


참고
Go to the end to download the full example code.
공간 변형 네트워크(Spatial Transformer Networks) 튜토리얼#
- Author: Ghassen HAMROUNI

이 튜토리얼에서는 공간 변형 네트워크(spatial transformer networks, 이하 STN)이라 불리는 비주얼 어텐션 메커니즘을 이용해 신경망을 증강(augment)시키는 방법에 대해 학습합니다. 이 방법에 대한 자세한 내용은 DeepMind paper 에서 확인할 수 있습니다. STN은 어떠한 공간적 변형(spatial transformation)에도 적용할 수 있는 미분 가능한 어텐션의 일반화입니다. 따라서 STN은 신경망의 기하학적 불변성(geometric invariance)을 강화하기 위해 입력 이미지를 대상으로 어떠한 공간적 변형을 수행해야 하는지 학습하도록 합니다. 예를 들어 이미지의 관심 영역을 잘라내거나, 크기를 조정하거나, 방향(orientation)을 수정할 수 있습니다. CNN은 이러한 회전, 크기 조정 등의 일반적인 아핀(affine) 변환된 입력에 대해 결과의 변동이 크기 때문에 (민감하기 때문에), STN은 이를 극복하는데 매우 유용한 메커니즘이 될 수 있습니다. STN이 가진 장점 중 하나는 아주 작은 수정만으로 기존에 사용하던 CNN에 간단하게 연결 시킬 수 있다는 것입니다.
# 라이센스: BSD
# 저자: Ghassen Hamrouni
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
plt.ion() # 대화형 모드
<contextlib.ExitStack object at 0x7f0dab407f10>
데이터 불러오기#
이 튜토리얼에서는 MNIST 데이터셋을 이용해 실험합니다. 실험에는 STN으로 증강된 일반적인 CNN을 사용합니다.
from six.moves import urllib
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
urllib.request.install_opener(opener)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 학습용 데이터셋
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='.', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=64, shuffle=True, num_workers=4)
# 테스트용 데이터셋
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='.', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=64, shuffle=True, num_workers=4)
0%| | 0.00/9.91M [00:00<?, ?B/s]
0%| | 32.8k/9.91M [00:00<00:54, 182kB/s]
1%| | 98.3k/9.91M [00:00<00:33, 289kB/s]
2%|▏ | 197k/9.91M [00:00<00:23, 407kB/s]
4%|▍ | 393k/9.91M [00:00<00:13, 683kB/s]
8%|▊ | 786k/9.91M [00:00<00:07, 1.23MB/s]
16%|█▌ | 1.61M/9.91M [00:01<00:03, 2.36MB/s]
33%|███▎ | 3.24M/9.91M [00:01<00:01, 4.57MB/s]
66%|██████▌ | 6.52M/9.91M [00:01<00:00, 8.92MB/s]
84%|████████▍ | 8.32M/9.91M [00:01<00:00, 8.68MB/s]
100%|█████████▉| 9.90M/9.91M [00:01<00:00, 8.70MB/s]
100%|██████████| 9.91M/9.91M [00:01<00:00, 5.40MB/s]
0%| | 0.00/28.9k [00:00<?, ?B/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 162kB/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 161kB/s]
0%| | 0.00/1.65M [00:00<?, ?B/s]
2%|▏ | 32.8k/1.65M [00:00<00:09, 175kB/s]
6%|▌ | 98.3k/1.65M [00:00<00:05, 277kB/s]
12%|█▏ | 197k/1.65M [00:00<00:03, 389kB/s]
24%|██▍ | 393k/1.65M [00:00<00:01, 649kB/s]
48%|████▊ | 786k/1.65M [00:00<00:00, 1.17MB/s]
99%|█████████▉| 1.64M/1.65M [00:01<00:00, 2.31MB/s]
100%|██████████| 1.65M/1.65M [00:01<00:00, 1.46MB/s]
0%| | 0.00/4.54k [00:00<?, ?B/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 3.12MB/s]
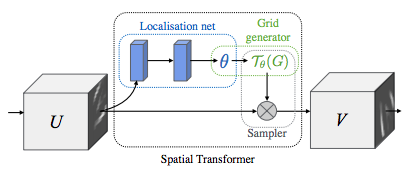
Spatial Transformer Networks(STN) 구성하기#
STN은 다음의 세 가지 주요 구성 요소로 요약됩니다.
위치 결정 네트워크(localization network)는 공간 변환 파라미터를 예측(regress) 하는 일반적인 CNN 입니다. 공간 변환은 데이터 셋으로부터 명시적으로 학습되지 않고, 신경망이 전체 정확도를 향상 시키도록 공간 변환을 자동으로 학습합니다.
그리드 생성기(grid generator)는 출력 이미지로부터 각 픽셀에 대응하는 입력 이미지 내 좌표 그리드를 생성합니다.
샘플러(sampler)는 공간 변환 파라미터를 입력 이미지에 적용합니다.
참고
affine_grid 및 grid_sample 모듈이 포함된 최신 버전의 PyTorch가 필요합니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
# 공간 변환을 위한 위치 결정 네트워크 (localization-network)
self.localization = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=7),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True),
nn.Conv2d(8, 10, kernel_size=5),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True)
)
# [3 * 2] 크기의 아핀(affine) 행렬에 대해 예측
self.fc_loc = nn.Sequential(
nn.Linear(10 * 3 * 3, 32),
nn.ReLU(True),
nn.Linear(32, 3 * 2)
)
# 항등 변환(identity transformation)으로 가중치/바이어스 초기화
self.fc_loc[2].weight.data.zero_()
self.fc_loc[2].bias.data.copy_(torch.tensor([1, 0, 0, 0, 1, 0], dtype=torch.float))
# STN의 forward 함수
def stn(self, x):
xs = self.localization(x)
xs = xs.view(-1, 10 * 3 * 3)
theta = self.fc_loc(xs)
theta = theta.view(-1, 2, 3)
grid = F.affine_grid(theta, x.size())
x = F.grid_sample(x, grid)
return x
def forward(self, x):
# 입력을 변환
x = self.stn(x)
# 일반적인 forward pass를 수행
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model = Net().to(device)
모델 학습하기#
이제 SGD 알고리즘을 이용해 모델을 학습시켜 봅시다. 앞서 구성한 신경망은 감독 학습 방식(supervised way)으로 분류 문제를 학습합니다. 또한 이 모델은 end-to-end 방식으로 STN을 자동으로 학습합니다.
optimizer = optim.SGD(model.parameters(), lr=0.01)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 500 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#
# MNIST 데이터셋에서 STN의 성능을 측정하기 위한 간단한 테스트 절차
#
def test():
with torch.no_grad():
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# 배치 손실 합하기
test_loss += F.nll_loss(output, target, size_average=False).item()
# 로그-확률의 최대값에 해당하는 인덱스 가져오기
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'
.format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
STN 결과 시각화하기#
이제 학습한 비주얼 어텐션 메커니즘의 결과를 살펴보겠습니다.
학습하는 동안 변환된 결과를 시각화하기 위해 작은 도움(helper) 함수를 정의합니다.
def convert_image_np(inp):
"""Convert a Tensor to numpy image."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
return inp
# 학습 후 공간 변환 계층의 출력을 시각화하고, 입력 이미지 배치 데이터 및
# STN을 사용해 변환된 배치 데이터를 시각화 합니다.
def visualize_stn():
with torch.no_grad():
# 학습 데이터의 배치 가져오기
data = next(iter(test_loader))[0].to(device)
input_tensor = data.cpu()
transformed_input_tensor = model.stn(data).cpu()
in_grid = convert_image_np(
torchvision.utils.make_grid(input_tensor))
out_grid = convert_image_np(
torchvision.utils.make_grid(transformed_input_tensor))
# 결과를 나란히 표시하기
f, axarr = plt.subplots(1, 2)
axarr[0].imshow(in_grid)
axarr[0].set_title('Dataset Images')
axarr[1].imshow(out_grid)
axarr[1].set_title('Transformed Images')
for epoch in range(1, 20 + 1):
train(epoch)
test()
# 일부 입력 배치 데이터에서 STN 변환 결과를 시각화
visualize_stn()
plt.ioff()
plt.show()

/opt/conda/lib/python3.11/site-packages/torch/nn/functional.py:5163: UserWarning:
Default grid_sample and affine_grid behavior has changed to align_corners=False since 1.3.0. Please specify align_corners=True if the old behavior is desired. See the documentation of grid_sample for details.
/opt/conda/lib/python3.11/site-packages/torch/nn/functional.py:5096: UserWarning:
Default grid_sample and affine_grid behavior has changed to align_corners=False since 1.3.0. Please specify align_corners=True if the old behavior is desired. See the documentation of grid_sample for details.
Train Epoch: 1 [0/60000 (0%)] Loss: 2.355279
Train Epoch: 1 [32000/60000 (53%)] Loss: 0.809743
/opt/conda/lib/python3.11/site-packages/torch/nn/_reduction.py:51: UserWarning:
size_average and reduce args will be deprecated, please use reduction='sum' instead.
Test set: Average loss: 0.2437, Accuracy: 9284/10000 (93%)
Train Epoch: 2 [0/60000 (0%)] Loss: 0.419136
Train Epoch: 2 [32000/60000 (53%)] Loss: 0.523208
Test set: Average loss: 0.1428, Accuracy: 9550/10000 (96%)
Train Epoch: 3 [0/60000 (0%)] Loss: 0.251175
Train Epoch: 3 [32000/60000 (53%)] Loss: 0.409184
Test set: Average loss: 0.1130, Accuracy: 9645/10000 (96%)
Train Epoch: 4 [0/60000 (0%)] Loss: 0.201291
Train Epoch: 4 [32000/60000 (53%)] Loss: 0.211475
Test set: Average loss: 0.0726, Accuracy: 9777/10000 (98%)
Train Epoch: 5 [0/60000 (0%)] Loss: 0.358470
Train Epoch: 5 [32000/60000 (53%)] Loss: 0.269853
Test set: Average loss: 0.0590, Accuracy: 9805/10000 (98%)
Train Epoch: 6 [0/60000 (0%)] Loss: 0.167644
Train Epoch: 6 [32000/60000 (53%)] Loss: 0.181759
Test set: Average loss: 0.0656, Accuracy: 9794/10000 (98%)
Train Epoch: 7 [0/60000 (0%)] Loss: 0.048985
Train Epoch: 7 [32000/60000 (53%)] Loss: 0.161709
Test set: Average loss: 0.0647, Accuracy: 9810/10000 (98%)
Train Epoch: 8 [0/60000 (0%)] Loss: 0.085148
Train Epoch: 8 [32000/60000 (53%)] Loss: 0.058724
Test set: Average loss: 0.0602, Accuracy: 9814/10000 (98%)
Train Epoch: 9 [0/60000 (0%)] Loss: 0.245395
Train Epoch: 9 [32000/60000 (53%)] Loss: 0.204386
Test set: Average loss: 0.0517, Accuracy: 9844/10000 (98%)
Train Epoch: 10 [0/60000 (0%)] Loss: 0.235060
Train Epoch: 10 [32000/60000 (53%)] Loss: 0.167804
Test set: Average loss: 0.0511, Accuracy: 9838/10000 (98%)
Train Epoch: 11 [0/60000 (0%)] Loss: 0.026840
Train Epoch: 11 [32000/60000 (53%)] Loss: 0.075112
Test set: Average loss: 0.0500, Accuracy: 9857/10000 (99%)
Train Epoch: 12 [0/60000 (0%)] Loss: 0.119121
Train Epoch: 12 [32000/60000 (53%)] Loss: 0.072512
Test set: Average loss: 0.0562, Accuracy: 9841/10000 (98%)
Train Epoch: 13 [0/60000 (0%)] Loss: 0.263984
Train Epoch: 13 [32000/60000 (53%)] Loss: 0.054613
Test set: Average loss: 0.0456, Accuracy: 9868/10000 (99%)
Train Epoch: 14 [0/60000 (0%)] Loss: 0.182186
Train Epoch: 14 [32000/60000 (53%)] Loss: 0.070359
Test set: Average loss: 0.0492, Accuracy: 9867/10000 (99%)
Train Epoch: 15 [0/60000 (0%)] Loss: 0.027023
Train Epoch: 15 [32000/60000 (53%)] Loss: 0.066413
Test set: Average loss: 0.0520, Accuracy: 9851/10000 (99%)
Train Epoch: 16 [0/60000 (0%)] Loss: 0.024808
Train Epoch: 16 [32000/60000 (53%)] Loss: 0.120296
Test set: Average loss: 0.0582, Accuracy: 9834/10000 (98%)
Train Epoch: 17 [0/60000 (0%)] Loss: 0.032364
Train Epoch: 17 [32000/60000 (53%)] Loss: 0.074327
Test set: Average loss: 0.0475, Accuracy: 9869/10000 (99%)
Train Epoch: 18 [0/60000 (0%)] Loss: 0.259206
Train Epoch: 18 [32000/60000 (53%)] Loss: 0.090468
Test set: Average loss: 0.0514, Accuracy: 9850/10000 (98%)
Train Epoch: 19 [0/60000 (0%)] Loss: 0.070934
Train Epoch: 19 [32000/60000 (53%)] Loss: 0.056534
Test set: Average loss: 0.0471, Accuracy: 9857/10000 (99%)
Train Epoch: 20 [0/60000 (0%)] Loss: 0.045684
Train Epoch: 20 [32000/60000 (53%)] Loss: 0.039626
Test set: Average loss: 0.0480, Accuracy: 9866/10000 (99%)
Total running time of the script: (1 minutes 50.684 seconds)
