.0, batch_size=None) -> TensorDictBase:
"""Returns a ``tensordict`` containing the physical parameters such as gravitational force and torque or speed limits."""
if batch_size is None:
batch_size = []
td = TensorDict(
{
"params": TensorDict(
{
"max_speed": 8,
"max_torque": 2.0,
"dt": 0.05,
"g": g,
"m": 1.0,
"l": 1.0,
},
[],
)
},
[],
)
if batch_size:
td = td.expand(batch_size).contiguous()
return td
We define the environment as non-batch_locked by turning the homonymous
attribute to False. This means that we will not enforce the input
tensordict to have a batch-size that matches the one of the environment.
The following code will just put together the pieces we have coded above.
class PendulumEnv(EnvBase):
metadata = {
"render_modes": ["human", "rgb_array"],
"render_fps": 30,
}
batch_locked = False
def __init__(self, td_params=None, seed=None, device="cpu"):
if td_params is None:
td_params = self.gen_params()
super().__init__(device=device, batch_size=[])
self._make_spec(td_params)
if seed is None:
seed = torch.empty((), dtype=torch.int64).random_().item()
self.set_seed(seed)
# Helpers: _make_step and gen_params
gen_params = staticmethod(gen_params)
_make_spec = _make_spec
# Mandatory methods: _step, _reset and _set_seed
_reset = _reset
_step = staticmethod(_step)
_set_seed = _set_seed
Testing our environment#
TorchRL provides a simple function check_env_specs()
to check that a (transformed) environment has an input/output structure that
matches the one dictated by its specs.
Let us try it out:
env = PendulumEnv()
check_env_specs(env)
/opt/conda/lib/python3.11/site-packages/torchrl/data/tensor_specs.py:6911: DeprecationWarning:
The BoundedTensorSpec has been deprecated and will be removed in v0.8. Please use Bounded instead.
/opt/conda/lib/python3.11/site-packages/torchrl/data/tensor_specs.py:6911: DeprecationWarning:
The UnboundedContinuousTensorSpec has been deprecated and will be removed in v0.8. Please use Unbounded instead.
/opt/conda/lib/python3.11/site-packages/torchrl/data/tensor_specs.py:6911: DeprecationWarning:
The CompositeSpec has been deprecated and will be removed in v0.8. Please use Composite instead.
2025-10-04 00:36:17,500 [torchrl][INFO] check_env_specs succeeded! [END]
We can have a look at our specs to have a visual representation of the environment signature:
print("observation_spec:", env.observation_spec)
print("state_spec:", env.state_spec)
print("reward_spec:", env.reward_spec)
observation_spec: CompositeSpec(
th: BoundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
thdot: BoundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
params: CompositeSpec(
max_speed: UnboundedDiscrete(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, contiguous=True)),
device=cpu,
dtype=torch.int64,
domain=discrete),
max_torque: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
dt: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
g: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
m: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
l: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([]),
data_cls=None),
device=cpu,
shape=torch.Size([]),
data_cls=None)
state_spec: CompositeSpec(
th: BoundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
thdot: BoundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
params: CompositeSpec(
max_speed: UnboundedDiscrete(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, contiguous=True)),
device=cpu,
dtype=torch.int64,
domain=discrete),
max_torque: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
dt: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
g: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
m: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
l: UnboundedContinuous(
shape=torch.Size([]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([]),
data_cls=None),
device=cpu,
shape=torch.Size([]),
data_cls=None)
reward_spec: UnboundedContinuous(
shape=torch.Size([1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous)
We can execute a couple of commands too to check that the output structure matches what is expected.
td = env.reset()
print("reset tensordict", td)
reset tensordict TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
We can run the env.rand_step() to generate
an action randomly from the action_spec domain. A tensordict containing
the hyperparameters and the current state must be passed since our
environment is stateless. In stateful contexts, env.rand_step() works
perfectly too.
td = env.rand_step(td)
print("random step tensordict", td)
random step tensordict TensorDict(
fields={
action: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False),
reward: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
Transforming an environment#
Writing environment transforms for stateless simulators is slightly more
complicated than for stateful ones: transforming an output entry that needs
to be read at the following iteration requires to apply the inverse transform
before calling meth.step() at the next step.
This is an ideal scenario to showcase all the features of TorchRL’s
transforms!
For instance, in the following transformed environment we unsqueeze the entries
["th", "thdot"] to be able to stack them along the last
dimension. We also pass them as in_keys_inv to squeeze them back to their
original shape once they are passed as input in the next iteration.
env = TransformedEnv(
env,
# ``Unsqueeze`` the observations that we will concatenate
UnsqueezeTransform(
dim=-1,
in_keys=["th", "thdot"],
in_keys_inv=["th", "thdot"],
),
)
Writing custom transforms#
TorchRL’s transforms may not cover all the operations one wants to execute after an environment has been executed. Writing a transform does not require much effort. As for the environment design, there are two steps in writing a transform:
Getting the dynamics right (forward and inverse);
Adapting the environment specs.
A transform can be used in two settings: on its own, it can be used as a
Module. It can also be used appended to a
TransformedEnv. The structure of the class allows to
customize the behavior in the different contexts.
A Transform skeleton can be summarized as follows:
class Transform(nn.Module):
def forward(self, tensordict):
...
def _apply_transform(self, tensordict):
...
def _step(self, tensordict):
...
def _call(self, tensordict):
...
def inv(self, tensordict):
...
def _inv_apply_transform(self, tensordict):
...
There are three entry points (forward(), _step() and inv())
which all receive tensordict.TensorDict instances. The first two
will eventually go through the keys indicated by in_keys
and call _apply_transform() to each of these. The results will
be written in the entries pointed by Transform.out_keys if provided
(if not the in_keys will be updated with the transformed values).
If inverse transforms need to be executed, a similar data flow will be
executed but with the Transform.inv() and
Transform._inv_apply_transform() methods and across the in_keys_inv
and out_keys_inv list of keys.
The following figure summarized this flow for environments and replay
buffers.
Transform API
In some cases, a transform will not work on a subset of keys in a unitary
manner, but will execute some operation on the parent environment or
work with the entire input tensordict.
In those cases, the _call() and forward() methods should be
re-written, and the _apply_transform() method can be skipped.
Let us code new transforms that will compute the sine and cosine
values of the position angle, as these values are more useful to us to learn
a policy than the raw angle value:
class SinTransform(Transform):
def _apply_transform(self, obs: torch.Tensor) -> None:
return obs.sin()
# The transform must also modify the data at reset time
def _reset(
self, tensordict: TensorDictBase, tensordict_reset: TensorDictBase
) -> TensorDictBase:
return self._call(tensordict_reset)
# _apply_to_composite will execute the observation spec transform across all
# in_keys/out_keys pairs and write the result in the observation_spec which
# is of type ``Composite``
@_apply_to_composite
def transform_observation_spec(self, observation_spec):
return BoundedTensorSpec(
low=-1,
high=1,
shape=observation_spec.shape,
dtype=observation_spec.dtype,
device=observation_spec.device,
)
class CosTransform(Transform):
def _apply_transform(self, obs: torch.Tensor) -> None:
return obs.cos()
# The transform must also modify the data at reset time
def _reset(
self, tensordict: TensorDictBase, tensordict_reset: TensorDictBase
) -> TensorDictBase:
return self._call(tensordict_reset)
# _apply_to_composite will execute the observation spec transform across all
# in_keys/out_keys pairs and write the result in the observation_spec which
# is of type ``Composite``
@_apply_to_composite
def transform_observation_spec(self, observation_spec):
return BoundedTensorSpec(
low=-1,
high=1,
shape=observation_spec.shape,
dtype=observation_spec.dtype,
device=observation_spec.device,
)
t_sin = SinTransform(in_keys=["th"], out_keys=["sin"])
t_cos = CosTransform(in_keys=["th"], out_keys=["cos"])
env.append_transform(t_sin)
env.append_transform(t_cos)
TransformedEnv(
env=PendulumEnv(),
transform=Compose(
UnsqueezeTransform(dim=-1, in_keys=['th', 'thdot'], out_keys=['th', 'thdot'], in_keys_inv=['th', 'thdot'], out_keys_inv=['th', 'thdot']),
SinTransform(keys=['th']),
CosTransform(keys=['th'])))
Concatenates the observations onto an “observation” entry.
del_keys=False ensures that we keep these values for the next
iteration.
cat_transform = CatTensors(
in_keys=["sin", "cos", "thdot"], dim=-1, out_key="observation", del_keys=False
)
env.append_transform(cat_transform)
TransformedEnv(
env=PendulumEnv(),
transform=Compose(
UnsqueezeTransform(dim=-1, in_keys=['th', 'thdot'], out_keys=['th', 'thdot'], in_keys_inv=['th', 'thdot'], out_keys_inv=['th', 'thdot']),
SinTransform(keys=['th']),
CosTransform(keys=['th']),
CatTensors(in_keys=['cos', 'sin', 'thdot'], out_key=observation)))
Once more, let us check that our environment specs match what is received:
check_env_specs(env)
2025-10-04 00:36:17,522 [torchrl][INFO] check_env_specs succeeded! [END]
Executing a rollout#
Executing a rollout is a succession of simple steps:
reset the environment
while some condition is not met:
compute an action given a policy
execute a step given this action
collect the data
make a
MDPstep
gather the data and return
These operations have been conveniently wrapped in the rollout()
method, from which we provide a simplified version here below.
def simple_rollout(steps=100):
# preallocate:
data = TensorDict({}, [steps])
# reset
_data = env.reset()
for i in range(steps):
_data["action"] = env.action_spec.rand()
_data = env.step(_data)
data[i] = _data
_data = step_mdp(_data, keep_other=True)
return data
print("data from rollout:", simple_rollout(100))
data from rollout: TensorDict(
fields={
action: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),
cos: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
cos: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([100, 3]), device=cpu, dtype=torch.float32, is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([100]),
device=None,
is_shared=False),
reward: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),
sin: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([100]),
device=None,
is_shared=False),
observation: Tensor(shape=torch.Size([100, 3]), device=cpu, dtype=torch.float32, is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([100]),
device=None,
is_shared=False),
sin: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([100]),
device=None,
is_shared=False)
Batching computations#
The last unexplored end of our tutorial is the ability that we have to batch computations in TorchRL. Because our environment does not make any assumptions regarding the input data shape, we can seamlessly execute it over batches of data. Even better: for non-batch-locked environments such as our Pendulum, we can change the batch size on the fly without recreating the environment. To do this, we just generate parameters with the desired shape.
batch_size = 10 # number of environments to be executed in batch
td = env.reset(env.gen_params(batch_size=[batch_size]))
print("reset (batch size of 10)", td)
td = env.rand_step(td)
print("rand step (batch size of 10)", td)
reset (batch size of 10) TensorDict(
fields={
cos: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10]),
device=None,
is_shared=False),
sin: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10]),
device=None,
is_shared=False)
rand step (batch size of 10) TensorDict(
fields={
action: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
cos: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
cos: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10]),
device=None,
is_shared=False),
reward: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
sin: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10]),
device=None,
is_shared=False),
observation: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10]),
device=None,
is_shared=False),
sin: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10]),
device=None,
is_shared=False)
Executing a rollout with a batch of data requires us to reset the environment
out of the rollout function, since we need to define the batch_size
dynamically and this is not supported by rollout():
rollout = env.rollout(
3,
auto_reset=False, # we're executing the reset out of the ``rollout`` call
tensordict=env.reset(env.gen_params(batch_size=[batch_size])),
)
print("rollout of len 3 (batch size of 10):", rollout)
rollout of len 3 (batch size of 10): TensorDict(
fields={
action: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
cos: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
cos: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([10, 3, 3]), device=cpu, dtype=torch.float32, is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 3]),
device=None,
is_shared=False),
reward: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
sin: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 3]),
device=None,
is_shared=False),
observation: Tensor(shape=torch.Size([10, 3, 3]), device=cpu, dtype=torch.float32, is_shared=False),
params: TensorDict(
fields={
dt: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
g: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
l: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
m: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
max_speed: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.int64, is_shared=False),
max_torque: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 3]),
device=None,
is_shared=False),
sin: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
th: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
thdot: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 3]),
device=None,
is_shared=False)
Training a simple policy#
In this example, we will train a simple policy using the reward as a differentiable objective, such as a negative loss. We will take advantage of the fact that our dynamic system is fully differentiable to backpropagate through the trajectory return and adjust the weights of our policy to maximize this value directly. Of course, in many settings many of the assumptions we make do not hold, such as differentiable system and full access to the underlying mechanics.
Still, this is a very simple example that showcases how a training loop can be coded with a custom environment in TorchRL.
Let us first write the policy network:
torch.manual_seed(0)
env.set_seed(0)
net = nn.Sequential(
nn.LazyLinear(64),
nn.Tanh(),
nn.LazyLinear(64),
nn.Tanh(),
nn.LazyLinear(64),
nn.Tanh(),
nn.LazyLinear(1),
)
policy = TensorDictModule(
net,
in_keys=["observation"],
out_keys=["action"],
)
and our optimizer:
optim = torch.optim.Adam(policy.parameters(), lr=2e-3)
Training loop#
We will successively:
generate a trajectory
sum the rewards
backpropagate through the graph defined by these operations
clip the gradient norm and make an optimization step
repeat
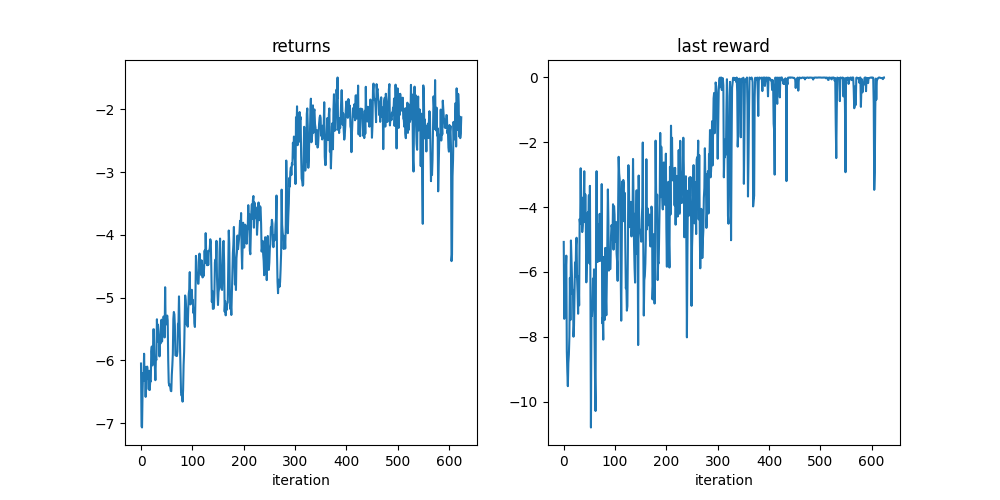
At the end of the training loop, we should have a final reward close to 0 which demonstrates that the pendulum is upward and still as desired.
batch_size = 32
pbar = tqdm.tqdm(range(20_000 // batch_size))
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optim, 20_000)
logs = defaultdict(list)
for _ in pbar:
init_td = env.reset(env.gen_params(batch_size=[batch_size]))
rollout = env.rollout(100, policy, tensordict=init_td, auto_reset=False)
traj_return = rollout["next", "reward"].mean()
(-traj_return).backward()
gn = torch.nn.utils.clip_grad_norm_(net.parameters(), 1.0)
optim.step()
optim.zero_grad()
pbar.set_description(
f"reward: {traj_return: 4.4f}, "
f"last reward: {rollout[..., -1]['next', 'reward'].mean(): 4.4f}, gradient norm: {gn: 4.4}"
)
logs["return"].append(traj_return.item())
logs["last_reward"].append(rollout[..., -1]["next", "reward"].mean().item())
scheduler.step()
def plot():
import matplotlib
from matplotlib import pyplot as plt
is_ipython = "inline" in matplotlib.get_backend()
if is_ipython:
from IPython import display
with plt.ion():
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(logs["return"])
plt.title("returns")
plt.xlabel("iteration")
plt.subplot(1, 2, 2)
plt.plot(logs["last_reward"])
plt.title("last reward")
plt.xlabel("iteration")
if is_ipython:
display.display(plt.gcf())
display.clear_output(wait=True)
plt.show()
plot()
0%| | 0/625 [00:00<?, ?it/s]
reward: -6.0488, last reward: -5.0748, gradient norm: 8.519: 0%| | 0/625 [00:04<?, ?it/s]
reward: -6.0488, last reward: -5.0748, gradient norm: 8.519: 0%| | 1/625 [00:04<45:04, 4.33s/it]
reward: -7.0499, last reward: -7.4472, gradient norm: 5.073: 0%| | 1/625 [00:04<45:04, 4.33s/it]
reward: -7.0499, last reward: -7.4472, gradient norm: 5.073: 0%| | 2/625 [00:04<19:24, 1.87s/it]
reward: -7.0685, last reward: -7.0408, gradient norm: 5.552: 0%| | 2/625 [00:04<19:24, 1.87s/it]
reward: -7.0685, last reward: -7.0408, gradient norm: 5.552: 0%| | 3/625 [00:04<11:12, 1.08s/it]
reward: -6.5154, last reward: -5.9086, gradient norm: 2.527: 0%| | 3/625 [00:04<11:12, 1.08s/it]
reward: -6.5154, last reward: -5.9086, gradient norm: 2.527: 1%| | 4/625 [00:04<07:20, 1.41it/s]
reward: -6.2005, last reward: -5.9391, gradient norm: 8.096: 1%| | 4/625 [00:04<07:20, 1.41it/s]
reward: -6.2005, last reward: -5.9391, gradient norm: 8.096: 1%| | 5/625 [00:04<05:12, 1.98it/s]
reward: -6.2567, last reward: -5.4982, gradient norm: 6.13: 1%| | 5/625 [00:05<05:12, 1.98it/s]
reward: -6.2567, last reward: -5.4982, gradient norm: 6.13: 1%| | 6/625 [00:05<03:56, 2.62it/s]
reward: -5.8929, last reward: -8.4489, gradient norm: 4.668: 1%| | 6/625 [00:05<03:56, 2.62it/s]
reward: -5.8929, last reward: -8.4489, gradient norm: 4.668: 1%| | 7/625 [00:05<03:07, 3.30it/s]
reward: -6.3233, last reward: -9.0661, gradient norm: 7.557: 1%| | 7/625 [00:05<03:07, 3.30it/s]
reward: -6.3233, last reward: -9.0661, gradient norm: 7.557: 1%|▏ | 8/625 [00:05<02:34, 3.98it/s]
reward: -6.1021, last reward: -9.5295, gradient norm: 1.024: 1%|▏ | 8/625 [00:05<02:34, 3.98it/s]
reward: -6.1021, last reward: -9.5295, gradient norm: 1.024: 1%|▏ | 9/625 [00:05<02:13, 4.62it/s]
reward: -6.5926, last reward: -8.6254, gradient norm: 9.297: 1%|▏ | 9/625 [00:05<02:13, 4.62it/s]
reward: -6.5926, last reward: -8.6254, gradient norm: 9.297: 2%|▏ | 10/625 [00:05<01:58, 5.19it/s]
reward: -6.1367, last reward: -8.8877, gradient norm: 4.069: 2%|▏ | 10/625 [00:05<01:58, 5.19it/s]
reward: -6.1367, last reward: -8.8877, gradient norm: 4.069: 2%|▏ | 11/625 [00:05<01:48, 5.65it/s]
reward: -6.2312, last reward: -7.6748, gradient norm: 2.039: 2%|▏ | 11/625 [00:05<01:48, 5.65it/s]
reward: -6.2312, last reward: -7.6748, gradient norm: 2.039: 2%|▏ | 12/625 [00:05<01:41, 6.03it/s]
reward: -5.7494, last reward: -7.0333, gradient norm: 32.67: 2%|▏ | 12/625 [00:06<01:41, 6.03it/s]
reward: -5.7494, last reward: -7.0333, gradient norm: 32.67: 2%|▏ | 13/625 [00:06<01:36, 6.33it/s]
reward: -5.8780, last reward: -6.7692, gradient norm: 2.119: 2%|▏ | 13/625 [00:06<01:36, 6.33it/s]
reward: -5.8780, last reward: -6.7692, gradient norm: 2.119: 2%|▏ | 14/625 [00:06<01:33, 6.55it/s]
reward: -5.9842, last reward: -5.6329, gradient norm: 0.628: 2%|▏ | 14/625 [00:06<01:33, 6.55it/s]
reward: -5.9842, last reward: -5.6329, gradient norm: 0.628: 2%|▏ | 15/625 [00:06<01:31, 6.70it/s]
reward: -5.9927, last reward: -5.5757, gradient norm: 1.272: 2%|▏ | 15/625 [00:06<01:31, 6.70it/s]
reward: -5.9927, last reward: -5.5757, gradient norm: 1.272: 3%|▎ | 16/625 [00:06<01:29, 6.83it/s]
reward: -5.7565, last reward: -5.0100, gradient norm: 8.952: 3%|▎ | 16/625 [00:06<01:29, 6.83it/s]
reward: -5.7565, last reward: -5.0100, gradient norm: 8.952: 3%|▎ | 17/625 [00:06<01:27, 6.93it/s]
reward: -5.8828, last reward: -4.5851, gradient norm: 40.48: 3%|▎ | 17/625 [00:06<01:27, 6.93it/s]
reward: -5.8828, last reward: -4.5851, gradient norm: 40.48: 3%|▎ | 18/625 [00:06<01:27, 6.96it/s]
reward: -6.0570, last reward: -6.7479, gradient norm: 1.231: 3%|▎ | 18/625 [00:06<01:27, 6.96it/s]
reward: -6.0570, last reward: -6.7479, gradient norm: 1.231: 3%|▎ | 19/625 [00:06<01:26, 7.01it/s]
reward: -6.1003, last reward: -7.8772, gradient norm: 7.884: 3%|▎ | 19/625 [00:07<01:26, 7.01it/s]
reward: -6.1003, last reward: -7.8772, gradient norm: 7.884: 3%|▎ | 20/625 [00:07<01:25, 7.06it/s]
reward: -5.7835, last reward: -8.1054, gradient norm: 35.61: 3%|▎ | 20/625 [00:07<01:25, 7.06it/s]
reward: -5.7835, last reward: -8.1054, gradient norm: 35.61: 3%|▎ | 21/625 [00:07<01:25, 7.09it/s]
reward: -5.7974, last reward: -7.8339, gradient norm: 2.974: 3%|▎ | 21/625 [00:07<01:25, 7.09it/s]
reward: -5.7974, last reward: -7.8339, gradient norm: 2.974: 4%|▎ | 22/625 [00:07<01:24, 7.12it/s]
reward: -6.1059, last reward: -5.7898, gradient norm: 3.001: 4%|▎ | 22/625 [00:07<01:24, 7.12it/s]
reward: -6.1059, last reward: -5.7898, gradient norm: 3.001: 4%|▎ | 23/625 [00:07<01:24, 7.13it/s]
reward: -5.8832, last reward: -3.8373, gradient norm: 3.189: 4%|▎ | 23/625 [00:07<01:24, 7.13it/s]
reward: -5.8832, last reward: -3.8373, gradient norm: 3.189: 4%|▍ | 24/625 [00:07<01:24, 7.13it/s]
reward: -5.4333, last reward: -3.6399, gradient norm: 12.32: 4%|▍ | 24/625 [00:07<01:24, 7.13it/s]
reward: -5.4333, last reward: -3.6399, gradient norm: 12.32: 4%|▍ | 25/625 [00:07<01:24, 7.13it/s]
reward: -5.2744, last reward: -5.8030, gradient norm: 8.743: 4%|▍ | 25/625 [00:07<01:24, 7.13it/s]
reward: -5.2744, last reward: -5.8030, gradient norm: 8.743: 4%|▍ | 26/625 [00:07<01:23, 7.14it/s]
reward: -5.4789, last reward: -6.0665, gradient norm: 7.545: 4%|▍ | 26/625 [00:07<01:23, 7.14it/s]
reward: -5.4789, last reward: -6.0665, gradient norm: 7.545: 4%|▍ | 27/625 [00:07<01:23, 7.14it/s]
reward: -5.8750, last reward: -6.3080, gradient norm: 10.57: 4%|▍ | 27/625 [00:08<01:23, 7.14it/s]
reward: -5.8750, last reward: -6.3080, gradient norm: 10.57: 4%|▍ | 28/625 [00:08<01:23, 7.14it/s]
reward: -6.3506, last reward: -6.9020, gradient norm: 8.721: 4%|▍ | 28/625 [00:08<01:23, 7.14it/s]
reward: -6.3506, last reward: -6.9020, gradient norm: 8.721: 5%|▍ | 29/625 [00:08<01:23, 7.14it/s]
reward: -6.2083, last reward: -6.5863, gradient norm: 10.54: 5%|▍ | 29/625 [00:08<01:23, 7.14it/s]
reward: -6.2083, last reward: -6.5863, gradient norm: 10.54: 5%|▍ | 30/625 [00:08<01:23, 7.14it/s]
reward: -6.3064, last reward: -6.8039, gradient norm: 10.47: 5%|▍ | 30/625 [00:08<01:23, 7.14it/s]
reward: -6.3064, last reward: -6.8039, gradient norm: 10.47: 5%|▍ | 31/625 [00:08<01:23, 7.13it/s]
reward: -5.3703, last reward: -5.5340, gradient norm: 5.564: 5%|▍ | 31/625 [00:08<01:23, 7.13it/s]
reward: -5.3703, last reward: -5.5340, gradient norm: 5.564: 5%|▌ | 32/625 [00:08<01:23, 7.13it/s]
reward: -5.6747, last reward: -6.1149, gradient norm: 20.85: 5%|▌ | 32/625 [00:08<01:23, 7.13it/s]
reward: -5.6747, last reward: -6.1149, gradient norm: 20.85: 5%|▌ | 33/625 [00:08<01:22, 7.14it/s]
reward: -5.3326, last reward: -6.2306, gradient norm: 5.05: 5%|▌ | 33/625 [00:08<01:22, 7.14it/s]
reward: -5.3326, last reward: -6.2306, gradient norm: 5.05: 5%|▌ | 34/625 [00:08<01:22, 7.13it/s]
reward: -5.3413, last reward: -6.4420, gradient norm: 37.63: 5%|▌ | 34/625 [00:09<01:22, 7.13it/s]
reward: -5.3413, last reward: -6.4420, gradient norm: 37.63: 6%|▌ | 35/625 [00:09<01:22, 7.14it/s]
reward: -5.6808, last reward: -8.3004, gradient norm: 8.277: 6%|▌ | 35/625 [00:09<01:22, 7.14it/s]
reward: -5.6808, last reward: -8.3004, gradient norm: 8.277: 6%|▌ | 36/625 [00:09<01:22, 7.14it/s]
reward: -6.1140, last reward: -6.4290, gradient norm: 8.73: 6%|▌ | 36/625 [00:09<01:22, 7.14it/s]
reward: -6.1140, last reward: -6.4290, gradient norm: 8.73: 6%|▌ | 37/625 [00:09<01:22, 7.13it/s]
reward: -5.4735, last reward: -5.5109, gradient norm: 2.201: 6%|▌ | 37/625 [00:09<01:22, 7.13it/s]
reward: -5.4735, last reward: -5.5109, gradient norm: 2.201: 6%|▌ | 38/625 [00:09<01:22, 7.13it/s]
reward: -5.8166, last reward: -6.1235, gradient norm: 6.908: 6%|▌ | 38/625 [00:09<01:22, 7.13it/s]
reward: -5.8166, last reward: -6.1235, gradient norm: 6.908: 6%|▌ | 39/625 [00:09<01:22, 7.13it/s]
reward: -5.3274, last reward: -5.3025, gradient norm: 9.831: 6%|▌ | 39/625 [00:09<01:22, 7.13it/s]
reward: -5.3274, last reward: -5.3025, gradient norm: 9.831: 6%|▋ | 40/625 [00:09<01:35, 6.12it/s]
reward: -5.0601, last reward: -5.2504, gradient norm: 4.193: 6%|▋ | 40/625 [00:10<01:35, 6.12it/s]
reward: -5.0601, last reward: -5.2504, gradient norm: 4.193: 7%|▋ | 41/625 [00:10<01:31, 6.39it/s]
reward: -5.5363, last reward: -6.3518, gradient norm: 15.07: 7%|▋ | 41/625 [00:10<01:31, 6.39it/s]
reward: -5.5363, last reward: -6.3518, gradient norm: 15.07: 7%|▋ | 42/625 [00:10<01:28, 6.58it/s]
reward: -5.4973, last reward: -4.8868, gradient norm: 43.55: 7%|▋ | 42/625 [00:10<01:28, 6.58it/s]
reward: -5.4973, last reward: -4.8868, gradient norm: 43.55: 7%|▋ | 43/625 [00:10<01:26, 6.73it/s]
reward: -5.2835, last reward: -4.7143, gradient norm: 2.655: 7%|▋ | 43/625 [00:10<01:26, 6.73it/s]
reward: -5.2835, last reward: -4.7143, gradient norm: 2.655: 7%|▋ | 44/625 [00:10<01:24, 6.85it/s]
reward: -5.1445, last reward: -4.1563, gradient norm: 2.266: 7%|▋ | 44/625 [00:10<01:24, 6.85it/s]
reward: -5.1445, last reward: -4.1563, gradient norm: 2.266: 7%|▋ | 45/625 [00:10<01:23, 6.92it/s]
reward: -5.3967, last reward: -4.9775, gradient norm: 34.8: 7%|▋ | 45/625 [00:10<01:23, 6.92it/s]
reward: -5.3967, last reward: -4.9775, gradient norm: 34.8: 7%|▋ | 46/625 [00:10<01:22, 6.99it/s]
reward: -5.6103, last reward: -4.3586, gradient norm: 32.3: 7%|▋ | 46/625 [00:10<01:22, 6.99it/s]
reward: -5.6103, last reward: -4.3586, gradient norm: 32.3: 8%|▊ | 47/625 [00:10<01:22, 7.02it/s]
reward: -4.8184, last reward: -3.6925, gradient norm: 13.33: 8%|▊ | 47/625 [00:11<01:22, 7.02it/s]
reward: -4.8184, last reward: -3.6925, gradient norm: 13.33: 8%|▊ | 48/625 [00:11<01:21, 7.04it/s]
reward: -5.3193, last reward: -4.3483, gradient norm: 63.99: 8%|▊ | 48/625 [00:11<01:21, 7.04it/s]
reward: -5.3193, last reward: -4.3483, gradient norm: 63.99: 8%|▊ | 49/625 [00:11<01:21, 7.04it/s]
reward: -5.4449, last reward: -4.0652, gradient norm: 4.889: 8%|▊ | 49/625 [00:11<01:21, 7.04it/s]
reward: -5.4449, last reward: -4.0652, gradient norm: 4.889: 8%|▊ | 50/625 [00:11<01:21, 7.05it/s]
reward: -5.3485, last reward: -4.0872, gradient norm: 9.651: 8%|▊ | 50/625 [00:11<01:21, 7.05it/s]
reward: -5.3485, last reward: -4.0872, gradient norm: 9.651: 8%|▊ | 51/625 [00:11<01:21, 7.06it/s]
reward: -5.3456, last reward: -4.4047, gradient norm: 10.07: 8%|▊ | 51/625 [00:11<01:21, 7.06it/s]
reward: -5.3456, last reward: -4.4047, gradient norm: 10.07: 8%|▊ | 52/625 [00:11<01:21, 7.06it/s]
reward: -5.3334, last reward: -6.2396, gradient norm: 22.66: 8%|▊ | 52/625 [00:11<01:21, 7.06it/s]
reward: -5.3334, last reward: -6.2396, gradient norm: 22.66: 8%|▊ | 53/625 [00:11<01:20, 7.08it/s]
reward: -5.2438, last reward: -3.3497, gradient norm: 53.99: 8%|▊ | 53/625 [00:11<01:20, 7.08it/s]
reward: -5.2438, last reward: -3.3497, gradient norm: 53.99: 9%|▊ | 54/625 [00:11<01:20, 7.10it/s]
reward: -5.6399, last reward: -8.3033, gradient norm: 7.747: 9%|▊ | 54/625 [00:11<01:20, 7.10it/s]
reward: -5.6399, last reward: -8.3033, gradient norm: 7.747: 9%|▉ | 55/625 [00:11<01:20, 7.11it/s]
reward: -5.8960, last reward: -10.7914, gradient norm: 15.87: 9%|▉ | 55/625 [00:12<01:20, 7.11it/s]
reward: -5.8960, last reward: -10.7914, gradient norm: 15.87: 9%|▉ | 56/625 [00:12<01:19, 7.12it/s]
reward: -6.1587, last reward: -8.0300, gradient norm: 3.57: 9%|▉ | 56/625 [00:12<01:19, 7.12it/s]
reward: -6.1587, last reward: -8.0300, gradient norm: 3.57: 9%|▉ | 57/625 [00:12<01:19, 7.11it/s]
reward: -6.2045, last reward: -9.3709, gradient norm: 4.633: 9%|▉ | 57/625 [00:12<01:19, 7.11it/s]
reward: -6.2045, last reward: -9.3709, gradient norm: 4.633: 9%|▉ | 58/625 [00:12<01:19, 7.11it/s]
reward: -5.9553, last reward: -9.1108, gradient norm: 44.41: 9%|▉ | 58/625 [00:12<01:19, 7.11it/s]
reward: -5.9553, last reward: -9.1108, gradient norm: 44.41: 9%|▉ | 59/625 [00:12<01:19, 7.10it/s]
reward: -6.1326, last reward: -7.0135, gradient norm: 24.91: 9%|▉ | 59/625 [00:12<01:19, 7.10it/s]
reward: -6.1326, last reward: -7.0135, gradient norm: 24.91: 10%|▉ | 60/625 [00:12<01:19, 7.10it/s]
reward: -6.0302, last reward: -9.2170, gradient norm: 10.82: 10%|▉ | 60/625 [00:12<01:19, 7.10it/s]
reward: -6.0302, last reward: -9.2170, gradient norm: 10.82: 10%|▉ | 61/625 [00:12<01:19, 7.11it/s]
reward: -5.6971, last reward: -8.6591, gradient norm: 13.52: 10%|▉ | 61/625 [00:12<01:19, 7.11it/s]
reward: -5.6971, last reward: -8.6591, gradient norm: 13.52: 10%|▉ | 62/625 [00:12<01:19, 7.10it/s]
reward: -5.4050, last reward: -4.3769, gradient norm: 40.84: 10%|▉ | 62/625 [00:13<01:19, 7.10it/s]
reward: -5.4050, last reward: -4.3769, gradient norm: 40.84: 10%|█ | 63/625 [00:13<01:19, 7.10it/s]
reward: -5.3263, last reward: -3.8922, gradient norm: 6.107: 10%|█ | 63/625 [00:13<01:19, 7.10it/s]
reward: -5.3263, last reward: -3.8922, gradient norm: 6.107: 10%|█ | 64/625 [00:13<01:18, 7.11it/s]
reward: -4.9937, last reward: -5.6089, gradient norm: 11.8: 10%|█ | 64/625 [00:13<01:18, 7.11it/s]
reward: -4.9937, last reward: -5.6089, gradient norm: 11.8: 10%|█ | 65/625 [00:13<01:18, 7.11it/s]
reward: -5.0107, last reward: -6.5861, gradient norm: 5.301: 10%|█ | 65/625 [00:13<01:18, 7.11it/s]
reward: -5.0107, last reward: -6.5861, gradient norm: 5.301: 11%|█ | 66/625 [00:13<01:18, 7.10it/s]
reward: -5.0867, last reward: -4.8672, gradient norm: 10.19: 11%|█ | 66/625 [00:13<01:18, 7.10it/s]
reward: -5.0867, last reward: -4.8672, gradient norm: 10.19: 11%|█ | 67/625 [00:13<01:18, 7.10it/s]
reward: -5.4521, last reward: -4.8346, gradient norm: 9.867: 11%|█ | 67/625 [00:13<01:18, 7.10it/s]
reward: -5.4521, last reward: -4.8346, gradient norm: 9.867: 11%|█ | 68/625 [00:13<01:18, 7.09it/s]
reward: -5.5534, last reward: -6.2289, gradient norm: 11.31: 11%|█ | 68/625 [00:13<01:18, 7.09it/s]
reward: -5.5534, last reward: -6.2289, gradient norm: 11.31: 11%|█ | 69/625 [00:13<01:18, 7.09it/s]
reward: -5.3452, last reward: -5.0380, gradient norm: 10.01: 11%|█ | 69/625 [00:14<01:18, 7.09it/s]
reward: -5.3452, last reward: -5.0380, gradient norm: 10.01: 11%|█ | 70/625 [00:14<01:18, 7.09it/s]
reward: -5.1849, last reward: -6.5698, gradient norm: 4.838: 11%|█ | 70/625 [00:14<01:18, 7.09it/s]
reward: -5.1849, last reward: -6.5698, gradient norm: 4.838: 11%|█▏ | 71/625 [00:14<01:18, 7.10it/s]
reward: -5.1793, last reward: -4.0837, gradient norm: 17.78: 11%|█▏ | 71/625 [00:14<01:18, 7.10it/s]
reward: -5.1793, last reward: -4.0837, gradient norm: 17.78: 12%|█▏ | 72/625 [00:14<01:17, 7.10it/s]
reward: -4.6703, last reward: -3.5796, gradient norm: 9.965: 12%|█▏ | 72/625 [00:14<01:17, 7.10it/s]
reward: -4.6703, last reward: -3.5796, gradient norm: 9.965: 12%|█▏ | 73/625 [00:14<01:17, 7.10it/s]
reward: -4.8660, last reward: -4.4801, gradient norm: 8.787: 12%|█▏ | 73/625 [00:14<01:17, 7.10it/s]
reward: -4.8660, last reward: -4.4801, gradient norm: 8.787: 12%|█▏ | 74/625 [00:14<01:17, 7.10it/s]
reward: -4.7928, last reward: -4.3883, gradient norm: 3.766: 12%|█▏ | 74/625 [00:14<01:17, 7.10it/s]
reward: -4.7928, last reward: -4.3883, gradient norm: 3.766: 12%|█▏ | 75/625 [00:14<01:17, 7.10it/s]
reward: -4.7290, last reward: -6.0205, gradient norm: 23.96: 12%|█▏ | 75/625 [00:14<01:17, 7.10it/s]
reward: -4.7290, last reward: -6.0205, gradient norm: 23.96: 12%|█▏ | 76/625 [00:14<01:17, 7.10it/s]
reward: -4.6745, last reward: -5.9787, gradient norm: 33.28: 12%|█▏ | 76/625 [00:15<01:17, 7.10it/s]
reward: -4.6745, last reward: -5.9787, gradient norm: 33.28: 12%|█▏ | 77/625 [00:15<01:17, 7.10it/s]
reward: -4.5643, last reward: -3.8718, gradient norm: 7.732: 12%|█▏ | 77/625 [00:15<01:17, 7.10it/s]
reward: -4.5643, last reward: -3.8718, gradient norm: 7.732: 12%|█▏ | 78/625 [00:15<01:19, 6.85it/s]
reward: -4.5283, last reward: -3.5873, gradient norm: 13.67: 12%|█▏ | 78/625 [00:15<01:19, 6.85it/s]
reward: -4.5283, last reward: -3.5873, gradient norm: 13.67: 13%|█▎ | 79/625 [00:15<01:19, 6.86it/s]
reward: -4.7644, last reward: -4.0928, gradient norm: 2.084: 13%|█▎ | 79/625 [00:15<01:19, 6.86it/s]
reward: -4.7644, last reward: -4.0928, gradient norm: 2.084: 13%|█▎ | 80/625 [00:15<01:18, 6.92it/s]
reward: -5.0095, last reward: -3.6340, gradient norm: 8.484: 13%|█▎ | 80/625 [00:15<01:18, 6.92it/s]
reward: -5.0095, last reward: -3.6340, gradient norm: 8.484: 13%|█▎ | 81/625 [00:15<01:18, 6.97it/s]
reward: -4.5784, last reward: -3.8388, gradient norm: 10.28: 13%|█▎ | 81/625 [00:15<01:18, 6.97it/s]
reward: -4.5784, last reward: -3.8388, gradient norm: 10.28: 13%|█▎ | 82/625 [00:15<01:17, 7.02it/s]
reward: -4.3689, last reward: -2.5954, gradient norm: 7.878: 13%|█▎ | 82/625 [00:15<01:17, 7.02it/s]
reward: -4.3689, last reward: -2.5954, gradient norm: 7.878: 13%|█▎ | 83/625 [00:15<01:16, 7.05it/s]
reward: -4.2008, last reward: -3.2782, gradient norm: 15.51: 13%|█▎ | 83/625 [00:16<01:16, 7.05it/s]
reward: -4.2008, last reward: -3.2782, gradient norm: 15.51: 13%|█▎ | 84/625 [00:16<01:16, 7.07it/s]
reward: -4.4065, last reward: -6.3645, gradient norm: 22.07: 13%|█▎ | 84/625 [00:16<01:16, 7.07it/s]
reward: -4.4065, last reward: -6.3645, gradient norm: 22.07: 14%|█▎ | 85/625 [00:16<01:16, 7.09it/s]
reward: -4.7696, last reward: -7.1147, gradient norm: 21.88: 14%|█▎ | 85/625 [00:16<01:16, 7.09it/s]
reward: -4.7696, last reward: -7.1147, gradient norm: 21.88: 14%|█▍ | 86/625 [00:16<01:15, 7.09it/s]
reward: -4.5708, last reward: -3.4256, gradient norm: 17.55: 14%|█▍ | 86/625 [00:16<01:15, 7.09it/s]
reward: -4.5708, last reward: -3.4256, gradient norm: 17.55: 14%|█▍ | 87/625 [00:16<01:15, 7.10it/s]
reward: -4.5454, last reward: -3.8066, gradient norm: 8.725: 14%|█▍ | 87/625 [00:16<01:15, 7.10it/s]
reward: -4.5454, last reward: -3.8066, gradient norm: 8.725: 14%|█▍ | 88/625 [00:16<01:15, 7.10it/s]
reward: -4.4032, last reward: -4.1791, gradient norm: 4.637: 14%|█▍ | 88/625 [00:16<01:15, 7.10it/s]
reward: -4.4032, last reward: -4.1791, gradient norm: 4.637: 14%|█▍ | 89/625 [00:16<01:15, 7.11it/s]
reward: -4.7665, last reward: -6.5648, gradient norm: 21.23: 14%|█▍ | 89/625 [00:16<01:15, 7.11it/s]
reward: -4.7665, last reward: -6.5648, gradient norm: 21.23: 14%|█▍ | 90/625 [00:16<01:15, 7.11it/s]
reward: -4.6237, last reward: -8.0999, gradient norm: 22.05: 14%|█▍ | 90/625 [00:17<01:15, 7.11it/s]
reward: -4.6237, last reward: -8.0999, gradient norm: 22.05: 15%|█▍ | 91/625 [00:17<01:15, 7.11it/s]
reward: -4.6426, last reward: -5.1266, gradient norm: 40.96: 15%|█▍ | 91/625 [00:17<01:15, 7.11it/s]
reward: -4.6426, last reward: -5.1266, gradient norm: 40.96: 15%|█▍ | 92/625 [00:17<01:14, 7.11it/s]
reward: -4.4903, last reward: -3.1749, gradient norm: 3.308: 15%|█▍ | 92/625 [00:17<01:14, 7.11it/s]
reward: -4.4903, last reward: -3.1749, gradient norm: 3.308: 15%|█▍ | 93/625 [00:17<01:14, 7.10it/s]
reward: -4.3369, last reward: -4.5930, gradient norm: 32.79: 15%|█▍ | 93/625 [00:17<01:14, 7.10it/s]
reward: -4.3369, last reward: -4.5930, gradient norm: 32.79: 15%|█▌ | 94/625 [00:17<01:14, 7.09it/s]
reward: -4.5026, last reward: -4.1401, gradient norm: 19.22: 15%|█▌ | 94/625 [00:17<01:14, 7.09it/s]
reward: -4.5026, last reward: -4.1401, gradient norm: 19.22: 15%|█▌ | 95/625 [00:17<01:14, 7.09it/s]
reward: -4.4875, last reward: -5.1445, gradient norm: 22.87: 15%|█▌ | 95/625 [00:17<01:14, 7.09it/s]
reward: -4.4875, last reward: -5.1445, gradient norm: 22.87: 15%|█▌ | 96/625 [00:17<01:14, 7.11it/s]
reward: -5.0280, last reward: -4.0446, gradient norm: 13.07: 15%|█▌ | 96/625 [00:17<01:14, 7.11it/s]
reward: -5.0280, last reward: -4.0446, gradient norm: 13.07: 16%|█▌ | 97/625 [00:17<01:14, 7.10it/s]
reward: -4.5949, last reward: -3.3326, gradient norm: 20.9: 16%|█▌ | 97/625 [00:18<01:14, 7.10it/s]
reward: -4.5949, last reward: -3.3326, gradient norm: 20.9: 16%|█▌ | 98/625 [00:18<01:14, 7.10it/s]
reward: -4.7872, last reward: -4.5315, gradient norm: 9.906: 16%|█▌ | 98/625 [00:18<01:14, 7.10it/s]
reward: -4.7872, last reward: -4.5315, gradient norm: 9.906: 16%|█▌ | 99/625 [00:18<01:14, 7.10it/s]
reward: -4.8920, last reward: -5.8424, gradient norm: 27.12: 16%|█▌ | 99/625 [00:18<01:14, 7.10it/s]
reward: -4.8920, last reward: -5.8424, gradient norm: 27.12: 16%|█▌ | 100/625 [00:18<01:14, 7.09it/s]
reward: -5.2556, last reward: -5.6036, gradient norm: 8.877: 16%|█▌ | 100/625 [00:18<01:14, 7.09it/s]
reward: -5.2556, last reward: -5.6036, gradient norm: 8.877: 16%|█▌ | 101/625 [00:18<01:13, 7.10it/s]
reward: -4.9990, last reward: -6.3967, gradient norm: 69.95: 16%|█▌ | 101/625 [00:18<01:13, 7.10it/s]
reward: -4.9990, last reward: -6.3967, gradient norm: 69.95: 16%|█▋ | 102/625 [00:18<01:13, 7.09it/s]
reward: -5.0957, last reward: -5.6909, gradient norm: 47.05: 16%|█▋ | 102/625 [00:18<01:13, 7.09it/s]
reward: -5.0957, last reward: -5.6909, gradient norm: 47.05: 16%|█▋ | 103/625 [00:18<01:13, 7.09it/s]
reward: -5.4652, last reward: -7.7235, gradient norm: 44.91: 16%|█▋ | 103/625 [00:18<01:13, 7.09it/s]
reward: -5.4652, last reward: -7.7235, gradient norm: 44.91: 17%|█▋ | 104/625 [00:18<01:13, 7.10it/s]
reward: -5.7501, last reward: -6.4184, gradient norm: 4.864: 17%|█▋ | 104/625 [00:19<01:13, 7.10it/s]
reward: -5.7501, last reward: -6.4184, gradient norm: 4.864: 17%|█▋ | 105/625 [00:19<01:13, 7.10it/s]
reward: -5.6103, last reward: -6.9113, gradient norm: 7.454: 17%|█▋ | 105/625 [00:19<01:13, 7.10it/s]
reward: -5.6103, last reward: -6.9113, gradient norm: 7.454: 17%|█▋ | 106/625 [00:19<01:13, 7.10it/s]
reward: -5.2127, last reward: -8.0405, gradient norm: 30.96: 17%|█▋ | 106/625 [00:19<01:13, 7.10it/s]
reward: -5.2127, last reward: -8.0405, gradient norm: 30.96: 17%|█▋ | 107/625 [00:19<01:13, 7.09it/s]
reward: -5.1001, last reward: -5.1922, gradient norm: 4.149: 17%|█▋ | 107/625 [00:19<01:13, 7.09it/s]
reward: -5.1001, last reward: -5.1922, gradient norm: 4.149: 17%|█▋ | 108/625 [00:19<01:12, 7.08it/s]
reward: -4.7416, last reward: -5.9890, gradient norm: 48.28: 17%|█▋ | 108/625 [00:19<01:12, 7.08it/s]
reward: -4.7416, last reward: -5.9890, gradient norm: 48.28: 17%|█▋ | 109/625 [00:19<01:12, 7.09it/s]
reward: -4.7073, last reward: -6.8889, gradient norm: 4.63: 17%|█▋ | 109/625 [00:19<01:12, 7.09it/s]
reward: -4.7073, last reward: -6.8889, gradient norm: 4.63: 18%|█▊ | 110/625 [00:19<01:12, 7.09it/s]
reward: -4.5656, last reward: -3.8993, gradient norm: 4.333: 18%|█▊ | 110/625 [00:19<01:12, 7.09it/s]
reward: -4.5656, last reward: -3.8993, gradient norm: 4.333: 18%|█▊ | 111/625 [00:19<01:12, 7.10it/s]
reward: -4.6999, last reward: -3.7481, gradient norm: 15.55: 18%|█▊ | 111/625 [00:20<01:12, 7.10it/s]
reward: -4.6999, last reward: -3.7481, gradient norm: 15.55: 18%|█▊ | 112/625 [00:20<01:12, 7.10it/s]
reward: -4.8794, last reward: -4.7351, gradient norm: 14.69: 18%|█▊ | 112/625 [00:20<01:12, 7.10it/s]
reward: -4.8794, last reward: -4.7351, gradient norm: 14.69: 18%|█▊ | 113/625 [00:20<01:12, 7.08it/s]
reward: -4.9466, last reward: -4.6133, gradient norm: 13.91: 18%|█▊ | 113/625 [00:20<01:12, 7.08it/s]
reward: -4.9466, last reward: -4.6133, gradient norm: 13.91: 18%|█▊ | 114/625 [00:20<01:12, 7.08it/s]
reward: -4.8454, last reward: -4.2127, gradient norm: 15.0: 18%|█▊ | 114/625 [00:20<01:12, 7.08it/s]
reward: -4.8454, last reward: -4.2127, gradient norm: 15.0: 18%|█▊ | 115/625 [00:20<01:11, 7.09it/s]
reward: -4.3656, last reward: -4.5445, gradient norm: 23.07: 18%|█▊ | 115/625 [00:20<01:11, 7.09it/s]
reward: -4.3656, last reward: -4.5445, gradient norm: 23.07: 19%|█▊ | 116/625 [00:20<01:11, 7.09it/s]
reward: -3.7770, last reward: -4.5848, gradient norm: 34.73: 19%|█▊ | 116/625 [00:20<01:11, 7.09it/s]
reward: -3.7770, last reward: -4.5848, gradient norm: 34.73: 19%|█▊ | 117/625 [00:20<01:11, 7.09it/s]
reward: -4.0050, last reward: -4.0215, gradient norm: 27.8: 19%|█▊ | 117/625 [00:20<01:11, 7.09it/s]
reward: -4.0050, last reward: -4.0215, gradient norm: 27.8: 19%|█▉ | 118/625 [00:20<01:11, 7.10it/s]
reward: -4.2035, last reward: -3.5026, gradient norm: 26.13: 19%|█▉ | 118/625 [00:21<01:11, 7.10it/s]
reward: -4.2035, last reward: -3.5026, gradient norm: 26.13: 19%|█▉ | 119/625 [00:21<01:11, 7.09it/s]
reward: -4.5090, last reward: -5.8160, gradient norm: 18.82: 19%|█▉ | 119/625 [00:21<01:11, 7.09it/s]
reward: -4.5090, last reward: -5.8160, gradient norm: 18.82: 19%|█▉ | 120/625 [00:21<01:11, 7.10it/s]
reward: -4.5486, last reward: -4.6456, gradient norm: 19.75: 19%|█▉ | 120/625 [00:21<01:11, 7.10it/s]
reward: -4.5486, last reward: -4.6456, gradient norm: 19.75: 19%|█▉ | 121/625 [00:21<01:10, 7.10it/s]
reward: -4.1315, last reward: -3.0512, gradient norm: 29.97: 19%|█▉ | 121/625 [00:21<01:10, 7.10it/s]
reward: -4.1315, last reward: -3.0512, gradient norm: 29.97: 20%|█▉ | 122/625 [00:21<01:10, 7.09it/s]
reward: -4.0454, last reward: -3.5747, gradient norm: 6.504: 20%|█▉ | 122/625 [00:21<01:10, 7.09it/s]
reward: -4.0454, last reward: -3.5747, gradient norm: 6.504: 20%|█▉ | 123/625 [00:21<01:10, 7.09it/s]
reward: -3.8570, last reward: -3.1843, gradient norm: 1.935: 20%|█▉ | 123/625 [00:21<01:10, 7.09it/s]
reward: -3.8570, last reward: -3.1843, gradient norm: 1.935: 20%|█▉ | 124/625 [00:21<01:10, 7.09it/s]
reward: -4.3473, last reward: -5.1605, gradient norm: 27.4: 20%|█▉ | 124/625 [00:21<01:10, 7.09it/s]
reward: -4.3473, last reward: -5.1605, gradient norm: 27.4: 20%|██ | 125/625 [00:21<01:10, 7.09it/s]
reward: -4.8034, last reward: -4.6141, gradient norm: 17.57: 20%|██ | 125/625 [00:22<01:10, 7.09it/s]
reward: -4.8034, last reward: -4.6141, gradient norm: 17.57: 20%|██ | 126/625 [00:22<01:10, 7.08it/s]
reward: -4.3256, last reward: -4.2736, gradient norm: 17.02: 20%|██ | 126/625 [00:22<01:10, 7.08it/s]
reward: -4.3256, last reward: -4.2736, gradient norm: 17.02: 20%|██ | 127/625 [00:22<01:10, 7.09it/s]
reward: -4.5422, last reward: -4.4557, gradient norm: 18.06: 20%|██ | 127/625 [00:22<01:10, 7.09it/s]
reward: -4.5422, last reward: -4.4557, gradient norm: 18.06: 20%|██ | 128/625 [00:22<01:10, 7.10it/s]
reward: -4.1628, last reward: -4.9787, gradient norm: 16.69: 20%|██ | 128/625 [00:22<01:10, 7.10it/s]
reward: -4.1628, last reward: -4.9787, gradient norm: 16.69: 21%|██ | 129/625 [00:22<01:09, 7.10it/s]
reward: -3.7987, last reward: -4.4738, gradient norm: 33.21: 21%|██ | 129/625 [00:22<01:09, 7.10it/s]
reward: -3.7987, last reward: -4.4738, gradient norm: 33.21: 21%|██ | 130/625 [00:22<01:09, 7.10it/s]
reward: -3.8254, last reward: -5.8133, gradient norm: 55.39: 21%|██ | 130/625 [00:22<01:09, 7.10it/s]
reward: -3.8254, last reward: -5.8133, gradient norm: 55.39: 21%|██ | 131/625 [00:22<01:09, 7.10it/s]
reward: -4.0256, last reward: -3.7099, gradient norm: 9.884: 21%|██ | 131/625 [00:22<01:09, 7.10it/s]
reward: -4.0256, last reward: -3.7099, gradient norm: 9.884: 21%|██ | 132/625 [00:22<01:09, 7.10it/s]
reward: -3.6457, last reward: -3.3957, gradient norm: 13.36: 21%|██ | 132/625 [00:23<01:09, 7.10it/s]
reward: -3.6457, last reward: -3.3957, gradient norm: 13.36: 21%|██▏ | 133/625 [00:23<01:09, 7.11it/s]
reward: -3.8728, last reward: -2.6434, gradient norm: 31.01: 21%|██▏ | 133/625 [00:23<01:09, 7.11it/s]
reward: -3.8728, last reward: -2.6434, gradient norm: 31.01: 21%|██▏ | 134/625 [00:23<01:09, 7.10it/s]
reward: -3.9535, last reward: -3.4027, gradient norm: 34.54: 21%|██▏ | 134/625 [00:23<01:09, 7.10it/s]
reward: -3.9535, last reward: -3.4027, gradient norm: 34.54: 22%|██▏ | 135/625 [00:23<01:08, 7.11it/s]
reward: -4.0358, last reward: -2.8919, gradient norm: 22.04: 22%|██▏ | 135/625 [00:23<01:08, 7.11it/s]
reward: -4.0358, last reward: -2.8919, gradient norm: 22.04: 22%|██▏ | 136/625 [00:23<01:08, 7.11it/s]
reward: -4.0826, last reward: -3.5504, gradient norm: 11.87: 22%|██▏ | 136/625 [00:23<01:08, 7.11it/s]
reward: -4.0826, last reward: -3.5504, gradient norm: 11.87: 22%|██▏ | 137/625 [00:23<01:08, 7.10it/s]
reward: -3.9513, last reward: -3.5666, gradient norm: 36.97: 22%|██▏ | 137/625 [00:23<01:08, 7.10it/s]
reward: -3.9513, last reward: -3.5666, gradient norm: 36.97: 22%|██▏ | 138/625 [00:23<01:08, 7.09it/s]
reward: -4.2654, last reward: -2.9644, gradient norm: 10.0: 22%|██▏ | 138/625 [00:23<01:08, 7.09it/s]
reward: -4.2654, last reward: -2.9644, gradient norm: 10.0: 22%|██▏ | 139/625 [00:23<01:08, 7.10it/s]
reward: -3.9990, last reward: -2.7369, gradient norm: 11.83: 22%|██▏ | 139/625 [00:23<01:08, 7.10it/s]
reward: -3.9990, last reward: -2.7369, gradient norm: 11.83: 22%|██▏ | 140/625 [00:23<01:08, 7.09it/s]
reward: -3.8737, last reward: -4.4108, gradient norm: 104.5: 22%|██▏ | 140/625 [00:24<01:08, 7.09it/s]
reward: -3.8737, last reward: -4.4108, gradient norm: 104.5: 23%|██▎ | 141/625 [00:24<01:08, 7.10it/s]
reward: -4.1278, last reward: -3.7020, gradient norm: 14.9: 23%|██▎ | 141/625 [00:24<01:08, 7.10it/s]
reward: -4.1278, last reward: -3.7020, gradient norm: 14.9: 23%|██▎ | 142/625 [00:24<01:08, 7.08it/s]
reward: -4.0679, last reward: -2.9054, gradient norm: 12.71: 23%|██▎ | 142/625 [00:24<01:08, 7.08it/s]
reward: -4.0679, last reward: -2.9054, gradient norm: 12.71: 23%|██▎ | 143/625 [00:24<01:07, 7.10it/s]
reward: -3.8169, last reward: -3.9620, gradient norm: 51.01: 23%|██▎ | 143/625 [00:24<01:07, 7.10it/s]
reward: -3.8169, last reward: -3.9620, gradient norm: 51.01: 23%|██▎ | 144/625 [00:24<01:07, 7.11it/s]
reward: -3.9215, last reward: -4.3617, gradient norm: 30.19: 23%|██▎ | 144/625 [00:24<01:07, 7.11it/s]
reward: -3.9215, last reward: -4.3617, gradient norm: 30.19: 23%|██▎ | 145/625 [00:24<01:18, 6.12it/s]
reward: -4.0913, last reward: -1.8258, gradient norm: 10.49: 23%|██▎ | 145/625 [00:24<01:18, 6.12it/s]
reward: -4.0913, last reward: -1.8258, gradient norm: 10.49: 23%|██▎ | 146/625 [00:24<01:15, 6.38it/s]
reward: -4.4477, last reward: -2.8221, gradient norm: 6.613: 23%|██▎ | 146/625 [00:25<01:15, 6.38it/s]
reward: -4.4477, last reward: -2.8221, gradient norm: 6.613: 24%|██▎ | 147/625 [00:25<01:12, 6.58it/s]
reward: -3.7064, last reward: -5.4502, gradient norm: 55.72: 24%|██▎ | 147/625 [00:25<01:12, 6.58it/s]
reward: -3.7064, last reward: -5.4502, gradient norm: 55.72: 24%|██▎ | 148/625 [00:25<01:10, 6.73it/s]
reward: -3.3324, last reward: -2.1451, gradient norm: 31.61: 24%|██▎ | 148/625 [00:25<01:10, 6.73it/s]
reward: -3.3324, last reward: -2.1451, gradient norm: 31.61: 24%|██▍ | 149/625 [00:25<01:09, 6.84it/s]
reward: -3.6832, last reward: -3.8591, gradient norm: 46.6: 24%|██▍ | 149/625 [00:25<01:09, 6.84it/s]
reward: -3.6832, last reward: -3.8591, gradient norm: 46.6: 24%|██▍ | 150/625 [00:25<01:08, 6.90it/s]
reward: -3.7654, last reward: -2.5380, gradient norm: 46.82: 24%|██▍ | 150/625 [00:25<01:08, 6.90it/s]
reward: -3.7654, last reward: -2.5380, gradient norm: 46.82: 24%|██▍ | 151/625 [00:25<01:08, 6.96it/s]
reward: -3.6237, last reward: -3.8250, gradient norm: 8.574: 24%|██▍ | 151/625 [00:25<01:08, 6.96it/s]
reward: -3.6237, last reward: -3.8250, gradient norm: 8.574: 24%|██▍ | 152/625 [00:25<01:07, 6.99it/s]
reward: -3.9282, last reward: -3.9420, gradient norm: 9.924: 24%|██▍ | 152/625 [00:25<01:07, 6.99it/s]
reward: -3.9282, last reward: -3.9420, gradient norm: 9.924: 24%|██▍ | 153/625 [00:25<01:07, 7.02it/s]
reward: -3.7577, last reward: -3.2244, gradient norm: 16.47: 24%|██▍ | 153/625 [00:26<01:07, 7.02it/s]
reward: -3.7577, last reward: -3.2244, gradient norm: 16.47: 25%|██▍ | 154/625 [00:26<01:06, 7.05it/s]
reward: -3.5259, last reward: -2.2238, gradient norm: 19.05: 25%|██▍ | 154/625 [00:26<01:06, 7.05it/s]
reward: -3.5259, last reward: -2.2238, gradient norm: 19.05: 25%|██▍ | 155/625 [00:26<01:06, 7.06it/s]
reward: -3.7319, last reward: -1.7933, gradient norm: 20.63: 25%|██▍ | 155/625 [00:26<01:06, 7.06it/s]
reward: -3.7319, last reward: -1.7933, gradient norm: 20.63: 25%|██▍ | 156/625 [00:26<01:06, 7.07it/s]
reward: -4.0370, last reward: -4.2733, gradient norm: 36.68: 25%|██▍ | 156/625 [00:26<01:06, 7.07it/s]
reward: -4.0370, last reward: -4.2733, gradient norm: 36.68: 25%|██▌ | 157/625 [00:26<01:06, 7.08it/s]
reward: -3.7765, last reward: -4.0258, gradient norm: 35.2: 25%|██▌ | 157/625 [00:26<01:06, 7.08it/s]
reward: -3.7765, last reward: -4.0258, gradient norm: 35.2: 25%|██▌ | 158/625 [00:26<01:05, 7.08it/s]
reward: -3.4332, last reward: -1.6628, gradient norm: 7.881: 25%|██▌ | 158/625 [00:26<01:05, 7.08it/s]
reward: -3.4332, last reward: -1.6628, gradient norm: 7.881: 25%|██▌ | 159/625 [00:26<01:05, 7.09it/s]
reward: -3.6437, last reward: -3.0936, gradient norm: 31.75: 25%|██▌ | 159/625 [00:26<01:05, 7.09it/s]
reward: -3.6437, last reward: -3.0936, gradient norm: 31.75: 26%|██▌ | 160/625 [00:26<01:05, 7.09it/s]
reward: -3.5360, last reward: -2.0175, gradient norm: 29.26: 26%|██▌ | 160/625 [00:27<01:05, 7.09it/s]
reward: -3.5360, last reward: -2.0175, gradient norm: 29.26: 26%|██▌ | 161/625 [00:27<01:05, 7.09it/s]
reward: -3.5750, last reward: -2.3843, gradient norm: 20.97: 26%|██▌ | 161/625 [00:27<01:05, 7.09it/s]
reward: -3.5750, last reward: -2.3843, gradient norm: 20.97: 26%|██▌ | 162/625 [00:27<01:05, 7.09it/s]
reward: -3.6711, last reward: -3.7801, gradient norm: 45.53: 26%|██▌ | 162/625 [00:27<01:05, 7.09it/s]
reward: -3.6711, last reward: -3.7801, gradient norm: 45.53: 26%|██▌ | 163/625 [00:27<01:05, 7.06it/s]
reward: -4.0941, last reward: -3.1510, gradient norm: 29.52: 26%|██▌ | 163/625 [00:27<01:05, 7.06it/s]
reward: -4.0941, last reward: -3.1510, gradient norm: 29.52: 26%|██▌ | 164/625 [00:27<01:05, 7.07it/s]
reward: -3.6034, last reward: -2.9522, gradient norm: 26.73: 26%|██▌ | 164/625 [00:27<01:05, 7.07it/s]
reward: -3.6034, last reward: -2.9522, gradient norm: 26.73: 26%|██▋ | 165/625 [00:27<01:04, 7.08it/s]
reward: -3.6152, last reward: -1.9892, gradient norm: 3.542: 26%|██▋ | 165/625 [00:27<01:04, 7.08it/s]
reward: -3.6152, last reward: -1.9892, gradient norm: 3.542: 27%|██▋ | 166/625 [00:27<01:04, 7.09it/s]
reward: -3.7104, last reward: -3.7513, gradient norm: 25.5: 27%|██▋ | 166/625 [00:27<01:04, 7.09it/s]
reward: -3.7104, last reward: -3.7513, gradient norm: 25.5: 27%|██▋ | 167/625 [00:27<01:04, 7.09it/s]
reward: -3.6630, last reward: -3.8739, gradient norm: 14.87: 27%|██▋ | 167/625 [00:28<01:04, 7.09it/s]
reward: -3.6630, last reward: -3.8739, gradient norm: 14.87: 27%|██▋ | 168/625 [00:28<01:04, 7.09it/s]
reward: -3.4117, last reward: -3.6730, gradient norm: 26.83: 27%|██▋ | 168/625 [00:28<01:04, 7.09it/s]
reward: -3.4117, last reward: -3.6730, gradient norm: 26.83: 27%|██▋ | 169/625 [00:28<01:04, 7.09it/s]
reward: -3.8254, last reward: -3.4302, gradient norm: 35.5: 27%|██▋ | 169/625 [00:28<01:04, 7.09it/s]
reward: -3.8254, last reward: -3.4302, gradient norm: 35.5: 27%|██▋ | 170/625 [00:28<01:04, 7.09it/s]
reward: -3.9023, last reward: -3.3292, gradient norm: 24.39: 27%|██▋ | 170/625 [00:28<01:04, 7.09it/s]
reward: -3.9023, last reward: -3.3292, gradient norm: 24.39: 27%|██▋ | 171/625 [00:28<01:03, 7.11it/s]
reward: -3.7378, last reward: -4.3028, gradient norm: 35.76: 27%|██▋ | 171/625 [00:28<01:03, 7.11it/s]
reward: -3.7378, last reward: -4.3028, gradient norm: 35.76: 28%|██▊ | 172/625 [00:28<01:03, 7.11it/s]
reward: -3.7004, last reward: -4.3646, gradient norm: 40.17: 28%|██▊ | 172/625 [00:28<01:03, 7.11it/s]
reward: -3.7004, last reward: -4.3646, gradient norm: 40.17: 28%|██▊ | 173/625 [00:28<01:03, 7.10it/s]
reward: -3.6247, last reward: -5.3075, gradient norm: 40.39: 28%|██▊ | 173/625 [00:28<01:03, 7.10it/s]
reward: -3.6247, last reward: -5.3075, gradient norm: 40.39: 28%|██▊ | 174/625 [00:28<01:03, 7.09it/s]
reward: -3.0240, last reward: -2.6505, gradient norm: 40.17: 28%|██▊ | 174/625 [00:29<01:03, 7.09it/s]
reward: -3.0240, last reward: -2.6505, gradient norm: 40.17: 28%|██▊ | 175/625 [00:29<01:03, 7.08it/s]
reward: -3.2337, last reward: -2.7439, gradient norm: 681.2: 28%|██▊ | 175/625 [00:29<01:03, 7.08it/s]
reward: -3.2337, last reward: -2.7439, gradient norm: 681.2: 28%|██▊ | 176/625 [00:29<01:03, 7.09it/s]
reward: -3.9051, last reward: -4.7835, gradient norm: 51.28: 28%|██▊ | 176/625 [00:29<01:03, 7.09it/s]
reward: -3.9051, last reward: -4.7835, gradient norm: 51.28: 28%|██▊ | 177/625 [00:29<01:03, 7.09it/s]
reward: -4.2080, last reward: -4.6217, gradient norm: 41.18: 28%|██▊ | 177/625 [00:29<01:03, 7.09it/s]
reward: -4.2080, last reward: -4.6217, gradient norm: 41.18: 28%|██▊ | 178/625 [00:29<01:03, 7.09it/s]
reward: -4.1073, last reward: -3.7482, gradient norm: 50.28: 28%|██▊ | 178/625 [00:29<01:03, 7.09it/s]
reward: -4.1073, last reward: -3.7482, gradient norm: 50.28: 29%|██▊ | 179/625 [00:29<01:02, 7.09it/s]
reward: -3.4650, last reward: -2.2516, gradient norm: 38.2: 29%|██▊ | 179/625 [00:29<01:02, 7.09it/s]
reward: -3.4650, last reward: -2.2516, gradient norm: 38.2: 29%|██▉ | 180/625 [00:29<01:02, 7.10it/s]
reward: -3.6996, last reward: -1.9877, gradient norm: 10.43: 29%|██▉ | 180/625 [00:29<01:02, 7.10it/s]
reward: -3.6996, last reward: -1.9877, gradient norm: 10.43: 29%|██▉ | 181/625 [00:29<01:02, 7.09it/s]
reward: -3.4743, last reward: -2.7800, gradient norm: 41.08: 29%|██▉ | 181/625 [00:29<01:02, 7.09it/s]
reward: -3.4743, last reward: -2.7800, gradient norm: 41.08: 29%|██▉ | 182/625 [00:29<01:02, 7.09it/s]
reward: -3.4883, last reward: -2.5068, gradient norm: 14.54: 29%|██▉ | 182/625 [00:30<01:02, 7.09it/s]
reward: -3.4883, last reward: -2.5068, gradient norm: 14.54: 29%|██▉ | 183/625 [00:30<01:02, 7.10it/s]
reward: -3.1787, last reward: -3.4335, gradient norm: 58.25: 29%|██▉ | 183/625 [00:30<01:02, 7.10it/s]
reward: -3.1787, last reward: -3.4335, gradient norm: 58.25: 29%|██▉ | 184/625 [00:30<01:02, 7.10it/s]
reward: -3.3431, last reward: -3.6525, gradient norm: 30.27: 29%|██▉ | 184/625 [00:30<01:02, 7.10it/s]
reward: -3.3431, last reward: -3.6525, gradient norm: 30.27: 30%|██▉ | 185/625 [00:30<01:01, 7.12it/s]
reward: -3.2829, last reward: -4.6254, gradient norm: 156.5: 30%|██▉ | 185/625 [00:30<01:01, 7.12it/s]
reward: -3.2829, last reward: -4.6254, gradient norm: 156.5: 30%|██▉ | 186/625 [00:30<01:01, 7.11it/s]
reward: -3.3285, last reward: -2.4938, gradient norm: 68.24: 30%|██▉ | 186/625 [00:30<01:01, 7.11it/s]
reward: -3.3285, last reward: -2.4938, gradient norm: 68.24: 30%|██▉ | 187/625 [00:30<01:01, 7.10it/s]
reward: -3.5139, last reward: -1.7766, gradient norm: 28.82: 30%|██▉ | 187/625 [00:30<01:01, 7.10it/s]
reward: -3.5139, last reward: -1.7766, gradient norm: 28.82: 30%|███ | 188/625 [00:30<01:01, 7.10it/s]
reward: -3.9503, last reward: -2.6123, gradient norm: 7.649: 30%|███ | 188/625 [00:30<01:01, 7.10it/s]
reward: -3.9503, last reward: -2.6123, gradient norm: 7.649: 30%|███ | 189/625 [00:30<01:01, 7.09it/s]
reward: -3.8797, last reward: -2.2922, gradient norm: 2.074e+03: 30%|███ | 189/625 [00:31<01:01, 7.09it/s]
reward: -3.8797, last reward: -2.2922, gradient norm: 2.074e+03: 30%|███ | 190/625 [00:31<01:01, 7.11it/s]
reward: -4.1076, last reward: -3.5004, gradient norm: 10.47: 30%|███ | 190/625 [00:31<01:01, 7.11it/s]
reward: -4.1076, last reward: -3.5004, gradient norm: 10.47: 31%|███ | 191/625 [00:31<01:01, 7.10it/s]
reward: -4.2685, last reward: -5.0655, gradient norm: 22.24: 31%|███ | 191/625 [00:31<01:01, 7.10it/s]
reward: -4.2685, last reward: -5.0655, gradient norm: 22.24: 31%|███ | 192/625 [00:31<01:01, 7.10it/s]
reward: -3.9431, last reward: -3.5096, gradient norm: 69.89: 31%|███ | 192/625 [00:31<01:01, 7.10it/s]
reward: -3.9431, last reward: -3.5096, gradient norm: 69.89: 31%|███ | 193/625 [00:31<01:00, 7.10it/s]
reward: -4.1544, last reward: -4.3896, gradient norm: 13.38: 31%|███ | 193/625 [00:31<01:00, 7.10it/s]
reward: -4.1544, last reward: -4.3896, gradient norm: 13.38: 31%|███ | 194/625 [00:31<01:00, 7.10it/s]
reward: -3.9858, last reward: -2.8607, gradient norm: 10.14: 31%|███ | 194/625 [00:31<01:00, 7.10it/s]
reward: -3.9858, last reward: -2.8607, gradient norm: 10.14: 31%|███ | 195/625 [00:31<01:00, 7.09it/s]
reward: -3.8131, last reward: -3.6731, gradient norm: 13.52: 31%|███ | 195/625 [00:31<01:00, 7.09it/s]
reward: -3.8131, last reward: -3.6731, gradient norm: 13.52: 31%|███▏ | 196/625 [00:31<01:00, 7.10it/s]
reward: -3.4424, last reward: -2.9514, gradient norm: 35.43: 31%|███▏ | 196/625 [00:32<01:00, 7.10it/s]
reward: -3.4424, last reward: -2.9514, gradient norm: 35.43: 32%|███▏ | 197/625 [00:32<01:00, 7.10it/s]
reward: -4.7594, last reward: -4.4120, gradient norm: 18.49: 32%|███▏ | 197/625 [00:32<01:00, 7.10it/s]
reward: -4.7594, last reward: -4.4120, gradient norm: 18.49: 32%|███▏ | 198/625 [00:32<01:00, 7.10it/s]
reward: -5.0407, last reward: -5.8128, gradient norm: 14.52: 32%|███▏ | 198/625 [00:32<01:00, 7.10it/s]
reward: -5.0407, last reward: -5.8128, gradient norm: 14.52: 32%|███▏ | 199/625 [00:32<01:00, 7.10it/s]
reward: -5.0228, last reward: -4.3349, gradient norm: 9.293: 32%|███▏ | 199/625 [00:32<01:00, 7.10it/s]
reward: -5.0228, last reward: -4.3349, gradient norm: 9.293: 32%|███▏ | 200/625 [00:32<00:59, 7.10it/s]
reward: -4.9903, last reward: -4.5615, gradient norm: 11.2: 32%|███▏ | 200/625 [00:32<00:59, 7.10it/s]
reward: -4.9903, last reward: -4.5615, gradient norm: 11.2: 32%|███▏ | 201/625 [00:32<00:59, 7.10it/s]
reward: -4.9879, last reward: -5.6310, gradient norm: 15.21: 32%|███▏ | 201/625 [00:32<00:59, 7.10it/s]
reward: -4.9879, last reward: -5.6310, gradient norm: 15.21: 32%|███▏ | 202/625 [00:32<00:59, 7.10it/s]
reward: -4.6626, last reward: -5.6259, gradient norm: 21.76: 32%|███▏ | 202/625 [00:32<00:59, 7.10it/s]
reward: -4.6626, last reward: -5.6259, gradient norm: 21.76: 32%|███▏ | 203/625 [00:32<00:59, 7.10it/s]
reward: -4.1251, last reward: -4.3948, gradient norm: 12.82: 32%|███▏ | 203/625 [00:33<00:59, 7.10it/s]
reward: -4.1251, last reward: -4.3948, gradient norm: 12.82: 33%|███▎ | 204/625 [00:33<00:59, 7.10it/s]
reward: -3.9812, last reward: -2.4152, gradient norm: 5.072: 33%|███▎ | 204/625 [00:33<00:59, 7.10it/s]
reward: -3.9812, last reward: -2.4152, gradient norm: 5.072: 33%|███▎ | 205/625 [00:33<00:59, 7.10it/s]
reward: -4.0038, last reward: -3.2111, gradient norm: 9.212: 33%|███▎ | 205/625 [00:33<00:59, 7.10it/s]
reward: -4.0038, last reward: -3.2111, gradient norm: 9.212: 33%|███▎ | 206/625 [00:33<00:59, 7.08it/s]
reward: -3.7942, last reward: -4.0347, gradient norm: 158.8: 33%|███▎ | 206/625 [00:33<00:59, 7.08it/s]
reward: -3.7942, last reward: -4.0347, gradient norm: 158.8: 33%|███▎ | 207/625 [00:33<00:59, 7.08it/s]
reward: -4.4361, last reward: -3.4224, gradient norm: 54.7: 33%|███▎ | 207/625 [00:33<00:59, 7.08it/s]
reward: -4.4361, last reward: -3.4224, gradient norm: 54.7: 33%|███▎ | 208/625 [00:33<00:58, 7.10it/s]
reward: -4.9227, last reward: -5.5165, gradient norm: 17.34: 33%|███▎ | 208/625 [00:33<00:58, 7.10it/s]
reward: -4.9227, last reward: -5.5165, gradient norm: 17.34: 33%|███▎ | 209/625 [00:33<00:58, 7.09it/s]
reward: -4.8780, last reward: -6.5128, gradient norm: 18.44: 33%|███▎ | 209/625 [00:33<00:58, 7.09it/s]
reward: -4.8780, last reward: -6.5128, gradient norm: 18.44: 34%|███▎ | 210/625 [00:33<00:58, 7.10it/s]
reward: -4.9689, last reward: -5.6335, gradient norm: 99.24: 34%|███▎ | 210/625 [00:34<00:58, 7.10it/s]
reward: -4.9689, last reward: -5.6335, gradient norm: 99.24: 34%|███▍ | 211/625 [00:34<00:58, 7.09it/s]
reward: -4.9425, last reward: -5.7037, gradient norm: 21.63: 34%|███▍ | 211/625 [00:34<00:58, 7.09it/s]
reward: -4.9425, last reward: -5.7037, gradient norm: 21.63: 34%|███▍ | 212/625 [00:34<00:58, 7.09it/s]
reward: -4.7128, last reward: -5.8129, gradient norm: 64.37: 34%|███▍ | 212/625 [00:34<00:58, 7.09it/s]
reward: -4.7128, last reward: -5.8129, gradient norm: 64.37: 34%|███▍ | 213/625 [00:34<00:58, 7.08it/s]
reward: -4.5329, last reward: -3.0737, gradient norm: 7.515: 34%|███▍ | 213/625 [00:34<00:58, 7.08it/s]
reward: -4.5329, last reward: -3.0737, gradient norm: 7.515: 34%|███▍ | 214/625 [00:34<00:58, 7.08it/s]
reward: -4.3113, last reward: -4.1873, gradient norm: 10.98: 34%|███▍ | 214/625 [00:34<00:58, 7.08it/s]
reward: -4.3113, last reward: -4.1873, gradient norm: 10.98: 34%|███▍ | 215/625 [00:34<00:57, 7.08it/s]
reward: -4.1226, last reward: -2.9400, gradient norm: 4.873: 34%|███▍ | 215/625 [00:34<00:57, 7.08it/s]
reward: -4.1226, last reward: -2.9400, gradient norm: 4.873: 35%|███▍ | 216/625 [00:34<00:57, 7.08it/s]
reward: -3.8581, last reward: -3.1207, gradient norm: 8.915: 35%|███▍ | 216/625 [00:34<00:57, 7.08it/s]
reward: -3.8581, last reward: -3.1207, gradient norm: 8.915: 35%|███▍ | 217/625 [00:34<00:57, 7.09it/s]
reward: -3.7707, last reward: -2.9429, gradient norm: 11.26: 35%|███▍ | 217/625 [00:35<00:57, 7.09it/s]
reward: -3.7707, last reward: -2.9429, gradient norm: 11.26: 35%|███▍ | 218/625 [00:35<00:57, 7.10it/s]
reward: -3.9416, last reward: -4.0626, gradient norm: 68.0: 35%|███▍ | 218/625 [00:35<00:57, 7.10it/s]
reward: -3.9416, last reward: -4.0626, gradient norm: 68.0: 35%|███▌ | 219/625 [00:35<00:57, 7.10it/s]
reward: -4.7705, last reward: -4.7897, gradient norm: 12.55: 35%|███▌ | 219/625 [00:35<00:57, 7.10it/s]
reward: -4.7705, last reward: -4.7897, gradient norm: 12.55: 35%|███▌ | 220/625 [00:35<00:57, 7.09it/s]
reward: -5.0781, last reward: -4.7467, gradient norm: 9.341: 35%|███▌ | 220/625 [00:35<00:57, 7.09it/s]
reward: -5.0781, last reward: -4.7467, gradient norm: 9.341: 35%|███▌ | 221/625 [00:35<00:56, 7.09it/s]
reward: -4.9113, last reward: -5.8590, gradient norm: 11.19: 35%|███▌ | 221/625 [00:35<00:56, 7.09it/s]
reward: -4.9113, last reward: -5.8590, gradient norm: 11.19: 36%|███▌ | 222/625 [00:35<00:56, 7.10it/s]
reward: -4.8261, last reward: -5.5869, gradient norm: 14.76: 36%|███▌ | 222/625 [00:35<00:56, 7.10it/s]
reward: -4.8261, last reward: -5.5869, gradient norm: 14.76: 36%|███▌ | 223/625 [00:35<00:56, 7.09it/s]
reward: -4.4222, last reward: -3.8989, gradient norm: 26.63: 36%|███▌ | 223/625 [00:35<00:56, 7.09it/s]
reward: -4.4222, last reward: -3.8989, gradient norm: 26.63: 36%|███▌ | 224/625 [00:35<00:56, 7.09it/s]
reward: -4.9441, last reward: -5.2557, gradient norm: 13.46: 36%|███▌ | 224/625 [00:36<00:56, 7.09it/s]
reward: -4.9441, last reward: -5.2557, gradient norm: 13.46: 36%|███▌ | 225/625 [00:36<00:56, 7.09it/s]
reward: -3.8088, last reward: -4.5933, gradient norm: 87.13: 36%|███▌ | 225/625 [00:36<00:56, 7.09it/s]
reward: -3.8088, last reward: -4.5933, gradient norm: 87.13: 36%|███▌ | 226/625 [00:36<00:56, 7.11it/s]
reward: -3.0040, last reward: -0.4217, gradient norm: 17.2: 36%|███▌ | 226/625 [00:36<00:56, 7.11it/s]
reward: -3.0040, last reward: -0.4217, gradient norm: 17.2: 36%|███▋ | 227/625 [00:36<00:56, 7.10it/s]
reward: -3.4279, last reward: -4.8894, gradient norm: 26.97: 36%|███▋ | 227/625 [00:36<00:56, 7.10it/s]
reward: -3.4279, last reward: -4.8894, gradient norm: 26.97: 36%|███▋ | 228/625 [00:36<00:55, 7.10it/s]
reward: -3.4752, last reward: -4.5510, gradient norm: 15.18: 36%|███▋ | 228/625 [00:36<00:55, 7.10it/s]
reward: -3.4752, last reward: -4.5510, gradient norm: 15.18: 37%|███▋ | 229/625 [00:36<00:55, 7.10it/s]
reward: -3.5655, last reward: -3.8560, gradient norm: 13.53: 37%|███▋ | 229/625 [00:36<00:55, 7.10it/s]
reward: -3.5655, last reward: -3.8560, gradient norm: 13.53: 37%|███▋ | 230/625 [00:36<00:55, 7.10it/s]
reward: -3.5832, last reward: -4.5859, gradient norm: 18.51: 37%|███▋ | 230/625 [00:36<00:55, 7.10it/s]
reward: -3.5832, last reward: -4.5859, gradient norm: 18.51: 37%|███▋ | 231/625 [00:36<00:55, 7.10it/s]
reward: -3.4270, last reward: -3.9314, gradient norm: 25.38: 37%|███▋ | 231/625 [00:37<00:55, 7.10it/s]
reward: -3.4270, last reward: -3.9314, gradient norm: 25.38: 37%|███▋ | 232/625 [00:37<00:55, 7.10it/s]
reward: -2.6801, last reward: -0.0465, gradient norm: 1.219: 37%|███▋ | 232/625 [00:37<00:55, 7.10it/s]
reward: -2.6801, last reward: -0.0465, gradient norm: 1.219: 37%|███▋ | 233/625 [00:37<00:55, 7.10it/s]
reward: -2.4371, last reward: -0.2514, gradient norm: 1.027: 37%|███▋ | 233/625 [00:37<00:55, 7.10it/s]
reward: -2.4371, last reward: -0.2514, gradient norm: 1.027: 37%|███▋ | 234/625 [00:37<00:55, 7.09it/s]
reward: -1.9119, last reward: -0.0086, gradient norm: 0.3963: 37%|███▋ | 234/625 [00:37<00:55, 7.09it/s]
reward: -1.9119, last reward: -0.0086, gradient norm: 0.3963: 38%|███▊ | 235/625 [00:37<00:54, 7.10it/s]
reward: -2.2868, last reward: -0.0314, gradient norm: 1.253: 38%|███▊ | 235/625 [00:37<00:54, 7.10it/s]
reward: -2.2868, last reward: -0.0314, gradient norm: 1.253: 38%|███▊ | 236/625 [00:37<00:54, 7.11it/s]
reward: -2.4981, last reward: -1.8164, gradient norm: 2.323e+03: 38%|███▊ | 236/625 [00:37<00:54, 7.11it/s]
reward: -2.4981, last reward: -1.8164, gradient norm: 2.323e+03: 38%|███▊ | 237/625 [00:37<00:54, 7.10it/s]
reward: -2.8226, last reward: -0.0547, gradient norm: 3.304: 38%|███▊ | 237/625 [00:37<00:54, 7.10it/s]
reward: -2.8226, last reward: -0.0547, gradient norm: 3.304: 38%|███▊ | 238/625 [00:37<00:54, 7.08it/s]
reward: -2.3598, last reward: -0.0243, gradient norm: 1.2: 38%|███▊ | 238/625 [00:38<00:54, 7.08it/s]
reward: -2.3598, last reward: -0.0243, gradient norm: 1.2: 38%|███▊ | 239/625 [00:38<00:54, 7.07it/s]
reward: -2.4277, last reward: -0.0102, gradient norm: 0.7654: 38%|███▊ | 239/625 [00:38<00:54, 7.07it/s]
reward: -2.4277, last reward: -0.0102, gradient norm: 0.7654: 38%|███▊ | 240/625 [00:38<00:54, 7.09it/s]
reward: -2.4597, last reward: -0.0140, gradient norm: 0.5484: 38%|███▊ | 240/625 [00:38<00:54, 7.09it/s]
reward: -2.4597, last reward: -0.0140, gradient norm: 0.5484: 39%|███▊ | 241/625 [00:38<00:54, 7.09it/s]
reward: -2.6332, last reward: -0.0936, gradient norm: 4.342: 39%|███▊ | 241/625 [00:38<00:54, 7.09it/s]
reward: -2.6332, last reward: -0.0936, gradient norm: 4.342: 39%|███▊ | 242/625 [00:38<00:53, 7.10it/s]
reward: -2.9660, last reward: -1.5286, gradient norm: 24.67: 39%|███▊ | 242/625 [00:38<00:53, 7.10it/s]
reward: -2.9660, last reward: -1.5286, gradient norm: 24.67: 39%|███▉ | 243/625 [00:38<00:53, 7.10it/s]
reward: -3.5287, last reward: -4.6000, gradient norm: 44.27: 39%|███▉ | 243/625 [00:38<00:53, 7.10it/s]
reward: -3.5287, last reward: -4.6000, gradient norm: 44.27: 39%|███▉ | 244/625 [00:38<00:53, 7.10it/s]
reward: -3.6520, last reward: -6.4458, gradient norm: 170.4: 39%|███▉ | 244/625 [00:38<00:53, 7.10it/s]
reward: -3.6520, last reward: -6.4458, gradient norm: 170.4: 39%|███▉ | 245/625 [00:38<00:53, 7.10it/s]
reward: -4.0553, last reward: -4.2439, gradient norm: 44.64: 39%|███▉ | 245/625 [00:39<00:53, 7.10it/s]
reward: -4.0553, last reward: -4.2439, gradient norm: 44.64: 39%|███▉ | 246/625 [00:39<00:53, 7.10it/s]
reward: -4.1800, last reward: -5.4245, gradient norm: 32.39: 39%|███▉ | 246/625 [00:39<00:53, 7.10it/s]
reward: -4.1800, last reward: -5.4245, gradient norm: 32.39: 40%|███▉ | 247/625 [00:39<00:53, 7.10it/s]
reward: -4.1824, last reward: -7.6410, gradient norm: 47.59: 40%|███▉ | 247/625 [00:39<00:53, 7.10it/s]
reward: -4.1824, last reward: -7.6410, gradient norm: 47.59: 40%|███▉ | 248/625 [00:39<00:53, 7.09it/s]
reward: -3.5020, last reward: -3.8314, gradient norm: 19.61: 40%|███▉ | 248/625 [00:39<00:53, 7.09it/s]
reward: -3.5020, last reward: -3.8314, gradient norm: 19.61: 40%|███▉ | 249/625 [00:39<00:53, 7.09it/s]
reward: -3.2288, last reward: -1.1454, gradient norm: 7.098: 40%|███▉ | 249/625 [00:39<00:53, 7.09it/s]
reward: -3.2288, last reward: -1.1454, gradient norm: 7.098: 40%|████ | 250/625 [00:39<01:01, 6.12it/s]
reward: -2.6377, last reward: -0.1748, gradient norm: 10.74: 40%|████ | 250/625 [00:39<01:01, 6.12it/s]
reward: -2.6377, last reward: -0.1748, gradient norm: 10.74: 40%|████ | 251/625 [00:39<00:58, 6.38it/s]
reward: -2.5849, last reward: -0.4664, gradient norm: 3.855: 40%|████ | 251/625 [00:39<00:58, 6.38it/s]
reward: -2.5849, last reward: -0.4664, gradient norm: 3.855: 40%|████ | 252/625 [00:39<00:56, 6.58it/s]
reward: -2.6626, last reward: -0.0258, gradient norm: 1.746: 40%|████ | 252/625 [00:40<00:56, 6.58it/s]
reward: -2.6626, last reward: -0.0258, gradient norm: 1.746: 40%|████ | 253/625 [00:40<00:55, 6.72it/s]
reward: -2.7640, last reward: -0.3000, gradient norm: 0.9674: 40%|████ | 253/625 [00:40<00:55, 6.72it/s]
reward: -2.7640, last reward: -0.3000, gradient norm: 0.9674: 41%|████ | 254/625 [00:40<00:54, 6.84it/s]
reward: -2.6846, last reward: -0.2985, gradient norm: 4.434: 41%|████ | 254/625 [00:40<00:54, 6.84it/s]
reward: -2.6846, last reward: -0.2985, gradient norm: 4.434: 41%|████ | 255/625 [00:40<00:53, 6.90it/s]
reward: -2.5770, last reward: -3.2087, gradient norm: 268.1: 41%|████ | 255/625 [00:40<00:53, 6.90it/s]
reward: -2.5770, last reward: -3.2087, gradient norm: 268.1: 41%|████ | 256/625 [00:40<00:53, 6.95it/s]
reward: -3.4992, last reward: -4.2594, gradient norm: 134.7: 41%|████ | 256/625 [00:40<00:53, 6.95it/s]
reward: -3.4992, last reward: -4.2594, gradient norm: 134.7: 41%|████ | 257/625 [00:40<00:52, 6.99it/s]
reward: -3.7597, last reward: -3.3658, gradient norm: 16.38: 41%|████ | 257/625 [00:40<00:52, 6.99it/s]
reward: -3.7597, last reward: -3.3658, gradient norm: 16.38: 41%|████▏ | 258/625 [00:40<00:52, 7.02it/s]
reward: -4.0933, last reward: -3.4128, gradient norm: 21.93: 41%|████▏ | 258/625 [00:40<00:52, 7.02it/s]
reward: -4.0933, last reward: -3.4128, gradient norm: 21.93: 41%|████▏ | 259/625 [00:40<00:51, 7.05it/s]
reward: -3.8674, last reward: -3.8462, gradient norm: 19.27: 41%|████▏ | 259/625 [00:41<00:51, 7.05it/s]
reward: -3.8674, last reward: -3.8462, gradient norm: 19.27: 42%|████▏ | 260/625 [00:41<00:51, 7.06it/s]
reward: -3.6467, last reward: -3.5475, gradient norm: 20.72: 42%|████▏ | 260/625 [00:41<00:51, 7.06it/s]
reward: -3.6467, last reward: -3.5475, gradient norm: 20.72: 42%|████▏ | 261/625 [00:41<00:51, 7.07it/s]
reward: -3.3097, last reward: -2.0767, gradient norm: 10.15: 42%|████▏ | 261/625 [00:41<00:51, 7.07it/s]
reward: -3.3097, last reward: -2.0767, gradient norm: 10.15: 42%|████▏ | 262/625 [00:41<00:51, 7.08it/s]
reward: -2.9701, last reward: -2.6906, gradient norm: 13.62: 42%|████▏ | 262/625 [00:41<00:51, 7.08it/s]
reward: -2.9701, last reward: -2.6906, gradient norm: 13.62: 42%|████▏ | 263/625 [00:41<00:51, 7.07it/s]
reward: -3.1535, last reward: -2.3035, gradient norm: 26.75: 42%|████▏ | 263/625 [00:41<00:51, 7.07it/s]
reward: -3.1535, last reward: -2.3035, gradient norm: 26.75: 42%|████▏ | 264/625 [00:41<00:50, 7.08it/s]
reward: -2.2709, last reward: -0.0315, gradient norm: 1.458: 42%|████▏ | 264/625 [00:41<00:50, 7.08it/s]
reward: -2.2709, last reward: -0.0315, gradient norm: 1.458: 42%|████▏ | 265/625 [00:41<00:50, 7.07it/s]
reward: -3.2714, last reward: -3.1069, gradient norm: 618.5: 42%|████▏ | 265/625 [00:41<00:50, 7.07it/s]
reward: -3.2714, last reward: -3.1069, gradient norm: 618.5: 43%|████▎ | 266/625 [00:41<00:50, 7.08it/s]
reward: -3.7115, last reward: -2.0835, gradient norm: 34.47: 43%|████▎ | 266/625 [00:42<00:50, 7.08it/s]
reward: -3.7115, last reward: -2.0835, gradient norm: 34.47: 43%|████▎ | 267/625 [00:42<00:50, 7.09it/s]
reward: -2.9508, last reward: -0.5282, gradient norm: 11.39: 43%|████▎ | 267/625 [00:42<00:50, 7.09it/s]
reward: -2.9508, last reward: -0.5282, gradient norm: 11.39: 43%|████▎ | 268/625 [00:42<00:50, 7.09it/s]
reward: -2.7112, last reward: -0.3913, gradient norm: 1.521: 43%|████▎ | 268/625 [00:42<00:50, 7.09it/s]
reward: -2.7112, last reward: -0.3913, gradient norm: 1.521: 43%|████▎ | 269/625 [00:42<00:50, 7.08it/s]
reward: -2.5150, last reward: -0.2569, gradient norm: 2.97: 43%|████▎ | 269/625 [00:42<00:50, 7.08it/s]
reward: -2.5150, last reward: -0.2569, gradient norm: 2.97: 43%|████▎ | 270/625 [00:42<00:50, 7.08it/s]
reward: -2.4584, last reward: -0.1438, gradient norm: 1.479: 43%|████▎ | 270/625 [00:42<00:50, 7.08it/s]
reward: -2.4584, last reward: -0.1438, gradient norm: 1.479: 43%|████▎ | 271/625 [00:42<00:49, 7.08it/s]
reward: -2.5494, last reward: -0.0668, gradient norm: 1.029: 43%|████▎ | 271/625 [00:42<00:49, 7.08it/s]
reward: -2.5494, last reward: -0.0668, gradient norm: 1.029: 44%|████▎ | 272/625 [00:42<00:49, 7.09it/s]
reward: -2.6118, last reward: -1.0917, gradient norm: 8.698: 44%|████▎ | 272/625 [00:42<00:49, 7.09it/s]
reward: -2.6118, last reward: -1.0917, gradient norm: 8.698: 44%|████▎ | 273/625 [00:42<00:49, 7.08it/s]
reward: -2.6721, last reward: -0.8480, gradient norm: 54.61: 44%|████▎ | 273/625 [00:43<00:49, 7.08it/s]
reward: -2.6721, last reward: -0.8480, gradient norm: 54.61: 44%|████▍ | 274/625 [00:43<00:49, 7.10it/s]
reward: -2.6840, last reward: -0.9022, gradient norm: 8.774: 44%|████▍ | 274/625 [00:43<00:49, 7.10it/s]
reward: -2.6840, last reward: -0.9022, gradient norm: 8.774: 44%|████▍ | 275/625 [00:43<00:49, 7.09it/s]
reward: -2.1352, last reward: -0.1595, gradient norm: 1.338: 44%|████▍ | 275/625 [00:43<00:49, 7.09it/s]
reward: -2.1352, last reward: -0.1595, gradient norm: 1.338: 44%|████▍ | 276/625 [00:43<00:49, 7.09it/s]
reward: -2.7317, last reward: -0.0050, gradient norm: 1.251: 44%|████▍ | 276/625 [00:43<00:49, 7.09it/s]
reward: -2.7317, last reward: -0.0050, gradient norm: 1.251: 44%|████▍ | 277/625 [00:43<00:49, 7.08it/s]
reward: -2.3981, last reward: -0.3232, gradient norm: 1.077: 44%|████▍ | 277/625 [00:43<00:49, 7.08it/s]
reward: -2.3981, last reward: -0.3232, gradient norm: 1.077: 44%|████▍ | 278/625 [00:43<00:48, 7.08it/s]
reward: -2.0717, last reward: -0.0285, gradient norm: 1.305: 44%|████▍ | 278/625 [00:43<00:48, 7.08it/s]
reward: -2.0717, last reward: -0.0285, gradient norm: 1.305: 45%|████▍ | 279/625 [00:43<00:48, 7.09it/s]
reward: -1.9624, last reward: -0.0525, gradient norm: 1.907: 45%|████▍ | 279/625 [00:43<00:48, 7.09it/s]
reward: -1.9624, last reward: -0.0525, gradient norm: 1.907: 45%|████▍ | 280/625 [00:43<00:48, 7.09it/s]
reward: -2.0721, last reward: -0.0420, gradient norm: 1.515: 45%|████▍ | 280/625 [00:44<00:48, 7.09it/s]
reward: -2.0721, last reward: -0.0420, gradient norm: 1.515: 45%|████▍ | 281/625 [00:44<00:48, 7.09it/s]
reward: -2.6147, last reward: -0.0159, gradient norm: 0.9426: 45%|████▍ | 281/625 [00:44<00:48, 7.09it/s]
reward: -2.6147, last reward: -0.0159, gradient norm: 0.9426: 45%|████▌ | 282/625 [00:44<00:48, 7.09it/s]
reward: -2.6070, last reward: -0.0004, gradient norm: 0.8828: 45%|████▌ | 282/625 [00:44<00:48, 7.09it/s]
reward: -2.6070, last reward: -0.0004, gradient norm: 0.8828: 45%|████▌ | 283/625 [00:44<00:48, 7.08it/s]
reward: -1.5955, last reward: -0.0054, gradient norm: 0.8221: 45%|████▌ | 283/625 [00:44<00:48, 7.08it/s]
reward: -1.5955, last reward: -0.0054, gradient norm: 0.8221: 45%|████▌ | 284/625 [00:44<00:48, 7.09it/s]
reward: -2.2961, last reward: -0.0100, gradient norm: 0.6415: 45%|████▌ | 284/625 [00:44<00:48, 7.09it/s]
reward: -2.2961, last reward: -0.0100, gradient norm: 0.6415: 46%|████▌ | 285/625 [00:44<00:47, 7.10it/s]
reward: -2.1455, last reward: -0.0401, gradient norm: 4.477: 46%|████▌ | 285/625 [00:44<00:47, 7.10it/s]
reward: -2.1455, last reward: -0.0401, gradient norm: 4.477: 46%|████▌ | 286/625 [00:44<00:47, 7.09it/s]
reward: -2.3202, last reward: -0.0109, gradient norm: 1.261: 46%|████▌ | 286/625 [00:44<00:47, 7.09it/s]
reward: -2.3202, last reward: -0.0109, gradient norm: 1.261: 46%|████▌ | 287/625 [00:44<00:47, 7.09it/s]
reward: -1.8493, last reward: -0.0003, gradient norm: 0.2791: 46%|████▌ | 287/625 [00:45<00:47, 7.09it/s]
reward: -1.8493, last reward: -0.0003, gradient norm: 0.2791: 46%|████▌ | 288/625 [00:45<00:47, 7.10it/s]
reward: -2.1976, last reward: -0.0175, gradient norm: 1.303: 46%|████▌ | 288/625 [00:45<00:47, 7.10it/s]
reward: -2.1976, last reward: -0.0175, gradient norm: 1.303: 46%|████▌ | 289/625 [00:45<00:47, 7.09it/s]
reward: -2.2161, last reward: -0.0341, gradient norm: 1.249: 46%|████▌ | 289/625 [00:45<00:47, 7.09it/s]
reward: -2.2161, last reward: -0.0341, gradient norm: 1.249: 46%|████▋ | 290/625 [00:45<00:47, 7.10it/s]
reward: -2.2978, last reward: -0.0009, gradient norm: 7.537: 46%|████▋ | 290/625 [00:45<00:47, 7.10it/s]
reward: -2.2978, last reward: -0.0009, gradient norm: 7.537: 47%|████▋ | 291/625 [00:45<00:47, 7.10it/s]
reward: -2.1569, last reward: -0.0014, gradient norm: 0.5816: 47%|████▋ | 291/625 [00:45<00:47, 7.10it/s]
reward: -2.1569, last reward: -0.0014, gradient norm: 0.5816: 47%|████▋ | 292/625 [00:45<00:47, 7.08it/s]
reward: -2.1375, last reward: -0.0025, gradient norm: 0.9851: 47%|████▋ | 292/625 [00:45<00:47, 7.08it/s]
reward: -2.1375, last reward: -0.0025, gradient norm: 0.9851: 47%|████▋ | 293/625 [00:45<00:46, 7.09it/s]
reward: -2.3263, last reward: -0.0796, gradient norm: 0.9019: 47%|████▋ | 293/625 [00:45<00:46, 7.09it/s]
reward: -2.3263, last reward: -0.0796, gradient norm: 0.9019: 47%|████▋ | 294/625 [00:45<00:46, 7.08it/s]
reward: -2.3135, last reward: -0.0134, gradient norm: 0.6067: 47%|████▋ | 294/625 [00:45<00:46, 7.08it/s]
reward: -2.3135, last reward: -0.0134, gradient norm: 0.6067: 47%|████▋ | 295/625 [00:45<00:46, 7.09it/s]
reward: -2.3134, last reward: -0.0123, gradient norm: 7.358: 47%|████▋ | 295/625 [00:46<00:46, 7.09it/s]
reward: -2.3134, last reward: -0.0123, gradient norm: 7.358: 47%|████▋ | 296/625 [00:46<00:46, 7.09it/s]
reward: -2.0462, last reward: -0.0983, gradient norm: 2.24: 47%|████▋ | 296/625 [00:46<00:46, 7.09it/s]
reward: -2.0462, last reward: -0.0983, gradient norm: 2.24: 48%|████▊ | 297/625 [00:46<00:46, 7.09it/s]
reward: -2.4906, last reward: -0.1974, gradient norm: 6.168: 48%|████▊ | 297/625 [00:46<00:46, 7.09it/s]
reward: -2.4906, last reward: -0.1974, gradient norm: 6.168: 48%|████▊ | 298/625 [00:46<00:46, 7.09it/s]
reward: -2.1455, last reward: -0.4289, gradient norm: 35.79: 48%|████▊ | 298/625 [00:46<00:46, 7.09it/s]
reward: -2.1455, last reward: -0.4289, gradient norm: 35.79: 48%|████▊ | 299/625 [00:46<00:45, 7.09it/s]
reward: -2.3096, last reward: -0.1003, gradient norm: 8.365: 48%|████▊ | 299/625 [00:46<00:45, 7.09it/s]
reward: -2.3096, last reward: -0.1003, gradient norm: 8.365: 48%|████▊ | 300/625 [00:46<00:45, 7.10it/s]
reward: -2.8362, last reward: -4.0767, gradient norm: 149.4: 48%|████▊ | 300/625 [00:46<00:45, 7.10it/s]
reward: -2.8362, last reward: -4.0767, gradient norm: 149.4: 48%|████▊ | 301/625 [00:46<00:45, 7.09it/s]
reward: -2.9784, last reward: -3.9554, gradient norm: 103.0: 48%|████▊ | 301/625 [00:46<00:45, 7.09it/s]
reward: -2.9784, last reward: -3.9554, gradient norm: 103.0: 48%|████▊ | 302/625 [00:46<00:45, 7.11it/s]
reward: -3.4267, last reward: -6.2200, gradient norm: 96.92: 48%|████▊ | 302/625 [00:47<00:45, 7.11it/s]
reward: -3.4267, last reward: -6.2200, gradient norm: 96.92: 48%|████▊ | 303/625 [00:47<00:45, 7.10it/s]
reward: -3.6572, last reward: -4.1549, gradient norm: 53.57: 48%|████▊ | 303/625 [00:47<00:45, 7.10it/s]
reward: -3.6572, last reward: -4.1549, gradient norm: 53.57: 49%|████▊ | 304/625 [00:47<00:45, 7.09it/s]
reward: -2.5855, last reward: -2.0066, gradient norm: 56.78: 49%|████▊ | 304/625 [00:47<00:45, 7.09it/s]
reward: -2.5855, last reward: -2.0066, gradient norm: 56.78: 49%|████▉ | 305/625 [00:47<00:45, 7.08it/s]
reward: -3.2721, last reward: -2.2845, gradient norm: 19.16: 49%|████▉ | 305/625 [00:47<00:45, 7.08it/s]
reward: -3.2721, last reward: -2.2845, gradient norm: 19.16: 49%|████▉ | 306/625 [00:47<00:45, 7.07it/s]
reward: -3.2601, last reward: -1.9150, gradient norm: 8.848: 49%|████▉ | 306/625 [00:47<00:45, 7.07it/s]
reward: -3.2601, last reward: -1.9150, gradient norm: 8.848: 49%|████▉ | 307/625 [00:47<00:44, 7.08it/s]
reward: -3.0374, last reward: -2.6212, gradient norm: 25.96: 49%|████▉ | 307/625 [00:47<00:44, 7.08it/s]
reward: -3.0374, last reward: -2.6212, gradient norm: 25.96: 49%|████▉ | 308/625 [00:47<00:44, 7.09it/s]
reward: -2.8294, last reward: -2.2145, gradient norm: 45.29: 49%|████▉ | 308/625 [00:47<00:44, 7.09it/s]
reward: -2.8294, last reward: -2.2145, gradient norm: 45.29: 49%|████▉ | 309/625 [00:47<00:44, 7.10it/s]
reward: -2.0199, last reward: -0.1257, gradient norm: 9.448: 49%|████▉ | 309/625 [00:48<00:44, 7.10it/s]
reward: -2.0199, last reward: -0.1257, gradient norm: 9.448: 50%|████▉ | 310/625 [00:48<00:44, 7.10it/s]
reward: -3.3198, last reward: -4.0158, gradient norm: 219.2: 50%|████▉ | 310/625 [00:48<00:44, 7.10it/s]
reward: -3.3198, last reward: -4.0158, gradient norm: 219.2: 50%|████▉ | 311/625 [00:48<00:44, 7.10it/s]
reward: -3.0789, last reward: -3.2260, gradient norm: 296.5: 50%|████▉ | 311/625 [00:48<00:44, 7.10it/s]
reward: -3.0789, last reward: -3.2260, gradient norm: 296.5: 50%|████▉ | 312/625 [00:48<00:44, 7.10it/s]
reward: -2.1556, last reward: -0.3926, gradient norm: 29.93: 50%|████▉ | 312/625 [00:48<00:44, 7.10it/s]
reward: -2.1556, last reward: -0.3926, gradient norm: 29.93: 50%|█████ | 313/625 [00:48<00:44, 7.09it/s]
reward: -2.1873, last reward: -0.0914, gradient norm: 12.39: 50%|█████ | 313/625 [00:48<00:44, 7.09it/s]
reward: -2.1873, last reward: -0.0914, gradient norm: 12.39: 50%|█████ | 314/625 [00:48<00:43, 7.09it/s]
reward: -2.1722, last reward: -0.1153, gradient norm: 6.465: 50%|█████ | 314/625 [00:48<00:43, 7.09it/s]
reward: -2.1722, last reward: -0.1153, gradient norm: 6.465: 50%|█████ | 315/625 [00:48<00:43, 7.09it/s]
reward: -2.2372, last reward: -0.1147, gradient norm: 4.018: 50%|█████ | 315/625 [00:48<00:43, 7.09it/s]
reward: -2.2372, last reward: -0.1147, gradient norm: 4.018: 51%|█████ | 316/625 [00:48<00:43, 7.10it/s]
reward: -2.1297, last reward: -0.0374, gradient norm: 1.765: 51%|█████ | 316/625 [00:49<00:43, 7.10it/s]
reward: -2.1297, last reward: -0.0374, gradient norm: 1.765: 51%|█████ | 317/625 [00:49<00:43, 7.10it/s]
reward: -2.0966, last reward: -0.0191, gradient norm: 1.25: 51%|█████ | 317/625 [00:49<00:43, 7.10it/s]
reward: -2.0966, last reward: -0.0191, gradient norm: 1.25: 51%|█████ | 318/625 [00:49<00:43, 7.09it/s]
reward: -2.2577, last reward: -0.1091, gradient norm: 21.0: 51%|█████ | 318/625 [00:49<00:43, 7.09it/s]
reward: -2.2577, last reward: -0.1091, gradient norm: 21.0: 51%|█████ | 319/625 [00:49<00:43, 7.09it/s]
reward: -1.9169, last reward: -0.0056, gradient norm: 0.6862: 51%|█████ | 319/625 [00:49<00:43, 7.09it/s]
reward: -1.9169, last reward: -0.0056, gradient norm: 0.6862: 51%|█████ | 320/625 [00:49<00:42, 7.10it/s]
reward: -1.9978, last reward: -0.0063, gradient norm: 0.7697: 51%|█████ | 320/625 [00:49<00:42, 7.10it/s]
reward: -1.9978, last reward: -0.0063, gradient norm: 0.7697: 51%|█████▏ | 321/625 [00:49<00:42, 7.10it/s]
reward: -1.9404, last reward: -0.0073, gradient norm: 0.6161: 51%|█████▏ | 321/625 [00:49<00:42, 7.10it/s]
reward: -1.9404, last reward: -0.0073, gradient norm: 0.6161: 52%|█████▏ | 322/625 [00:49<00:42, 7.10it/s]
reward: -2.3151, last reward: -0.0044, gradient norm: 0.3834: 52%|█████▏ | 322/625 [00:49<00:42, 7.10it/s]
reward: -2.3151, last reward: -0.0044, gradient norm: 0.3834: 52%|█████▏ | 323/625 [00:49<00:42, 7.10it/s]
reward: -1.9112, last reward: -0.0005, gradient norm: 0.9354: 52%|█████▏ | 323/625 [00:50<00:42, 7.10it/s]
reward: -1.9112, last reward: -0.0005, gradient norm: 0.9354: 52%|█████▏ | 324/625 [00:50<00:42, 7.09it/s]
reward: -2.0011, last reward: -0.0058, gradient norm: 0.7869: 52%|█████▏ | 324/625 [00:50<00:42, 7.09it/s]
reward: -2.0011, last reward: -0.0058, gradient norm: 0.7869: 52%|█████▏ | 325/625 [00:50<00:42, 7.09it/s]
reward: -2.0421, last reward: -0.0203, gradient norm: 1.082: 52%|█████▏ | 325/625 [00:50<00:42, 7.09it/s]
reward: -2.0421, last reward: -0.0203, gradient norm: 1.082: 52%|█████▏ | 326/625 [00:50<00:42, 7.10it/s]
reward: -2.5248, last reward: -0.0071, gradient norm: 0.4845: 52%|█████▏ | 326/625 [00:50<00:42, 7.10it/s]
reward: -2.5248, last reward: -0.0071, gradient norm: 0.4845: 52%|█████▏ | 327/625 [00:50<00:42, 7.09it/s]
reward: -2.3040, last reward: -0.0009, gradient norm: 1.656: 52%|█████▏ | 327/625 [00:50<00:42, 7.09it/s]
reward: -2.3040, last reward: -0.0009, gradient norm: 1.656: 52%|█████▏ | 328/625 [00:50<00:41, 7.08it/s]
reward: -2.2347, last reward: -0.2483, gradient norm: 1.621: 52%|█████▏ | 328/625 [00:50<00:41, 7.08it/s]
reward: -2.2347, last reward: -0.2483, gradient norm: 1.621: 53%|█████▎ | 329/625 [00:50<00:41, 7.08it/s]
reward: -2.2946, last reward: -0.0011, gradient norm: 0.2357: 53%|█████▎ | 329/625 [00:50<00:41, 7.08it/s]
reward: -2.2946, last reward: -0.0011, gradient norm: 0.2357: 53%|█████▎ | 330/625 [00:50<00:41, 7.08it/s]
reward: -2.0174, last reward: -0.0056, gradient norm: 0.5856: 53%|█████▎ | 330/625 [00:51<00:41, 7.08it/s]
reward: -2.0174, last reward: -0.0056, gradient norm: 0.5856: 53%|█████▎ | 331/625 [00:51<00:41, 7.09it/s]
reward: -1.9533, last reward: -0.0030, gradient norm: 5.895: 53%|█████▎ | 331/625 [00:51<00:41, 7.09it/s]
reward: -1.9533, last reward: -0.0030, gradient norm: 5.895: 53%|█████▎ | 332/625 [00:51<00:41, 7.09it/s]
reward: -2.2887, last reward: -0.0058, gradient norm: 0.7964: 53%|█████▎ | 332/625 [00:51<00:41, 7.09it/s]
reward: -2.2887, last reward: -0.0058, gradient norm: 0.7964: 53%|█████▎ | 333/625 [00:51<00:41, 7.08it/s]
reward: -2.2153, last reward: -0.0106, gradient norm: 0.8594: 53%|█████▎ | 333/625 [00:51<00:41, 7.08it/s]
reward: -2.2153, last reward: -0.0106, gradient norm: 0.8594: 53%|█████▎ | 334/625 [00:51<00:41, 7.09it/s]
reward: -2.4258, last reward: -0.0017, gradient norm: 22.62: 53%|█████▎ | 334/625 [00:51<00:41, 7.09it/s]
reward: -2.4258, last reward: -0.0017, gradient norm: 22.62: 54%|█████▎ | 335/625 [00:51<00:40, 7.09it/s]
reward: -2.0452, last reward: -0.2152, gradient norm: 28.28: 54%|█████▎ | 335/625 [00:51<00:40, 7.09it/s]
reward: -2.0452, last reward: -0.2152, gradient norm: 28.28: 54%|█████▍ | 336/625 [00:51<00:40, 7.09it/s]
reward: -2.2464, last reward: -0.0105, gradient norm: 2.342: 54%|█████▍ | 336/625 [00:51<00:40, 7.09it/s]
reward: -2.2464, last reward: -0.0105, gradient norm: 2.342: 54%|█████▍ | 337/625 [00:51<00:40, 7.09it/s]
reward: -1.9889, last reward: -0.0041, gradient norm: 0.9867: 54%|█████▍ | 337/625 [00:52<00:40, 7.09it/s]
reward: -1.9889, last reward: -0.0041, gradient norm: 0.9867: 54%|█████▍ | 338/625 [00:52<00:40, 7.10it/s]
reward: -2.2916, last reward: -3.1787, gradient norm: 149.6: 54%|█████▍ | 338/625 [00:52<00:40, 7.10it/s]
reward: -2.2916, last reward: -3.1787, gradient norm: 149.6: 54%|█████▍ | 339/625 [00:52<00:40, 7.09it/s]
reward: -2.4023, last reward: -2.0749, gradient norm: 75.36: 54%|█████▍ | 339/625 [00:52<00:40, 7.09it/s]
reward: -2.4023, last reward: -2.0749, gradient norm: 75.36: 54%|█████▍ | 340/625 [00:52<00:40, 7.08it/s]
reward: -2.2001, last reward: -0.0021, gradient norm: 0.9488: 54%|█████▍ | 340/625 [00:52<00:40, 7.08it/s]
reward: -2.2001, last reward: -0.0021, gradient norm: 0.9488: 55%|█████▍ | 341/625 [00:52<00:40, 7.08it/s]
reward: -2.5049, last reward: -0.0090, gradient norm: 1.483: 55%|█████▍ | 341/625 [00:52<00:40, 7.08it/s]
reward: -2.5049, last reward: -0.0090, gradient norm: 1.483: 55%|█████▍ | 342/625 [00:52<00:40, 7.07it/s]
reward: -2.4436, last reward: -0.2976, gradient norm: 21.53: 55%|█████▍ | 342/625 [00:52<00:40, 7.07it/s]
reward: -2.4436, last reward: -0.2976, gradient norm: 21.53: 55%|█████▍ | 343/625 [00:52<00:39, 7.08it/s]
reward: -2.3014, last reward: -0.0075, gradient norm: 5.006: 55%|█████▍ | 343/625 [00:52<00:39, 7.08it/s]
reward: -2.3014, last reward: -0.0075, gradient norm: 5.006: 55%|█████▌ | 344/625 [00:52<00:39, 7.09it/s]
reward: -2.4856, last reward: -0.0495, gradient norm: 1.689: 55%|█████▌ | 344/625 [00:53<00:39, 7.09it/s]
reward: -2.4856, last reward: -0.0495, gradient norm: 1.689: 55%|█████▌ | 345/625 [00:53<00:39, 7.09it/s]
reward: -1.9798, last reward: -0.5065, gradient norm: 43.82: 55%|█████▌ | 345/625 [00:53<00:39, 7.09it/s]
reward: -1.9798, last reward: -0.5065, gradient norm: 43.82: 55%|█████▌ | 346/625 [00:53<00:39, 7.09it/s]
reward: -2.3666, last reward: -0.1225, gradient norm: 5.205: 55%|█████▌ | 346/625 [00:53<00:39, 7.09it/s]
reward: -2.3666, last reward: -0.1225, gradient norm: 5.205: 56%|█████▌ | 347/625 [00:53<00:39, 7.09it/s]
reward: -2.5406, last reward: -2.7987, gradient norm: 385.7: 56%|█████▌ | 347/625 [00:53<00:39, 7.09it/s]
reward: -2.5406, last reward: -2.7987, gradient norm: 385.7: 56%|█████▌ | 348/625 [00:53<00:39, 7.09it/s]
reward: -2.1750, last reward: -0.0835, gradient norm: 10.56: 56%|█████▌ | 348/625 [00:53<00:39, 7.09it/s]
reward: -2.1750, last reward: -0.0835, gradient norm: 10.56: 56%|█████▌ | 349/625 [00:53<00:38, 7.09it/s]
reward: -2.0369, last reward: -0.0596, gradient norm: 3.581: 56%|█████▌ | 349/625 [00:53<00:38, 7.09it/s]
reward: -2.0369, last reward: -0.0596, gradient norm: 3.581: 56%|█████▌ | 350/625 [00:53<00:38, 7.09it/s]
reward: -2.2212, last reward: -0.6624, gradient norm: 25.2: 56%|█████▌ | 350/625 [00:53<00:38, 7.09it/s]
reward: -2.2212, last reward: -0.6624, gradient norm: 25.2: 56%|█████▌ | 351/625 [00:53<00:38, 7.09it/s]
reward: -2.0448, last reward: -0.0086, gradient norm: 0.4554: 56%|█████▌ | 351/625 [00:54<00:38, 7.09it/s]
reward: -2.0448, last reward: -0.0086, gradient norm: 0.4554: 56%|█████▋ | 352/625 [00:54<00:38, 7.10it/s]
reward: -1.6563, last reward: -0.0087, gradient norm: 4.585: 56%|█████▋ | 352/625 [00:54<00:38, 7.10it/s]
reward: -1.6563, last reward: -0.0087, gradient norm: 4.585: 56%|█████▋ | 353/625 [00:54<00:44, 6.13it/s]
reward: -2.3868, last reward: -0.0579, gradient norm: 2.989: 56%|█████▋ | 353/625 [00:54<00:44, 6.13it/s]
reward: -2.3868, last reward: -0.0579, gradient norm: 2.989: 57%|█████▋ | 354/625 [00:54<00:42, 6.38it/s]
reward: -2.2804, last reward: -0.0574, gradient norm: 3.614: 57%|█████▋ | 354/625 [00:54<00:42, 6.38it/s]
reward: -2.2804, last reward: -0.0574, gradient norm: 3.614: 57%|█████▋ | 355/625 [00:54<00:41, 6.57it/s]
reward: -2.3894, last reward: -0.0100, gradient norm: 3.131: 57%|█████▋ | 355/625 [00:54<00:41, 6.57it/s]
reward: -2.3894, last reward: -0.0100, gradient norm: 3.131: 57%|█████▋ | 356/625 [00:54<00:40, 6.72it/s]
reward: -2.2826, last reward: -0.0131, gradient norm: 2.49: 57%|█████▋ | 356/625 [00:54<00:40, 6.72it/s]
reward: -2.2826, last reward: -0.0131, gradient norm: 2.49: 57%|█████▋ | 357/625 [00:54<00:39, 6.83it/s]
reward: -1.9829, last reward: -0.0021, gradient norm: 1.389: 57%|█████▋ | 357/625 [00:54<00:39, 6.83it/s]
reward: -1.9829, last reward: -0.0021, gradient norm: 1.389: 57%|█████▋ | 358/625 [00:54<00:38, 6.90it/s]
reward: -2.3638, last reward: -0.0014, gradient norm: 0.3864: 57%|█████▋ | 358/625 [00:55<00:38, 6.90it/s]
reward: -2.3638, last reward: -0.0014, gradient norm: 0.3864: 57%|█████▋ | 359/625 [00:55<00:38, 6.95it/s]
reward: -2.0771, last reward: -0.0018, gradient norm: 1.078: 57%|█████▋ | 359/625 [00:55<00:38, 6.95it/s]
reward: -2.0771, last reward: -0.0018, gradient norm: 1.078: 58%|█████▊ | 360/625 [00:55<00:37, 6.98it/s]
reward: -2.2975, last reward: -0.0083, gradient norm: 9.406: 58%|█████▊ | 360/625 [00:55<00:37, 6.98it/s]
reward: -2.2975, last reward: -0.0083, gradient norm: 9.406: 58%|█████▊ | 361/625 [00:55<00:37, 7.00it/s]
reward: -2.1334, last reward: -0.0013, gradient norm: 0.3792: 58%|█████▊ | 361/625 [00:55<00:37, 7.00it/s]
reward: -2.1334, last reward: -0.0013, gradient norm: 0.3792: 58%|█████▊ | 362/625 [00:55<00:37, 7.02it/s]
reward: -2.3140, last reward: -0.0044, gradient norm: 0.4882: 58%|█████▊ | 362/625 [00:55<00:37, 7.02it/s]
reward: -2.3140, last reward: -0.0044, gradient norm: 0.4882: 58%|█████▊ | 363/625 [00:55<00:37, 7.04it/s]
reward: -2.0890, last reward: -0.0012, gradient norm: 16.77: 58%|█████▊ | 363/625 [00:55<00:37, 7.04it/s]
reward: -2.0890, last reward: -0.0012, gradient norm: 16.77: 58%|█████▊ | 364/625 [00:55<00:36, 7.06it/s]
reward: -3.2832, last reward: -1.9131, gradient norm: 26.35: 58%|█████▊ | 364/625 [00:55<00:36, 7.06it/s]
reward: -3.2832, last reward: -1.9131, gradient norm: 26.35: 58%|█████▊ | 365/625 [00:55<00:36, 7.08it/s]
reward: -3.3763, last reward: -2.0796, gradient norm: 29.12: 58%|█████▊ | 365/625 [00:56<00:36, 7.08it/s]
reward: -3.3763, last reward: -2.0796, gradient norm: 29.12: 59%|█████▊ | 366/625 [00:56<00:36, 7.08it/s]
reward: -2.6330, last reward: -1.0133, gradient norm: 65.87: 59%|█████▊ | 366/625 [00:56<00:36, 7.08it/s]
reward: -2.6330, last reward: -1.0133, gradient norm: 65.87: 59%|█████▊ | 367/625 [00:56<00:36, 7.08it/s]
reward: -2.2079, last reward: -0.0368, gradient norm: 5.533: 59%|█████▊ | 367/625 [00:56<00:36, 7.08it/s]
reward: -2.2079, last reward: -0.0368, gradient norm: 5.533: 59%|█████▉ | 368/625 [00:56<00:36, 7.08it/s]
reward: -3.5991, last reward: -2.5106, gradient norm: 39.52: 59%|█████▉ | 368/625 [00:56<00:36, 7.08it/s]
reward: -3.5991, last reward: -2.5106, gradient norm: 39.52: 59%|█████▉ | 369/625 [00:56<00:36, 7.07it/s]
reward: -3.7742, last reward: -6.6952, gradient norm: 43.92: 59%|█████▉ | 369/625 [00:56<00:36, 7.07it/s]
reward: -3.7742, last reward: -6.6952, gradient norm: 43.92: 59%|█████▉ | 370/625 [00:56<00:36, 7.08it/s]
reward: -3.8548, last reward: -5.1412, gradient norm: 34.97: 59%|█████▉ | 370/625 [00:56<00:36, 7.08it/s]
reward: -3.8548, last reward: -5.1412, gradient norm: 34.97: 59%|█████▉ | 371/625 [00:56<00:35, 7.08it/s]
reward: -3.2832, last reward: -2.9745, gradient norm: 59.14: 59%|█████▉ | 371/625 [00:56<00:35, 7.08it/s]
reward: -3.2832, last reward: -2.9745, gradient norm: 59.14: 60%|█████▉ | 372/625 [00:56<00:35, 7.08it/s]
reward: -2.3242, last reward: -0.0805, gradient norm: 1.83: 60%|█████▉ | 372/625 [00:57<00:35, 7.08it/s]
reward: -2.3242, last reward: -0.0805, gradient norm: 1.83: 60%|█████▉ | 373/625 [00:57<00:35, 7.08it/s]
reward: -2.2801, last reward: -0.0072, gradient norm: 10.38: 60%|█████▉ | 373/625 [00:57<00:35, 7.08it/s]
reward: -2.2801, last reward: -0.0072, gradient norm: 10.38: 60%|█████▉ | 374/625 [00:57<00:35, 7.08it/s]
reward: -2.9493, last reward: -1.0834, gradient norm: 23.05: 60%|█████▉ | 374/625 [00:57<00:35, 7.08it/s]
reward: -2.9493, last reward: -1.0834, gradient norm: 23.05: 60%|██████ | 375/625 [00:57<00:35, 7.09it/s]
reward: -2.9784, last reward: -2.0682, gradient norm: 20.07: 60%|██████ | 375/625 [00:57<00:35, 7.09it/s]
reward: -2.9784, last reward: -2.0682, gradient norm: 20.07: 60%|██████ | 376/625 [00:57<00:35, 7.09it/s]
reward: -3.0431, last reward: -1.5964, gradient norm: 11.32: 60%|██████ | 376/625 [00:57<00:35, 7.09it/s]
reward: -3.0431, last reward: -1.5964, gradient norm: 11.32: 60%|██████ | 377/625 [00:57<00:34, 7.09it/s]
reward: -3.0596, last reward: -3.5073, gradient norm: 24.96: 60%|██████ | 377/625 [00:57<00:34, 7.09it/s]
reward: -3.0596, last reward: -3.5073, gradient norm: 24.96: 60%|██████ | 378/625 [00:57<00:34, 7.09it/s]
reward: -2.9091, last reward: -3.4875, gradient norm: 57.41: 60%|██████ | 378/625 [00:57<00:34, 7.09it/s]
reward: -2.9091, last reward: -3.4875, gradient norm: 57.41: 61%|██████ | 379/625 [00:57<00:34, 7.09it/s]
reward: -3.0014, last reward: -0.7015, gradient norm: 4.368: 61%|██████ | 379/625 [00:58<00:34, 7.09it/s]
reward: -3.0014, last reward: -0.7015, gradient norm: 4.368: 61%|██████ | 380/625 [00:58<00:34, 7.08it/s]
reward: -2.6670, last reward: -0.7604, gradient norm: 54.15: 61%|██████ | 380/625 [00:58<00:34, 7.08it/s]
reward: -2.6670, last reward: -0.7604, gradient norm: 54.15: 61%|██████ | 381/625 [00:58<00:34, 7.09it/s]
reward: -2.0919, last reward: -0.3658, gradient norm: 5.152: 61%|██████ | 381/625 [00:58<00:34, 7.09it/s]
reward: -2.0919, last reward: -0.3658, gradient norm: 5.152: 61%|██████ | 382/625 [00:58<00:34, 7.08it/s]
reward: -2.3628, last reward: -0.6303, gradient norm: 29.39: 61%|██████ | 382/625 [00:58<00:34, 7.08it/s]
reward: -2.3628, last reward: -0.6303, gradient norm: 29.39: 61%|██████▏ | 383/625 [00:58<00:34, 7.07it/s]
reward: -1.5676, last reward: -0.0177, gradient norm: 1.275: 61%|██████▏ | 383/625 [00:58<00:34, 7.07it/s]
reward: -1.5676, last reward: -0.0177, gradient norm: 1.275: 61%|██████▏ | 384/625 [00:58<00:34, 7.09it/s]
reward: -2.3084, last reward: -0.0064, gradient norm: 1.077: 61%|██████▏ | 384/625 [00:58<00:34, 7.09it/s]
reward: -2.3084, last reward: -0.0064, gradient norm: 1.077: 62%|██████▏ | 385/625 [00:58<00:33, 7.09it/s]
reward: -2.1459, last reward: -0.0019, gradient norm: 0.5835: 62%|██████▏ | 385/625 [00:58<00:33, 7.09it/s]
reward: -2.1459, last reward: -0.0019, gradient norm: 0.5835: 62%|██████▏ | 386/625 [00:58<00:33, 7.08it/s]
reward: -2.2966, last reward: -0.0036, gradient norm: 0.4661: 62%|██████▏ | 386/625 [00:59<00:33, 7.08it/s]
reward: -2.2966, last reward: -0.0036, gradient norm: 0.4661: 62%|██████▏ | 387/625 [00:59<00:33, 7.08it/s]
reward: -2.0420, last reward: -0.0255, gradient norm: 1.635: 62%|██████▏ | 387/625 [00:59<00:33, 7.08it/s]
reward: -2.0420, last reward: -0.0255, gradient norm: 1.635: 62%|██████▏ | 388/625 [00:59<00:33, 7.08it/s]
reward: -2.1864, last reward: -0.0177, gradient norm: 1.203: 62%|██████▏ | 388/625 [00:59<00:33, 7.08it/s]
reward: -2.1864, last reward: -0.0177, gradient norm: 1.203: 62%|██████▏ | 389/625 [00:59<00:33, 7.08it/s]
reward: -2.1736, last reward: -0.0001, gradient norm: 0.2283: 62%|██████▏ | 389/625 [00:59<00:33, 7.08it/s]
reward: -2.1736, last reward: -0.0001, gradient norm: 0.2283: 62%|██████▏ | 390/625 [00:59<00:33, 7.08it/s]
reward: -1.9308, last reward: -0.0081, gradient norm: 0.9363: 62%|██████▏ | 390/625 [00:59<00:33, 7.08it/s]
reward: -1.9308, last reward: -0.0081, gradient norm: 0.9363: 63%|██████▎ | 391/625 [00:59<00:33, 7.08it/s]
reward: -2.1944, last reward: -0.6936, gradient norm: 12.0: 63%|██████▎ | 391/625 [00:59<00:33, 7.08it/s]
reward: -2.1944, last reward: -0.6936, gradient norm: 12.0: 63%|██████▎ | 392/625 [00:59<00:32, 7.07it/s]
reward: -2.3830, last reward: -0.5445, gradient norm: 22.5: 63%|██████▎ | 392/625 [00:59<00:32, 7.07it/s]
reward: -2.3830, last reward: -0.5445, gradient norm: 22.5: 63%|██████▎ | 393/625 [00:59<00:32, 7.08it/s]
reward: -2.9010, last reward: -3.4259, gradient norm: 993.1: 63%|██████▎ | 393/625 [01:00<00:32, 7.08it/s]
reward: -2.9010, last reward: -3.4259, gradient norm: 993.1: 63%|██████▎ | 394/625 [01:00<00:32, 7.07it/s]
reward: -2.4837, last reward: -0.2650, gradient norm: 7.848: 63%|██████▎ | 394/625 [01:00<00:32, 7.07it/s]
reward: -2.4837, last reward: -0.2650, gradient norm: 7.848: 63%|██████▎ | 395/625 [01:00<00:32, 7.08it/s]
reward: -2.7806, last reward: -1.0255, gradient norm: 169.0: 63%|██████▎ | 395/625 [01:00<00:32, 7.08it/s]
reward: -2.7806, last reward: -1.0255, gradient norm: 169.0: 63%|██████▎ | 396/625 [01:00<00:32, 7.08it/s]
reward: -2.6828, last reward: -0.1375, gradient norm: 57.55: 63%|██████▎ | 396/625 [01:00<00:32, 7.08it/s]
reward: -2.6828, last reward: -0.1375, gradient norm: 57.55: 64%|██████▎ | 397/625 [01:00<00:32, 7.09it/s]
reward: -2.5411, last reward: -0.1041, gradient norm: 2.372: 64%|██████▎ | 397/625 [01:00<00:32, 7.09it/s]
reward: -2.5411, last reward: -0.1041, gradient norm: 2.372: 64%|██████▎ | 398/625 [01:00<00:32, 7.08it/s]
reward: -2.2675, last reward: -0.3109, gradient norm: 1.392: 64%|██████▎ | 398/625 [01:00<00:32, 7.08it/s]
reward: -2.2675, last reward: -0.3109, gradient norm: 1.392: 64%|██████▍ | 399/625 [01:00<00:31, 7.09it/s]
reward: -2.1959, last reward: -0.9976, gradient norm: 204.8: 64%|██████▍ | 399/625 [01:00<00:31, 7.09it/s]
reward: -2.1959, last reward: -0.9976, gradient norm: 204.8: 64%|██████▍ | 400/625 [01:00<00:31, 7.09it/s]
reward: -2.7219, last reward: -2.5467, gradient norm: 75.26: 64%|██████▍ | 400/625 [01:01<00:31, 7.09it/s]
reward: -2.7219, last reward: -2.5467, gradient norm: 75.26: 64%|██████▍ | 401/625 [01:01<00:31, 7.09it/s]
reward: -2.1482, last reward: -0.0749, gradient norm: 5.844: 64%|██████▍ | 401/625 [01:01<00:31, 7.09it/s]
reward: -2.1482, last reward: -0.0749, gradient norm: 5.844: 64%|██████▍ | 402/625 [01:01<00:31, 7.09it/s]
reward: -2.4053, last reward: -0.6417, gradient norm: 59.78: 64%|██████▍ | 402/625 [01:01<00:31, 7.09it/s]
reward: -2.4053, last reward: -0.6417, gradient norm: 59.78: 64%|██████▍ | 403/625 [01:01<00:31, 7.09it/s]
reward: -3.5661, last reward: -3.7499, gradient norm: 47.77: 64%|██████▍ | 403/625 [01:01<00:31, 7.09it/s]
reward: -3.5661, last reward: -3.7499, gradient norm: 47.77: 65%|██████▍ | 404/625 [01:01<00:31, 7.09it/s]
reward: -3.3625, last reward: -4.0363, gradient norm: 144.7: 65%|██████▍ | 404/625 [01:01<00:31, 7.09it/s]
reward: -3.3625, last reward: -4.0363, gradient norm: 144.7: 65%|██████▍ | 405/625 [01:01<00:31, 7.08it/s]
reward: -2.0505, last reward: -0.4692, gradient norm: 4.069: 65%|██████▍ | 405/625 [01:01<00:31, 7.08it/s]
reward: -2.0505, last reward: -0.4692, gradient norm: 4.069: 65%|██████▍ | 406/625 [01:01<00:30, 7.09it/s]
reward: -2.0323, last reward: -0.0413, gradient norm: 1.306: 65%|██████▍ | 406/625 [01:01<00:30, 7.09it/s]
reward: -2.0323, last reward: -0.0413, gradient norm: 1.306: 65%|██████▌ | 407/625 [01:01<00:30, 7.08it/s]
reward: -1.9516, last reward: -0.0189, gradient norm: 7.272: 65%|██████▌ | 407/625 [01:02<00:30, 7.08it/s]
reward: -1.9516, last reward: -0.0189, gradient norm: 7.272: 65%|██████▌ | 408/625 [01:02<00:30, 7.06it/s]
reward: -3.0273, last reward: -2.7877, gradient norm: 28.59: 65%|██████▌ | 408/625 [01:02<00:30, 7.06it/s]
reward: -3.0273, last reward: -2.7877, gradient norm: 28.59: 65%|██████▌ | 409/625 [01:02<00:30, 7.07it/s]
reward: -3.1125, last reward: -3.5742, gradient norm: 35.32: 65%|██████▌ | 409/625 [01:02<00:30, 7.07it/s]
reward: -3.1125, last reward: -3.5742, gradient norm: 35.32: 66%|██████▌ | 410/625 [01:02<00:30, 7.07it/s]
reward: -2.8391, last reward: -4.5701, gradient norm: 54.7: 66%|██████▌ | 410/625 [01:02<00:30, 7.07it/s]
reward: -2.8391, last reward: -4.5701, gradient norm: 54.7: 66%|██████▌ | 411/625 [01:02<00:30, 7.08it/s]
reward: -2.2842, last reward: -0.5706, gradient norm: 16.98: 66%|██████▌ | 411/625 [01:02<00:30, 7.08it/s]
reward: -2.2842, last reward: -0.5706, gradient norm: 16.98: 66%|██████▌ | 412/625 [01:02<00:30, 7.08it/s]
reward: -3.5451, last reward: -5.2434, gradient norm: 313.2: 66%|██████▌ | 412/625 [01:02<00:30, 7.08it/s]
reward: -3.5451, last reward: -5.2434, gradient norm: 313.2: 66%|██████▌ | 413/625 [01:02<00:29, 7.08it/s]
reward: -3.9004, last reward: -2.9116, gradient norm: 19.63: 66%|██████▌ | 413/625 [01:02<00:29, 7.08it/s]
reward: -3.9004, last reward: -2.9116, gradient norm: 19.63: 66%|██████▌ | 414/625 [01:02<00:29, 7.09it/s]
reward: -3.9582, last reward: -4.5818, gradient norm: 24.67: 66%|██████▌ | 414/625 [01:03<00:29, 7.09it/s]
reward: -3.9582, last reward: -4.5818, gradient norm: 24.67: 66%|██████▋ | 415/625 [01:03<00:29, 7.09it/s]
reward: -3.9045, last reward: -2.0780, gradient norm: 13.42: 66%|██████▋ | 415/625 [01:03<00:29, 7.09it/s]
reward: -3.9045, last reward: -2.0780, gradient norm: 13.42: 67%|██████▋ | 416/625 [01:03<00:29, 7.09it/s]
reward: -1.8262, last reward: -0.0263, gradient norm: 1.53: 67%|██████▋ | 416/625 [01:03<00:29, 7.09it/s]
reward: -1.8262, last reward: -0.0263, gradient norm: 1.53: 67%|██████▋ | 417/625 [01:03<00:29, 7.09it/s]
reward: -2.2288, last reward: -0.0085, gradient norm: 1.05: 67%|██████▋ | 417/625 [01:03<00:29, 7.09it/s]
reward: -2.2288, last reward: -0.0085, gradient norm: 1.05: 67%|██████▋ | 418/625 [01:03<00:29, 7.08it/s]
reward: -1.8184, last reward: -0.0002, gradient norm: 0.3576: 67%|██████▋ | 418/625 [01:03<00:29, 7.08it/s]
reward: -1.8184, last reward: -0.0002, gradient norm: 0.3576: 67%|██████▋ | 419/625 [01:03<00:29, 7.08it/s]
reward: -1.9760, last reward: -0.2533, gradient norm: 1.459: 67%|██████▋ | 419/625 [01:03<00:29, 7.08it/s]
reward: -1.9760, last reward: -0.2533, gradient norm: 1.459: 67%|██████▋ | 420/625 [01:03<00:28, 7.09it/s]
reward: -2.2221, last reward: -0.0398, gradient norm: 1.651: 67%|██████▋ | 420/625 [01:03<00:28, 7.09it/s]
reward: -2.2221, last reward: -0.0398, gradient norm: 1.651: 67%|██████▋ | 421/625 [01:03<00:28, 7.09it/s]
reward: -1.7999, last reward: -0.0115, gradient norm: 0.897: 67%|██████▋ | 421/625 [01:03<00:28, 7.09it/s]
reward: -1.7999, last reward: -0.0115, gradient norm: 0.897: 68%|██████▊ | 422/625 [01:03<00:28, 7.10it/s]
reward: -1.9725, last reward: -0.0001, gradient norm: 2.174: 68%|██████▊ | 422/625 [01:04<00:28, 7.10it/s]
reward: -1.9725, last reward: -0.0001, gradient norm: 2.174: 68%|██████▊ | 423/625 [01:04<00:28, 7.10it/s]
reward: -1.7129, last reward: -0.0021, gradient norm: 0.6833: 68%|██████▊ | 423/625 [01:04<00:28, 7.10it/s]
reward: -1.7129, last reward: -0.0021, gradient norm: 0.6833: 68%|██████▊ | 424/625 [01:04<00:28, 7.09it/s]
reward: -2.5677, last reward: -0.2445, gradient norm: 0.513: 68%|██████▊ | 424/625 [01:04<00:28, 7.09it/s]
reward: -2.5677, last reward: -0.2445, gradient norm: 0.513: 68%|██████▊ | 425/625 [01:04<00:28, 7.09it/s]
reward: -2.2359, last reward: -0.0001, gradient norm: 5.534: 68%|██████▊ | 425/625 [01:04<00:28, 7.09it/s]
reward: -2.2359, last reward: -0.0001, gradient norm: 5.534: 68%|██████▊ | 426/625 [01:04<00:28, 7.08it/s]
reward: -2.3329, last reward: -0.0017, gradient norm: 0.4441: 68%|██████▊ | 426/625 [01:04<00:28, 7.08it/s]
reward: -2.3329, last reward: -0.0017, gradient norm: 0.4441: 68%|██████▊ | 427/625 [01:04<00:27, 7.09it/s]
reward: -2.3339, last reward: -0.0069, gradient norm: 0.6721: 68%|██████▊ | 427/625 [01:04<00:27, 7.09it/s]
reward: -2.3339, last reward: -0.0069, gradient norm: 0.6721: 68%|██████▊ | 428/625 [01:04<00:27, 7.09it/s]
reward: -1.9673, last reward: -0.0043, gradient norm: 1.146: 68%|██████▊ | 428/625 [01:04<00:27, 7.09it/s]
reward: -1.9673, last reward: -0.0043, gradient norm: 1.146: 69%|██████▊ | 429/625 [01:04<00:27, 7.08it/s]
reward: -2.1231, last reward: -0.4787, gradient norm: 61.52: 69%|██████▊ | 429/625 [01:05<00:27, 7.08it/s]
reward: -2.1231, last reward: -0.4787, gradient norm: 61.52: 69%|██████▉ | 430/625 [01:05<00:27, 7.07it/s]
reward: -1.9588, last reward: -0.0662, gradient norm: 16.49: 69%|██████▉ | 430/625 [01:05<00:27, 7.07it/s]
reward: -1.9588, last reward: -0.0662, gradient norm: 16.49: 69%|██████▉ | 431/625 [01:05<00:27, 7.08it/s]
reward: -1.8577, last reward: -0.0059, gradient norm: 0.8145: 69%|██████▉ | 431/625 [01:05<00:27, 7.08it/s]
reward: -1.8577, last reward: -0.0059, gradient norm: 0.8145: 69%|██████▉ | 432/625 [01:05<00:27, 7.08it/s]
reward: -2.0602, last reward: -0.0177, gradient norm: 3.439: 69%|██████▉ | 432/625 [01:05<00:27, 7.08it/s]
reward: -2.0602, last reward: -0.0177, gradient norm: 3.439: 69%|██████▉ | 433/625 [01:05<00:27, 7.08it/s]
reward: -2.0378, last reward: -0.0097, gradient norm: 0.4788: 69%|██████▉ | 433/625 [01:05<00:27, 7.08it/s]
reward: -2.0378, last reward: -0.0097, gradient norm: 0.4788: 69%|██████▉ | 434/625 [01:05<00:26, 7.09it/s]
reward: -1.8244, last reward: -0.0033, gradient norm: 4.172: 69%|██████▉ | 434/625 [01:05<00:26, 7.09it/s]
reward: -1.8244, last reward: -0.0033, gradient norm: 4.172: 70%|██████▉ | 435/625 [01:05<00:26, 7.08it/s]
reward: -2.2019, last reward: -0.0058, gradient norm: 0.9534: 70%|██████▉ | 435/625 [01:05<00:26, 7.08it/s]
reward: -2.2019, last reward: -0.0058, gradient norm: 0.9534: 70%|██████▉ | 436/625 [01:05<00:26, 7.08it/s]
reward: -1.8663, last reward: -0.0397, gradient norm: 1.967: 70%|██████▉ | 436/625 [01:06<00:26, 7.08it/s]
reward: -1.8663, last reward: -0.0397, gradient norm: 1.967: 70%|██████▉ | 437/625 [01:06<00:26, 7.09it/s]
reward: -2.4510, last reward: -0.0433, gradient norm: 1.131: 70%|██████▉ | 437/625 [01:06<00:26, 7.09it/s]
reward: -2.4510, last reward: -0.0433, gradient norm: 1.131: 70%|███████ | 438/625 [01:06<00:26, 7.09it/s]
reward: -1.7794, last reward: -0.0326, gradient norm: 10.53: 70%|███████ | 438/625 [01:06<00:26, 7.09it/s]
reward: -1.7794, last reward: -0.0326, gradient norm: 10.53: 70%|███████ | 439/625 [01:06<00:26, 7.09it/s]
reward: -2.5079, last reward: -0.1033, gradient norm: 3.88: 70%|███████ | 439/625 [01:06<00:26, 7.09it/s]
reward: -2.5079, last reward: -0.1033, gradient norm: 3.88: 70%|███████ | 440/625 [01:06<00:26, 7.08it/s]
reward: -2.4987, last reward: -0.1993, gradient norm: 6.482: 70%|███████ | 440/625 [01:06<00:26, 7.08it/s]
reward: -2.4987, last reward: -0.1993, gradient norm: 6.482: 71%|███████ | 441/625 [01:06<00:25, 7.09it/s]
reward: -2.8366, last reward: -0.3230, gradient norm: 7.559: 71%|███████ | 441/625 [01:06<00:25, 7.09it/s]
reward: -2.8366, last reward: -0.3230, gradient norm: 7.559: 71%|███████ | 442/625 [01:06<00:25, 7.10it/s]
reward: -2.7358, last reward: -0.1138, gradient norm: 2.334: 71%|███████ | 442/625 [01:06<00:25, 7.10it/s]
reward: -2.7358, last reward: -0.1138, gradient norm: 2.334: 71%|███████ | 443/625 [01:06<00:25, 7.09it/s]
reward: -2.9119, last reward: -0.5372, gradient norm: 99.36: 71%|███████ | 443/625 [01:07<00:25, 7.09it/s]
reward: -2.9119, last reward: -0.5372, gradient norm: 99.36: 71%|███████ | 444/625 [01:07<00:25, 7.09it/s]
reward: -4.2321, last reward: -2.2797, gradient norm: 195.7: 71%|███████ | 444/625 [01:07<00:25, 7.09it/s]
reward: -4.2321, last reward: -2.2797, gradient norm: 195.7: 71%|███████ | 445/625 [01:07<00:25, 7.09it/s]
reward: -3.4519, last reward: -0.7850, gradient norm: 95.76: 71%|███████ | 445/625 [01:07<00:25, 7.09it/s]
reward: -3.4519, last reward: -0.7850, gradient norm: 95.76: 71%|███████▏ | 446/625 [01:07<00:25, 7.10it/s]
reward: -2.9948, last reward: -0.0784, gradient norm: 1.258: 71%|███████▏ | 446/625 [01:07<00:25, 7.10it/s]
reward: -2.9948, last reward: -0.0784, gradient norm: 1.258: 72%|███████▏ | 447/625 [01:07<00:25, 7.09it/s]
reward: -2.6611, last reward: -0.0394, gradient norm: 1.132: 72%|███████▏ | 447/625 [01:07<00:25, 7.09it/s]
reward: -2.6611, last reward: -0.0394, gradient norm: 1.132: 72%|███████▏ | 448/625 [01:07<00:24, 7.09it/s]
reward: -3.0908, last reward: -0.0552, gradient norm: 2.82: 72%|███████▏ | 448/625 [01:07<00:24, 7.09it/s]
reward: -3.0908, last reward: -0.0552, gradient norm: 2.82: 72%|███████▏ | 449/625 [01:07<00:24, 7.09it/s]
reward: -2.8460, last reward: -0.4330, gradient norm: 6.074: 72%|███████▏ | 449/625 [01:07<00:24, 7.09it/s]
reward: -2.8460, last reward: -0.4330, gradient norm: 6.074: 72%|███████▏ | 450/625 [01:07<00:24, 7.08it/s]
reward: -2.9178, last reward: -0.4706, gradient norm: 14.41: 72%|███████▏ | 450/625 [01:08<00:24, 7.08it/s]
reward: -2.9178, last reward: -0.4706, gradient norm: 14.41: 72%|███████▏ | 451/625 [01:08<00:24, 7.09it/s]
reward: -2.6458, last reward: -0.4004, gradient norm: 10.5: 72%|███████▏ | 451/625 [01:08<00:24, 7.09it/s]
reward: -2.6458, last reward: -0.4004, gradient norm: 10.5: 72%|███████▏ | 452/625 [01:08<00:24, 7.09it/s]
reward: -2.3558, last reward: -0.1263, gradient norm: 5.546: 72%|███████▏ | 452/625 [01:08<00:24, 7.09it/s]
reward: -2.3558, last reward: -0.1263, gradient norm: 5.546: 72%|███████▏ | 453/625 [01:08<00:24, 7.09it/s]
reward: -1.8264, last reward: -0.0158, gradient norm: 0.5048: 72%|███████▏ | 453/625 [01:08<00:24, 7.09it/s]
reward: -1.8264, last reward: -0.0158, gradient norm: 0.5048: 73%|███████▎ | 454/625 [01:08<00:24, 7.09it/s]
reward: -2.3220, last reward: -0.0268, gradient norm: 0.7661: 73%|███████▎ | 454/625 [01:08<00:24, 7.09it/s]
reward: -2.3220, last reward: -0.0268, gradient norm: 0.7661: 73%|███████▎ | 455/625 [01:08<00:24, 7.08it/s]
reward: -2.2009, last reward: -0.0254, gradient norm: 0.8201: 73%|███████▎ | 455/625 [01:08<00:24, 7.08it/s]
reward: -2.2009, last reward: -0.0254, gradient norm: 0.8201: 73%|███████▎ | 456/625 [01:08<00:27, 6.18it/s]
reward: -2.7093, last reward: -0.0448, gradient norm: 0.8821: 73%|███████▎ | 456/625 [01:09<00:27, 6.18it/s]
reward: -2.7093, last reward: -0.0448, gradient norm: 0.8821: 73%|███████▎ | 457/625 [01:09<00:26, 6.42it/s]
reward: -2.5583, last reward: -0.0196, gradient norm: 2.485: 73%|███████▎ | 457/625 [01:09<00:26, 6.42it/s]
reward: -2.5583, last reward: -0.0196, gradient norm: 2.485: 73%|███████▎ | 458/625 [01:09<00:25, 6.61it/s]
reward: -2.8881, last reward: -0.5340, gradient norm: 11.58: 73%|███████▎ | 458/625 [01:09<00:25, 6.61it/s]
reward: -2.8881, last reward: -0.5340, gradient norm: 11.58: 73%|███████▎ | 459/625 [01:09<00:24, 6.74it/s]
reward: -1.9540, last reward: -0.4836, gradient norm: 22.01: 73%|███████▎ | 459/625 [01:09<00:24, 6.74it/s]
reward: -1.9540, last reward: -0.4836, gradient norm: 22.01: 74%|███████▎ | 460/625 [01:09<00:24, 6.85it/s]
reward: -2.3293, last reward: -2.6132, gradient norm: 59.19: 74%|███████▎ | 460/625 [01:09<00:24, 6.85it/s]
reward: -2.3293, last reward: -2.6132, gradient norm: 59.19: 74%|███████▍ | 461/625 [01:09<00:23, 6.92it/s]
reward: -1.8136, last reward: -1.1879, gradient norm: 85.34: 74%|███████▍ | 461/625 [01:09<00:23, 6.92it/s]
reward: -1.8136, last reward: -1.1879, gradient norm: 85.34: 74%|███████▍ | 462/625 [01:09<00:23, 6.98it/s]
reward: -1.8134, last reward: -0.0004, gradient norm: 0.6862: 74%|███████▍ | 462/625 [01:09<00:23, 6.98it/s]
reward: -1.8134, last reward: -0.0004, gradient norm: 0.6862: 74%|███████▍ | 463/625 [01:09<00:23, 7.00it/s]
reward: -1.8770, last reward: -0.0243, gradient norm: 1.179: 74%|███████▍ | 463/625 [01:09<00:23, 7.00it/s]
reward: -1.8770, last reward: -0.0243, gradient norm: 1.179: 74%|███████▍ | 464/625 [01:09<00:22, 7.03it/s]
reward: -2.1961, last reward: -0.0433, gradient norm: 3.059: 74%|███████▍ | 464/625 [01:10<00:22, 7.03it/s]
reward: -2.1961, last reward: -0.0433, gradient norm: 3.059: 74%|███████▍ | 465/625 [01:10<00:22, 7.05it/s]
reward: -1.9947, last reward: -0.0445, gradient norm: 2.666: 74%|███████▍ | 465/625 [01:10<00:22, 7.05it/s]
reward: -1.9947, last reward: -0.0445, gradient norm: 2.666: 75%|███████▍ | 466/625 [01:10<00:22, 7.06it/s]
reward: -2.2301, last reward: -0.0274, gradient norm: 1.292: 75%|███████▍ | 466/625 [01:10<00:22, 7.06it/s]
reward: -2.2301, last reward: -0.0274, gradient norm: 1.292: 75%|███████▍ | 467/625 [01:10<00:22, 7.07it/s]
reward: -1.9100, last reward: -0.0079, gradient norm: 0.7704: 75%|███████▍ | 467/625 [01:10<00:22, 7.07it/s]
reward: -1.9100, last reward: -0.0079, gradient norm: 0.7704: 75%|███████▍ | 468/625 [01:10<00:22, 7.08it/s]
reward: -1.9270, last reward: -0.0237, gradient norm: 1.117: 75%|███████▍ | 468/625 [01:10<00:22, 7.08it/s]
reward: -1.9270, last reward: -0.0237, gradient norm: 1.117: 75%|███████▌ | 469/625 [01:10<00:22, 7.08it/s]
reward: -2.1629, last reward: -0.0506, gradient norm: 1.785: 75%|███████▌ | 469/625 [01:10<00:22, 7.08it/s]
reward: -2.1629, last reward: -0.0506, gradient norm: 1.785: 75%|███████▌ | 470/625 [01:10<00:21, 7.07it/s]
reward: -2.2214, last reward: -0.1501, gradient norm: 8.97: 75%|███████▌ | 470/625 [01:10<00:21, 7.07it/s]
reward: -2.2214, last reward: -0.1501, gradient norm: 8.97: 75%|███████▌ | 471/625 [01:10<00:21, 7.07it/s]
reward: -2.0163, last reward: -0.0306, gradient norm: 2.243: 75%|███████▌ | 471/625 [01:11<00:21, 7.07it/s]
reward: -2.0163, last reward: -0.0306, gradient norm: 2.243: 76%|███████▌ | 472/625 [01:11<00:21, 7.07it/s]
reward: -2.5828, last reward: -0.0022, gradient norm: 7.324: 76%|███████▌ | 472/625 [01:11<00:21, 7.07it/s]
reward: -2.5828, last reward: -0.0022, gradient norm: 7.324: 76%|███████▌ | 473/625 [01:11<00:21, 7.06it/s]
reward: -1.9628, last reward: -0.0024, gradient norm: 0.486: 76%|███████▌ | 473/625 [01:11<00:21, 7.06it/s]
reward: -1.9628, last reward: -0.0024, gradient norm: 0.486: 76%|███████▌ | 474/625 [01:11<00:21, 7.06it/s]
reward: -1.8635, last reward: -0.0044, gradient norm: 0.5231: 76%|███████▌ | 474/625 [01:11<00:21, 7.06it/s]
reward: -1.8635, last reward: -0.0044, gradient norm: 0.5231: 76%|███████▌ | 475/625 [01:11<00:21, 7.07it/s]
reward: -1.8244, last reward: -0.0058, gradient norm: 0.6448: 76%|███████▌ | 475/625 [01:11<00:21, 7.07it/s]
reward: -1.8244, last reward: -0.0058, gradient norm: 0.6448: 76%|███████▌ | 476/625 [01:11<00:21, 7.06it/s]
reward: -2.2843, last reward: -0.0024, gradient norm: 0.6923: 76%|███████▌ | 476/625 [01:11<00:21, 7.06it/s]
reward: -2.2843, last reward: -0.0024, gradient norm: 0.6923: 76%|███████▋ | 477/625 [01:11<00:20, 7.07it/s]
reward: -1.8227, last reward: -0.0030, gradient norm: 0.7466: 76%|███████▋ | 477/625 [01:11<00:20, 7.07it/s]
reward: -1.8227, last reward: -0.0030, gradient norm: 0.7466: 76%|███████▋ | 478/625 [01:11<00:20, 7.07it/s]
reward: -1.9439, last reward: -0.0393, gradient norm: 3.162: 76%|███████▋ | 478/625 [01:12<00:20, 7.07it/s]
reward: -1.9439, last reward: -0.0393, gradient norm: 3.162: 77%|███████▋ | 479/625 [01:12<00:20, 7.08it/s]
reward: -1.9847, last reward: -0.0337, gradient norm: 1.777: 77%|███████▋ | 479/625 [01:12<00:20, 7.08it/s]
reward: -1.9847, last reward: -0.0337, gradient norm: 1.777: 77%|███████▋ | 480/625 [01:12<00:20, 7.07it/s]
reward: -2.2742, last reward: -0.0036, gradient norm: 1.28: 77%|███████▋ | 480/625 [01:12<00:20, 7.07it/s]
reward: -2.2742, last reward: -0.0036, gradient norm: 1.28: 77%|███████▋ | 481/625 [01:12<00:20, 7.07it/s]
reward: -1.9027, last reward: -0.0015, gradient norm: 0.344: 77%|███████▋ | 481/625 [01:12<00:20, 7.07it/s]
reward: -1.9027, last reward: -0.0015, gradient norm: 0.344: 77%|███████▋ | 482/625 [01:12<00:20, 7.08it/s]
reward: -1.9219, last reward: -0.0064, gradient norm: 2.262: 77%|███████▋ | 482/625 [01:12<00:20, 7.08it/s]
reward: -1.9219, last reward: -0.0064, gradient norm: 2.262: 77%|███████▋ | 483/625 [01:12<00:20, 7.08it/s]
reward: -1.6860, last reward: -0.0251, gradient norm: 1.246: 77%|███████▋ | 483/625 [01:12<00:20, 7.08it/s]
reward: -1.6860, last reward: -0.0251, gradient norm: 1.246: 77%|███████▋ | 484/625 [01:12<00:19, 7.07it/s]
reward: -1.6129, last reward: -0.0278, gradient norm: 1.274: 77%|███████▋ | 484/625 [01:12<00:19, 7.07it/s]
reward: -1.6129, last reward: -0.0278, gradient norm: 1.274: 78%|███████▊ | 485/625 [01:12<00:19, 7.08it/s]
reward: -2.1645, last reward: -0.0158, gradient norm: 0.8033: 78%|███████▊ | 485/625 [01:13<00:19, 7.08it/s]
reward: -2.1645, last reward: -0.0158, gradient norm: 0.8033: 78%|███████▊ | 486/625 [01:13<00:19, 7.09it/s]
reward: -2.1058, last reward: -0.0021, gradient norm: 0.3832: 78%|███████▊ | 486/625 [01:13<00:19, 7.09it/s]
reward: -2.1058, last reward: -0.0021, gradient norm: 0.3832: 78%|███████▊ | 487/625 [01:13<00:19, 7.09it/s]
reward: -2.1000, last reward: -0.0047, gradient norm: 0.2269: 78%|███████▊ | 487/625 [01:13<00:19, 7.09it/s]
reward: -2.1000, last reward: -0.0047, gradient norm: 0.2269: 78%|███████▊ | 488/625 [01:13<00:19, 7.09it/s]
reward: -2.2962, last reward: -0.0514, gradient norm: 5.187: 78%|███████▊ | 488/625 [01:13<00:19, 7.09it/s]
reward: -2.2962, last reward: -0.0514, gradient norm: 5.187: 78%|███████▊ | 489/625 [01:13<00:19, 7.10it/s]
reward: -2.0926, last reward: -0.0346, gradient norm: 0.9889: 78%|███████▊ | 489/625 [01:13<00:19, 7.10it/s]
reward: -2.0926, last reward: -0.0346, gradient norm: 0.9889: 78%|███████▊ | 490/625 [01:13<00:19, 7.10it/s]
reward: -2.2846, last reward: -0.0552, gradient norm: 1.63: 78%|███████▊ | 490/625 [01:13<00:19, 7.10it/s]
reward: -2.2846, last reward: -0.0552, gradient norm: 1.63: 79%|███████▊ | 491/625 [01:13<00:18, 7.08it/s]
reward: -2.2913, last reward: -0.0026, gradient norm: 0.4502: 79%|███████▊ | 491/625 [01:13<00:18, 7.08it/s]
reward: -2.2913, last reward: -0.0026, gradient norm: 0.4502: 79%|███████▊ | 492/625 [01:13<00:18, 7.08it/s]
reward: -2.4193, last reward: -0.0321, gradient norm: 0.6368: 79%|███████▊ | 492/625 [01:14<00:18, 7.08it/s]
reward: -2.4193, last reward: -0.0321, gradient norm: 0.6368: 79%|███████▉ | 493/625 [01:14<00:18, 7.08it/s]
reward: -2.5277, last reward: -0.0298, gradient norm: 0.5274: 79%|███████▉ | 493/625 [01:14<00:18, 7.08it/s]
reward: -2.5277, last reward: -0.0298, gradient norm: 0.5274: 79%|███████▉ | 494/625 [01:14<00:18, 7.09it/s]
reward: -2.9512, last reward: -0.0883, gradient norm: 11.35: 79%|███████▉ | 494/625 [01:14<00:18, 7.09it/s]
reward: -2.9512, last reward: -0.0883, gradient norm: 11.35: 79%|███████▉ | 495/625 [01:14<00:18, 7.08it/s]
reward: -2.4922, last reward: -0.0155, gradient norm: 1.235: 79%|███████▉ | 495/625 [01:14<00:18, 7.08it/s]
reward: -2.4922, last reward: -0.0155, gradient norm: 1.235: 79%|███████▉ | 496/625 [01:14<00:18, 7.09it/s]
reward: -2.0426, last reward: -0.1488, gradient norm: 1.702: 79%|███████▉ | 496/625 [01:14<00:18, 7.09it/s]
reward: -2.0426, last reward: -0.1488, gradient norm: 1.702: 80%|███████▉ | 497/625 [01:14<00:18, 7.09it/s]
reward: -2.3193, last reward: -0.0128, gradient norm: 0.3806: 80%|███████▉ | 497/625 [01:14<00:18, 7.09it/s]
reward: -2.3193, last reward: -0.0128, gradient norm: 0.3806: 80%|███████▉ | 498/625 [01:14<00:17, 7.09it/s]
reward: -3.0466, last reward: -0.0251, gradient norm: 0.4944: 80%|███████▉ | 498/625 [01:14<00:17, 7.09it/s]
reward: -3.0466, last reward: -0.0251, gradient norm: 0.4944: 80%|███████▉ | 499/625 [01:14<00:17, 7.09it/s]
reward: -2.1064, last reward: -0.0012, gradient norm: 0.5777: 80%|███████▉ | 499/625 [01:15<00:17, 7.09it/s]
reward: -2.1064, last reward: -0.0012, gradient norm: 0.5777: 80%|████████ | 500/625 [01:15<00:17, 7.10it/s]
reward: -1.6610, last reward: -0.0056, gradient norm: 0.6493: 80%|████████ | 500/625 [01:15<00:17, 7.10it/s]
reward: -1.6610, last reward: -0.0056, gradient norm: 0.6493: 80%|████████ | 501/625 [01:15<00:17, 7.09it/s]
reward: -2.2140, last reward: -0.0071, gradient norm: 0.7689: 80%|████████ | 501/625 [01:15<00:17, 7.09it/s]
reward: -2.2140, last reward: -0.0071, gradient norm: 0.7689: 80%|████████ | 502/625 [01:15<00:17, 7.10it/s]
reward: -2.4047, last reward: -0.0048, gradient norm: 0.5415: 80%|████████ | 502/625 [01:15<00:17, 7.10it/s]
reward: -2.4047, last reward: -0.0048, gradient norm: 0.5415: 80%|████████ | 503/625 [01:15<00:17, 7.10it/s]
reward: -2.1769, last reward: -0.0068, gradient norm: 0.4102: 80%|████████ | 503/625 [01:15<00:17, 7.10it/s]
reward: -2.1769, last reward: -0.0068, gradient norm: 0.4102: 81%|████████ | 504/625 [01:15<00:17, 7.10it/s]
reward: -2.2875, last reward: -0.0001, gradient norm: 0.2044: 81%|████████ | 504/625 [01:15<00:17, 7.10it/s]
reward: -2.2875, last reward: -0.0001, gradient norm: 0.2044: 81%|████████ | 505/625 [01:15<00:16, 7.09it/s]
reward: -1.7574, last reward: -0.0004, gradient norm: 0.1334: 81%|████████ | 505/625 [01:15<00:16, 7.09it/s]
reward: -1.7574, last reward: -0.0004, gradient norm: 0.1334: 81%|████████ | 506/625 [01:15<00:16, 7.09it/s]
reward: -2.0412, last reward: -0.0025, gradient norm: 0.516: 81%|████████ | 506/625 [01:16<00:16, 7.09it/s]
reward: -2.0412, last reward: -0.0025, gradient norm: 0.516: 81%|████████ | 507/625 [01:16<00:16, 7.09it/s]
reward: -2.0418, last reward: -0.0010, gradient norm: 0.956: 81%|████████ | 507/625 [01:16<00:16, 7.09it/s]
reward: -2.0418, last reward: -0.0010, gradient norm: 0.956: 81%|████████▏ | 508/625 [01:16<00:16, 7.09it/s]
reward: -2.0470, last reward: -0.3908, gradient norm: 10.8: 81%|████████▏ | 508/625 [01:16<00:16, 7.09it/s]
reward: -2.0470, last reward: -0.3908, gradient norm: 10.8: 81%|████████▏ | 509/625 [01:16<00:16, 7.10it/s]
reward: -2.0211, last reward: -0.0003, gradient norm: 0.2692: 81%|████████▏ | 509/625 [01:16<00:16, 7.10it/s]
reward: -2.0211, last reward: -0.0003, gradient norm: 0.2692: 82%|████████▏ | 510/625 [01:16<00:16, 7.09it/s]
reward: -1.8167, last reward: -0.0015, gradient norm: 0.4211: 82%|████████▏ | 510/625 [01:16<00:16, 7.09it/s]
reward: -1.8167, last reward: -0.0015, gradient norm: 0.4211: 82%|████████▏ | 511/625 [01:16<00:16, 7.09it/s]
reward: -2.2510, last reward: -0.0017, gradient norm: 0.5205: 82%|████████▏ | 511/625 [01:16<00:16, 7.09it/s]
reward: -2.2510, last reward: -0.0017, gradient norm: 0.5205: 82%|████████▏ | 512/625 [01:16<00:15, 7.09it/s]
reward: -2.1434, last reward: -0.0008, gradient norm: 0.4398: 82%|████████▏ | 512/625 [01:16<00:15, 7.09it/s]
reward: -2.1434, last reward: -0.0008, gradient norm: 0.4398: 82%|████████▏ | 513/625 [01:16<00:15, 7.09it/s]
reward: -2.3026, last reward: -0.0061, gradient norm: 0.8165: 82%|████████▏ | 513/625 [01:17<00:15, 7.09it/s]
reward: -2.3026, last reward: -0.0061, gradient norm: 0.8165: 82%|████████▏ | 514/625 [01:17<00:15, 7.09it/s]
reward: -2.0058, last reward: -0.0110, gradient norm: 0.904: 82%|████████▏ | 514/625 [01:17<00:15, 7.09it/s]
reward: -2.0058, last reward: -0.0110, gradient norm: 0.904: 82%|████████▏ | 515/625 [01:17<00:15, 7.09it/s]
reward: -2.2338, last reward: -0.0042, gradient norm: 1.126: 82%|████████▏ | 515/625 [01:17<00:15, 7.09it/s]
reward: -2.2338, last reward: -0.0042, gradient norm: 1.126: 83%|████████▎ | 516/625 [01:17<00:15, 7.09it/s]
reward: -2.3401, last reward: -0.0033, gradient norm: 0.425: 83%|████████▎ | 516/625 [01:17<00:15, 7.09it/s]
reward: -2.3401, last reward: -0.0033, gradient norm: 0.425: 83%|████████▎ | 517/625 [01:17<00:15, 7.09it/s]
reward: -2.0662, last reward: -0.0265, gradient norm: 1.083: 83%|████████▎ | 517/625 [01:17<00:15, 7.09it/s]
reward: -2.0662, last reward: -0.0265, gradient norm: 1.083: 83%|████████▎ | 518/625 [01:17<00:15, 7.09it/s]
reward: -2.9786, last reward: -1.4360, gradient norm: 14.61: 83%|████████▎ | 518/625 [01:17<00:15, 7.09it/s]
reward: -2.9786, last reward: -1.4360, gradient norm: 14.61: 83%|████████▎ | 519/625 [01:17<00:14, 7.09it/s]
reward: -2.8943, last reward: -2.3368, gradient norm: 29.02: 83%|████████▎ | 519/625 [01:17<00:14, 7.09it/s]
reward: -2.8943, last reward: -2.3368, gradient norm: 29.02: 83%|████████▎ | 520/625 [01:17<00:14, 7.09it/s]
reward: -3.1110, last reward: -1.0718, gradient norm: 12.43: 83%|████████▎ | 520/625 [01:18<00:14, 7.09it/s]
reward: -3.1110, last reward: -1.0718, gradient norm: 12.43: 83%|████████▎ | 521/625 [01:18<00:14, 7.09it/s]
reward: -2.4938, last reward: -1.9297, gradient norm: 35.92: 83%|████████▎ | 521/625 [01:18<00:14, 7.09it/s]
reward: -2.4938, last reward: -1.9297, gradient norm: 35.92: 84%|████████▎ | 522/625 [01:18<00:14, 7.09it/s]
reward: -2.4448, last reward: -0.4093, gradient norm: 708.1: 84%|████████▎ | 522/625 [01:18<00:14, 7.09it/s]
reward: -2.4448, last reward: -0.4093, gradient norm: 708.1: 84%|████████▎ | 523/625 [01:18<00:14, 7.08it/s]
reward: -2.6853, last reward: -0.2564, gradient norm: 23.43: 84%|████████▎ | 523/625 [01:18<00:14, 7.08it/s]
reward: -2.6853, last reward: -0.2564, gradient norm: 23.43: 84%|████████▍ | 524/625 [01:18<00:14, 7.09it/s]
reward: -2.3315, last reward: -0.0395, gradient norm: 0.9026: 84%|████████▍ | 524/625 [01:18<00:14, 7.09it/s]
reward: -2.3315, last reward: -0.0395, gradient norm: 0.9026: 84%|████████▍ | 525/625 [01:18<00:14, 7.10it/s]
reward: -2.1826, last reward: -0.0164, gradient norm: 0.9545: 84%|████████▍ | 525/625 [01:18<00:14, 7.10it/s]
reward: -2.1826, last reward: -0.0164, gradient norm: 0.9545: 84%|████████▍ | 526/625 [01:18<00:13, 7.10it/s]
reward: -1.6197, last reward: -0.0035, gradient norm: 2.884: 84%|████████▍ | 526/625 [01:18<00:13, 7.10it/s]
reward: -1.6197, last reward: -0.0035, gradient norm: 2.884: 84%|████████▍ | 527/625 [01:18<00:13, 7.09it/s]
reward: -2.1676, last reward: -0.0008, gradient norm: 7.64: 84%|████████▍ | 527/625 [01:19<00:13, 7.09it/s]
reward: -2.1676, last reward: -0.0008, gradient norm: 7.64: 84%|████████▍ | 528/625 [01:19<00:13, 7.10it/s]
reward: -1.8170, last reward: -0.0137, gradient norm: 7.699: 84%|████████▍ | 528/625 [01:19<00:13, 7.10it/s]
reward: -1.8170, last reward: -0.0137, gradient norm: 7.699: 85%|████████▍ | 529/625 [01:19<00:13, 7.09it/s]
reward: -2.3319, last reward: -2.0678, gradient norm: 44.93: 85%|████████▍ | 529/625 [01:19<00:13, 7.09it/s]
reward: -2.3319, last reward: -2.0678, gradient norm: 44.93: 85%|████████▍ | 530/625 [01:19<00:13, 7.10it/s]
reward: -2.9299, last reward: -1.4730, gradient norm: 20.53: 85%|████████▍ | 530/625 [01:19<00:13, 7.10it/s]
reward: -2.9299, last reward: -1.4730, gradient norm: 20.53: 85%|████████▍ | 531/625 [01:19<00:13, 7.11it/s]
reward: -2.5351, last reward: -1.9075, gradient norm: 38.91: 85%|████████▍ | 531/625 [01:19<00:13, 7.11it/s]
reward: -2.5351, last reward: -1.9075, gradient norm: 38.91: 85%|████████▌ | 532/625 [01:19<00:13, 7.10it/s]
reward: -2.0451, last reward: -0.0784, gradient norm: 4.204: 85%|████████▌ | 532/625 [01:19<00:13, 7.10it/s]
reward: -2.0451, last reward: -0.0784, gradient norm: 4.204: 85%|████████▌ | 533/625 [01:19<00:12, 7.09it/s]
reward: -1.6476, last reward: -0.0227, gradient norm: 1.616: 85%|████████▌ | 533/625 [01:19<00:12, 7.09it/s]
reward: -1.6476, last reward: -0.0227, gradient norm: 1.616: 85%|████████▌ | 534/625 [01:19<00:12, 7.08it/s]
reward: -2.0873, last reward: -0.0013, gradient norm: 0.3246: 85%|████████▌ | 534/625 [01:20<00:12, 7.08it/s]
reward: -2.0873, last reward: -0.0013, gradient norm: 0.3246: 86%|████████▌ | 535/625 [01:20<00:12, 7.08it/s]
reward: -1.7668, last reward: -0.0025, gradient norm: 0.3961: 86%|████████▌ | 535/625 [01:20<00:12, 7.08it/s]
reward: -1.7668, last reward: -0.0025, gradient norm: 0.3961: 86%|████████▌ | 536/625 [01:20<00:12, 7.09it/s]
reward: -2.0706, last reward: -0.0100, gradient norm: 0.6521: 86%|████████▌ | 536/625 [01:20<00:12, 7.09it/s]
reward: -2.0706, last reward: -0.0100, gradient norm: 0.6521: 86%|████████▌ | 537/625 [01:20<00:12, 7.08it/s]
reward: -2.1701, last reward: -0.0116, gradient norm: 0.7625: 86%|████████▌ | 537/625 [01:20<00:12, 7.08it/s]
reward: -2.1701, last reward: -0.0116, gradient norm: 0.7625: 86%|████████▌ | 538/625 [01:20<00:12, 7.08it/s]
reward: -2.4353, last reward: -0.0162, gradient norm: 1.221: 86%|████████▌ | 538/625 [01:20<00:12, 7.08it/s]
reward: -2.4353, last reward: -0.0162, gradient norm: 1.221: 86%|████████▌ | 539/625 [01:20<00:12, 7.08it/s]
reward: -1.9006, last reward: -0.0013, gradient norm: 0.7598: 86%|████████▌ | 539/625 [01:20<00:12, 7.08it/s]
reward: -1.9006, last reward: -0.0013, gradient norm: 0.7598: 86%|████████▋ | 540/625 [01:20<00:11, 7.09it/s]
reward: -1.7995, last reward: -0.0027, gradient norm: 0.2195: 86%|████████▋ | 540/625 [01:20<00:11, 7.09it/s]
reward: -1.7995, last reward: -0.0027, gradient norm: 0.2195: 87%|████████▋ | 541/625 [01:20<00:11, 7.08it/s]
reward: -2.2206, last reward: -0.0132, gradient norm: 1.025: 87%|████████▋ | 541/625 [01:20<00:11, 7.08it/s]
reward: -2.2206, last reward: -0.0132, gradient norm: 1.025: 87%|████████▋ | 542/625 [01:20<00:11, 7.09it/s]
reward: -2.0971, last reward: -0.0105, gradient norm: 0.8466: 87%|████████▋ | 542/625 [01:21<00:11, 7.09it/s]
reward: -2.0971, last reward: -0.0105, gradient norm: 0.8466: 87%|████████▋ | 543/625 [01:21<00:11, 7.09it/s]
reward: -1.9460, last reward: -0.0016, gradient norm: 0.2598: 87%|████████▋ | 543/625 [01:21<00:11, 7.09it/s]
reward: -1.9460, last reward: -0.0016, gradient norm: 0.2598: 87%|████████▋ | 544/625 [01:21<00:11, 7.09it/s]
reward: -1.8921, last reward: -0.0003, gradient norm: 0.3392: 87%|████████▋ | 544/625 [01:21<00:11, 7.09it/s]
reward: -1.8921, last reward: -0.0003, gradient norm: 0.3392: 87%|████████▋ | 545/625 [01:21<00:11, 7.09it/s]
reward: -2.3196, last reward: -0.0035, gradient norm: 0.6115: 87%|████████▋ | 545/625 [01:21<00:11, 7.09it/s]
reward: -2.3196, last reward: -0.0035, gradient norm: 0.6115: 87%|████████▋ | 546/625 [01:21<00:11, 7.09it/s]
reward: -1.9339, last reward: -0.0053, gradient norm: 0.5191: 87%|████████▋ | 546/625 [01:21<00:11, 7.09it/s]
reward: -1.9339, last reward: -0.0053, gradient norm: 0.5191: 88%|████████▊ | 547/625 [01:21<00:10, 7.10it/s]
reward: -2.0246, last reward: -0.0078, gradient norm: 0.8583: 88%|████████▊ | 547/625 [01:21<00:10, 7.10it/s]
reward: -2.0246, last reward: -0.0078, gradient norm: 0.8583: 88%|████████▊ | 548/625 [01:21<00:10, 7.09it/s]
reward: -2.2817, last reward: -0.0047, gradient norm: 0.7605: 88%|████████▊ | 548/625 [01:21<00:10, 7.09it/s]
reward: -2.2817, last reward: -0.0047, gradient norm: 0.7605: 88%|████████▊ | 549/625 [01:21<00:10, 7.10it/s]
reward: -2.2796, last reward: -0.0016, gradient norm: 0.6417: 88%|████████▊ | 549/625 [01:22<00:10, 7.10it/s]
reward: -2.2796, last reward: -0.0016, gradient norm: 0.6417: 88%|████████▊ | 550/625 [01:22<00:10, 7.09it/s]
reward: -1.3375, last reward: -0.0012, gradient norm: 0.1344: 88%|████████▊ | 550/625 [01:22<00:10, 7.09it/s]
reward: -1.3375, last reward: -0.0012, gradient norm: 0.1344: 88%|████████▊ | 551/625 [01:22<00:10, 7.10it/s]
reward: -1.6716, last reward: -0.0098, gradient norm: 0.4855: 88%|████████▊ | 551/625 [01:22<00:10, 7.10it/s]
reward: -1.6716, last reward: -0.0098, gradient norm: 0.4855: 88%|████████▊ | 552/625 [01:22<00:10, 7.10it/s]
reward: -2.2987, last reward: -0.0942, gradient norm: 13.39: 88%|████████▊ | 552/625 [01:22<00:10, 7.10it/s]
reward: -2.2987, last reward: -0.0942, gradient norm: 13.39: 88%|████████▊ | 553/625 [01:22<00:10, 7.09it/s]
reward: -2.2504, last reward: -0.0342, gradient norm: 1.785: 88%|████████▊ | 553/625 [01:22<00:10, 7.09it/s]
reward: -2.2504, last reward: -0.0342, gradient norm: 1.785: 89%|████████▊ | 554/625 [01:22<00:10, 7.08it/s]
reward: -2.6703, last reward: -0.7093, gradient norm: 21.08: 89%|████████▊ | 554/625 [01:22<00:10, 7.08it/s]
reward: -2.6703, last reward: -0.7093, gradient norm: 21.08: 89%|████████▉ | 555/625 [01:22<00:09, 7.08it/s]
reward: -2.4718, last reward: -0.5308, gradient norm: 9.947: 89%|████████▉ | 555/625 [01:22<00:09, 7.08it/s]
reward: -2.4718, last reward: -0.5308, gradient norm: 9.947: 89%|████████▉ | 556/625 [01:22<00:09, 7.09it/s]
reward: -2.7325, last reward: -0.1904, gradient norm: 1.001: 89%|████████▉ | 556/625 [01:23<00:09, 7.09it/s]
reward: -2.7325, last reward: -0.1904, gradient norm: 1.001: 89%|████████▉ | 557/625 [01:23<00:09, 7.09it/s]
reward: -2.2584, last reward: -0.3395, gradient norm: 8.824: 89%|████████▉ | 557/625 [01:23<00:09, 7.09it/s]
reward: -2.2584, last reward: -0.3395, gradient norm: 8.824: 89%|████████▉ | 558/625 [01:23<00:09, 7.09it/s]
reward: -2.2084, last reward: -0.0047, gradient norm: 0.4281: 89%|████████▉ | 558/625 [01:23<00:09, 7.09it/s]
reward: -2.2084, last reward: -0.0047, gradient norm: 0.4281: 89%|████████▉ | 559/625 [01:23<00:10, 6.22it/s]
reward: -2.1734, last reward: -0.0005, gradient norm: 0.1209: 89%|████████▉ | 559/625 [01:23<00:10, 6.22it/s]
reward: -2.1734, last reward: -0.0005, gradient norm: 0.1209: 90%|████████▉ | 560/625 [01:23<00:10, 6.46it/s]
reward: -2.1244, last reward: -0.0062, gradient norm: 2.972: 90%|████████▉ | 560/625 [01:23<00:10, 6.46it/s]
reward: -2.1244, last reward: -0.0062, gradient norm: 2.972: 90%|████████▉ | 561/625 [01:23<00:09, 6.63it/s]
reward: -1.7850, last reward: -0.0441, gradient norm: 1.266: 90%|████████▉ | 561/625 [01:23<00:09, 6.63it/s]
reward: -1.7850, last reward: -0.0441, gradient norm: 1.266: 90%|████████▉ | 562/625 [01:23<00:09, 6.76it/s]
reward: -1.9144, last reward: -0.0190, gradient norm: 0.5449: 90%|████████▉ | 562/625 [01:24<00:09, 6.76it/s]
reward: -1.9144, last reward: -0.0190, gradient norm: 0.5449: 90%|█████████ | 563/625 [01:24<00:09, 6.85it/s]
reward: -2.1571, last reward: -0.0323, gradient norm: 0.8162: 90%|█████████ | 563/625 [01:24<00:09, 6.85it/s]
reward: -2.1571, last reward: -0.0323, gradient norm: 0.8162: 90%|█████████ | 564/625 [01:24<00:08, 6.91it/s]
reward: -2.4331, last reward: -0.0174, gradient norm: 0.9637: 90%|█████████ | 564/625 [01:24<00:08, 6.91it/s]
reward: -2.4331, last reward: -0.0174, gradient norm: 0.9637: 90%|█████████ | 565/625 [01:24<00:08, 6.97it/s]
reward: -2.7594, last reward: -0.0653, gradient norm: 0.4908: 90%|█████████ | 565/625 [01:24<00:08, 6.97it/s]
reward: -2.7594, last reward: -0.0653, gradient norm: 0.4908: 91%|█████████ | 566/625 [01:24<00:08, 7.00it/s]
reward: -2.3948, last reward: -0.0177, gradient norm: 0.5271: 91%|█████████ | 566/625 [01:24<00:08, 7.00it/s]
reward: -2.3948, last reward: -0.0177, gradient norm: 0.5271: 91%|█████████ | 567/625 [01:24<00:08, 7.02it/s]
reward: -3.9996, last reward: -3.0130, gradient norm: 102.3: 91%|█████████ | 567/625 [01:24<00:08, 7.02it/s]
reward: -3.9996, last reward: -3.0130, gradient norm: 102.3: 91%|█████████ | 568/625 [01:24<00:08, 7.03it/s]
reward: -4.2287, last reward: -3.5724, gradient norm: 81.62: 91%|█████████ | 568/625 [01:24<00:08, 7.03it/s]
reward: -4.2287, last reward: -3.5724, gradient norm: 81.62: 91%|█████████ | 569/625 [01:24<00:07, 7.04it/s]
reward: -2.6496, last reward: -0.8077, gradient norm: 6.047: 91%|█████████ | 569/625 [01:25<00:07, 7.04it/s]
reward: -2.6496, last reward: -0.8077, gradient norm: 6.047: 91%|█████████ | 570/625 [01:25<00:07, 7.06it/s]
reward: -2.3495, last reward: -0.5179, gradient norm: 9.158: 91%|█████████ | 570/625 [01:25<00:07, 7.06it/s]
reward: -2.3495, last reward: -0.5179, gradient norm: 9.158: 91%|█████████▏| 571/625 [01:25<00:07, 7.07it/s]
reward: -2.7529, last reward: -2.2410, gradient norm: 34.28: 91%|█████████▏| 571/625 [01:25<00:07, 7.07it/s]
reward: -2.7529, last reward: -2.2410, gradient norm: 34.28: 92%|█████████▏| 572/625 [01:25<00:07, 7.07it/s]
reward: -3.1140, last reward: -1.6285, gradient norm: 28.53: 92%|█████████▏| 572/625 [01:25<00:07, 7.07it/s]
reward: -3.1140, last reward: -1.6285, gradient norm: 28.53: 92%|█████████▏| 573/625 [01:25<00:07, 7.07it/s]
reward: -1.8435, last reward: -0.0645, gradient norm: 7.86: 92%|█████████▏| 573/625 [01:25<00:07, 7.07it/s]
reward: -1.8435, last reward: -0.0645, gradient norm: 7.86: 92%|█████████▏| 574/625 [01:25<00:07, 7.08it/s]
reward: -2.7749, last reward: -0.2117, gradient norm: 2.568: 92%|█████████▏| 574/625 [01:25<00:07, 7.08it/s]
reward: -2.7749, last reward: -0.2117, gradient norm: 2.568: 92%|█████████▏| 575/625 [01:25<00:07, 7.09it/s]
reward: -3.0808, last reward: -0.0391, gradient norm: 1.567: 92%|█████████▏| 575/625 [01:25<00:07, 7.09it/s]
reward: -3.0808, last reward: -0.0391, gradient norm: 1.567: 92%|█████████▏| 576/625 [01:25<00:06, 7.09it/s]
reward: -2.4133, last reward: -0.2289, gradient norm: 0.355: 92%|█████████▏| 576/625 [01:25<00:06, 7.09it/s]
reward: -2.4133, last reward: -0.2289, gradient norm: 0.355: 92%|█████████▏| 577/625 [01:25<00:06, 7.08it/s]
reward: -2.9478, last reward: -0.0872, gradient norm: 0.7501: 92%|█████████▏| 577/625 [01:26<00:06, 7.08it/s]
reward: -2.9478, last reward: -0.0872, gradient norm: 0.7501: 92%|█████████▏| 578/625 [01:26<00:06, 7.08it/s]
reward: -2.4009, last reward: -0.0132, gradient norm: 0.2958: 92%|█████████▏| 578/625 [01:26<00:06, 7.08it/s]
reward: -2.4009, last reward: -0.0132, gradient norm: 0.2958: 93%|█████████▎| 579/625 [01:26<00:06, 7.08it/s]
reward: -3.1107, last reward: -0.4348, gradient norm: 1.236: 93%|█████████▎| 579/625 [01:26<00:06, 7.08it/s]
reward: -3.1107, last reward: -0.4348, gradient norm: 1.236: 93%|█████████▎| 580/625 [01:26<00:06, 7.08it/s]
reward: -2.6652, last reward: -0.0187, gradient norm: 0.4674: 93%|█████████▎| 580/625 [01:26<00:06, 7.08it/s]
reward: -2.6652, last reward: -0.0187, gradient norm: 0.4674: 93%|█████████▎| 581/625 [01:26<00:06, 7.08it/s]
reward: -2.4252, last reward: -0.0249, gradient norm: 0.5925: 93%|█████████▎| 581/625 [01:26<00:06, 7.08it/s]
reward: -2.4252, last reward: -0.0249, gradient norm: 0.5925: 93%|█████████▎| 582/625 [01:26<00:06, 7.08it/s]
reward: -2.2707, last reward: -0.0482, gradient norm: 0.4611: 93%|█████████▎| 582/625 [01:26<00:06, 7.08it/s]
reward: -2.2707, last reward: -0.0482, gradient norm: 0.4611: 93%|█████████▎| 583/625 [01:26<00:05, 7.09it/s]
reward: -2.3423, last reward: -0.0153, gradient norm: 0.3632: 93%|█████████▎| 583/625 [01:26<00:05, 7.09it/s]
reward: -2.3423, last reward: -0.0153, gradient norm: 0.3632: 93%|█████████▎| 584/625 [01:26<00:05, 7.09it/s]
reward: -1.9078, last reward: -0.0102, gradient norm: 0.3516: 93%|█████████▎| 584/625 [01:27<00:05, 7.09it/s]
reward: -1.9078, last reward: -0.0102, gradient norm: 0.3516: 94%|█████████▎| 585/625 [01:27<00:05, 7.10it/s]
reward: -2.5292, last reward: -0.0102, gradient norm: 0.2851: 94%|█████████▎| 585/625 [01:27<00:05, 7.10it/s]
reward: -2.5292, last reward: -0.0102, gradient norm: 0.2851: 94%|█████████▍| 586/625 [01:27<00:05, 7.09it/s]
reward: -2.3103, last reward: -0.1463, gradient norm: 0.9432: 94%|█████████▍| 586/625 [01:27<00:05, 7.09it/s]
reward: -2.3103, last reward: -0.1463, gradient norm: 0.9432: 94%|█████████▍| 587/625 [01:27<00:05, 6.99it/s]
reward: -2.4122, last reward: -0.0001, gradient norm: 0.237: 94%|█████████▍| 587/625 [01:27<00:05, 6.99it/s]
reward: -2.4122, last reward: -0.0001, gradient norm: 0.237: 94%|█████████▍| 588/625 [01:27<00:05, 7.02it/s]
reward: -1.8532, last reward: -0.0006, gradient norm: 0.6516: 94%|█████████▍| 588/625 [01:27<00:05, 7.02it/s]
reward: -1.8532, last reward: -0.0006, gradient norm: 0.6516: 94%|█████████▍| 589/625 [01:27<00:05, 6.94it/s]
reward: -1.9238, last reward: -0.0028, gradient norm: 1.491: 94%|█████████▍| 589/625 [01:27<00:05, 6.94it/s]
reward: -1.9238, last reward: -0.0028, gradient norm: 1.491: 94%|█████████▍| 590/625 [01:27<00:04, 7.01it/s]
reward: -2.1686, last reward: -0.0043, gradient norm: 0.6607: 94%|█████████▍| 590/625 [01:27<00:04, 7.01it/s]
reward: -2.1686, last reward: -0.0043, gradient norm: 0.6607: 95%|█████████▍| 591/625 [01:27<00:04, 6.94it/s]
reward: -2.2463, last reward: -0.0189, gradient norm: 3.761: 95%|█████████▍| 591/625 [01:28<00:04, 6.94it/s]
reward: -2.2463, last reward: -0.0189, gradient norm: 3.761: 95%|█████████▍| 592/625 [01:28<00:04, 7.00it/s]
reward: -2.3018, last reward: -0.0024, gradient norm: 0.583: 95%|█████████▍| 592/625 [01:28<00:04, 7.00it/s]
reward: -2.3018, last reward: -0.0024, gradient norm: 0.583: 95%|█████████▍| 593/625 [01:28<00:04, 7.04it/s]
reward: -2.9711, last reward: -0.7599, gradient norm: 9.948: 95%|█████████▍| 593/625 [01:28<00:04, 7.04it/s]
reward: -2.9711, last reward: -0.7599, gradient norm: 9.948: 95%|█████████▌| 594/625 [01:28<00:04, 7.08it/s]
reward: -3.0695, last reward: -0.2847, gradient norm: 15.14: 95%|█████████▌| 594/625 [01:28<00:04, 7.08it/s]
reward: -3.0695, last reward: -0.2847, gradient norm: 15.14: 95%|█████████▌| 595/625 [01:28<00:04, 7.10it/s]
reward: -2.8932, last reward: -0.3486, gradient norm: 2.536: 95%|█████████▌| 595/625 [01:28<00:04, 7.10it/s]
reward: -2.8932, last reward: -0.3486, gradient norm: 2.536: 95%|█████████▌| 596/625 [01:28<00:04, 7.12it/s]
reward: -2.2807, last reward: -0.0073, gradient norm: 0.8955: 95%|█████████▌| 596/625 [01:28<00:04, 7.12it/s]
reward: -2.2807, last reward: -0.0073, gradient norm: 0.8955: 96%|█████████▌| 597/625 [01:28<00:03, 7.12it/s]
reward: -2.5166, last reward: -0.0366, gradient norm: 1.076: 96%|█████████▌| 597/625 [01:28<00:03, 7.12it/s]
reward: -2.5166, last reward: -0.0366, gradient norm: 1.076: 96%|█████████▌| 598/625 [01:28<00:03, 7.12it/s]
reward: -2.2582, last reward: -0.0048, gradient norm: 0.8856: 96%|█████████▌| 598/625 [01:29<00:03, 7.12it/s]
reward: -2.2582, last reward: -0.0048, gradient norm: 0.8856: 96%|█████████▌| 599/625 [01:29<00:03, 7.13it/s]
reward: -2.6024, last reward: -0.0033, gradient norm: 1.831: 96%|█████████▌| 599/625 [01:29<00:03, 7.13it/s]
reward: -2.6024, last reward: -0.0033, gradient norm: 1.831: 96%|█████████▌| 600/625 [01:29<00:03, 7.13it/s]
reward: -2.6652, last reward: -0.0014, gradient norm: 0.1649: 96%|█████████▌| 600/625 [01:29<00:03, 7.13it/s]
reward: -2.6652, last reward: -0.0014, gradient norm: 0.1649: 96%|█████████▌| 601/625 [01:29<00:03, 7.13it/s]
reward: -2.2345, last reward: -0.0021, gradient norm: 1.584: 96%|█████████▌| 601/625 [01:29<00:03, 7.13it/s]
reward: -2.2345, last reward: -0.0021, gradient norm: 1.584: 96%|█████████▋| 602/625 [01:29<00:03, 7.14it/s]
reward: -2.7880, last reward: -0.5986, gradient norm: 58.89: 96%|█████████▋| 602/625 [01:29<00:03, 7.14it/s]
reward: -2.7880, last reward: -0.5986, gradient norm: 58.89: 96%|█████████▋| 603/625 [01:29<00:03, 7.03it/s]
reward: -2.6843, last reward: -0.8395, gradient norm: 22.09: 96%|█████████▋| 603/625 [01:29<00:03, 7.03it/s]
reward: -2.6843, last reward: -0.8395, gradient norm: 22.09: 97%|█████████▋| 604/625 [01:29<00:02, 7.05it/s]
reward: -2.5096, last reward: -0.4031, gradient norm: 20.38: 97%|█████████▋| 604/625 [01:29<00:02, 7.05it/s]
reward: -2.5096, last reward: -0.4031, gradient norm: 20.38: 97%|█████████▋| 605/625 [01:29<00:02, 6.94it/s]
reward: -2.9611, last reward: -0.2015, gradient norm: 0.7122: 97%|█████████▋| 605/625 [01:30<00:02, 6.94it/s]
reward: -2.9611, last reward: -0.2015, gradient norm: 0.7122: 97%|█████████▋| 606/625 [01:30<00:02, 7.02it/s]
reward: -2.6102, last reward: -0.0002, gradient norm: 0.98: 97%|█████████▋| 606/625 [01:30<00:02, 7.02it/s]
reward: -2.6102, last reward: -0.0002, gradient norm: 0.98: 97%|█████████▋| 607/625 [01:30<00:02, 7.06it/s]
reward: -2.5897, last reward: -0.0091, gradient norm: 1.989: 97%|█████████▋| 607/625 [01:30<00:02, 7.06it/s]
reward: -2.5897, last reward: -0.0091, gradient norm: 1.989: 97%|█████████▋| 608/625 [01:30<00:02, 7.08it/s]
reward: -3.0681, last reward: -0.4888, gradient norm: 12.83: 97%|█████████▋| 608/625 [01:30<00:02, 7.08it/s]
reward: -3.0681, last reward: -0.4888, gradient norm: 12.83: 97%|█████████▋| 609/625 [01:30<00:02, 7.09it/s]
reward: -2.5888, last reward: -0.4749, gradient norm: 5.331: 97%|█████████▋| 609/625 [01:30<00:02, 7.09it/s]
reward: -2.5888, last reward: -0.4749, gradient norm: 5.331: 98%|█████████▊| 610/625 [01:30<00:02, 7.10it/s]
reward: -2.8486, last reward: -0.2684, gradient norm: 33.61: 98%|█████████▊| 610/625 [01:30<00:02, 7.10it/s]
reward: -2.8486, last reward: -0.2684, gradient norm: 33.61: 98%|█████████▊| 611/625 [01:30<00:01, 7.11it/s]
reward: -2.7043, last reward: -0.0489, gradient norm: 12.56: 98%|█████████▊| 611/625 [01:30<00:01, 7.11it/s]
reward: -2.7043, last reward: -0.0489, gradient norm: 12.56: 98%|█████████▊| 612/625 [01:30<00:01, 7.11it/s]
reward: -2.3987, last reward: -0.2125, gradient norm: 2.658: 98%|█████████▊| 612/625 [01:31<00:01, 7.11it/s]
reward: -2.3987, last reward: -0.2125, gradient norm: 2.658: 98%|█████████▊| 613/625 [01:31<00:01, 7.13it/s]
reward: -1.8952, last reward: -0.0075, gradient norm: 0.6018: 98%|█████████▊| 613/625 [01:31<00:01, 7.13it/s]
reward: -1.8952, last reward: -0.0075, gradient norm: 0.6018: 98%|█████████▊| 614/625 [01:31<00:01, 7.13it/s]
reward: -2.6729, last reward: -0.0083, gradient norm: 0.6076: 98%|█████████▊| 614/625 [01:31<00:01, 7.13it/s]
reward: -2.6729, last reward: -0.0083, gradient norm: 0.6076: 98%|█████████▊| 615/625 [01:31<00:01, 7.01it/s]
reward: -1.6790, last reward: -0.0059, gradient norm: 1.045: 98%|█████████▊| 615/625 [01:31<00:01, 7.01it/s]
reward: -1.6790, last reward: -0.0059, gradient norm: 1.045: 99%|█████████▊| 616/625 [01:31<00:01, 6.92it/s]
reward: -2.0006, last reward: -0.0017, gradient norm: 0.8298: 99%|█████████▊| 616/625 [01:31<00:01, 6.92it/s]
reward: -2.0006, last reward: -0.0017, gradient norm: 0.8298: 99%|█████████▊| 617/625 [01:31<00:01, 6.97it/s]
reward: -2.3416, last reward: -0.0000, gradient norm: 0.9434: 99%|█████████▊| 617/625 [01:31<00:01, 6.97it/s]
reward: -2.3416, last reward: -0.0000, gradient norm: 0.9434: 99%|█████████▉| 618/625 [01:31<00:00, 7.02it/s]
reward: -1.7485, last reward: -0.0014, gradient norm: 0.3162: 99%|█████████▉| 618/625 [01:31<00:00, 7.02it/s]
reward: -1.7485, last reward: -0.0014, gradient norm: 0.3162: 99%|█████████▉| 619/625 [01:31<00:00, 7.06it/s]
reward: -1.9527, last reward: -0.0080, gradient norm: 8.77: 99%|█████████▉| 619/625 [01:32<00:00, 7.06it/s]
reward: -1.9527, last reward: -0.0080, gradient norm: 8.77: 99%|█████████▉| 620/625 [01:32<00:00, 7.07it/s]
reward: -2.5158, last reward: -0.0108, gradient norm: 2.981: 99%|█████████▉| 620/625 [01:32<00:00, 7.07it/s]
reward: -2.5158, last reward: -0.0108, gradient norm: 2.981: 99%|█████████▉| 621/625 [01:32<00:00, 7.10it/s]
reward: -2.1297, last reward: -0.0140, gradient norm: 0.4386: 99%|█████████▉| 621/625 [01:32<00:00, 7.10it/s]
reward: -2.1297, last reward: -0.0140, gradient norm: 0.4386: 100%|█████████▉| 622/625 [01:32<00:00, 7.12it/s]
reward: -2.7693, last reward: -0.0410, gradient norm: 1.005: 100%|█████████▉| 622/625 [01:32<00:00, 7.12it/s]
reward: -2.7693, last reward: -0.0410, gradient norm: 1.005: 100%|█████████▉| 623/625 [01:32<00:00, 7.13it/s]
reward: -2.4789, last reward: -0.0168, gradient norm: 5.275: 100%|█████████▉| 623/625 [01:32<00:00, 7.13it/s]
reward: -2.4789, last reward: -0.0168, gradient norm: 5.275: 100%|█████████▉| 624/625 [01:32<00:00, 7.13it/s]
reward: -2.3069, last reward: -0.2734, gradient norm: 12.32: 100%|█████████▉| 624/625 [01:32<00:00, 7.13it/s]
reward: -2.3069, last reward: -0.2734, gradient norm: 12.32: 100%|██████████| 625/625 [01:32<00:00, 7.03it/s]
reward: -2.3069, last reward: -0.2734, gradient norm: 12.32: 100%|██████████| 625/625 [01:32<00:00, 6.74it/s]
Conclusion#
In this tutorial, we have learned how to code a stateless environment from scratch. We touched the subjects of:
The four essential components that need to be taken care of when coding an environment (
step,reset, seeding and building specs). We saw how these methods and classes interact with theTensorDictclass;How to test that an environment is properly coded using
check_env_specs();How to append transforms in the context of stateless environments and how to write custom transformations;
How to train a policy on a fully differentiable simulator.
Total running time of the script: (1 minutes 33.918 seconds)
