


전체론적(Holistic Trace Analysis) 추적 분석 소개#
저자: Anupam Bhatnagar 번역: Jaeseong Park
이 튜토리얼에서는 분산 학습 작업의 추적을 분석하기 위해 전체론적 추적 분석(Holistic Trace Analysis, HTA)을 사용하는 방법을 보여줍니다. 시작하려면 아래 단계를 따르세요.
HTA 설치하기#
HTA를 설치하기 위해 Conda 환경을 사용하는 것을 권장합니다. Anaconda를 설치하려면 `공식 Anaconda 문서 <https://docs.anaconda.com/anaconda/install/index.html>`_를 참조하세요.
pip를 사용하여 HTA 설치:
pip install HolisticTraceAnalysis
(선택사항이지만 권장) Conda 환경 설정:
# env_name 가상환경 생성 conda create -n env_name # 환경 활성화 conda activate env_name # 작업이 끝나면 ``conda deactivate``를 실행하여 환경을 비활성화하세요
시작하기#
Jupyter 노트북을 실행하고 trace_dir 변수를 추적 파일이 있는 위치로 설정하세요.
from hta.trace_analysis import TraceAnalysis
trace_dir = "/path/to/folder/with/traces"
analyzer = TraceAnalysis(trace_dir=trace_dir)
시간적 분석#
GPU를 효과적으로 활용하기 위해서는 특정 작업에 대해 GPU가 시간을 어떻게 사용하고 있는지 이해하는 것이 중요합니다. GPU가 주로 계산, 통신, 메모리 이벤트에 사용되고 있는지, 아니면 유휴 상태인지? 시간적 분석 기능은 이 세 가지 범주에서 사용된 시간에 대한 상세한 분석을 제공합니다.
유휴 시간 - GPU가 유휴 상태입니다.
계산 시간 - GPU가 행렬 곱셈이나 벡터 연산에 사용되고 있습니다.
비계산 시간 - GPU가 통신이나 메모리 이벤트에 사용되고 있습니다.
높은 학습 효율성을 달성하기 위해서는 코드가 계산 시간을 최대화하고 유휴 시간과 비계산 시간을 최소화해야 합니다. 다음 함수는 각 랭크에 대한 시간 사용의 상세한 분석을 제공하는 데이터프레임을 생성합니다.
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
time_spent_df = analyzer.get_temporal_breakdown()
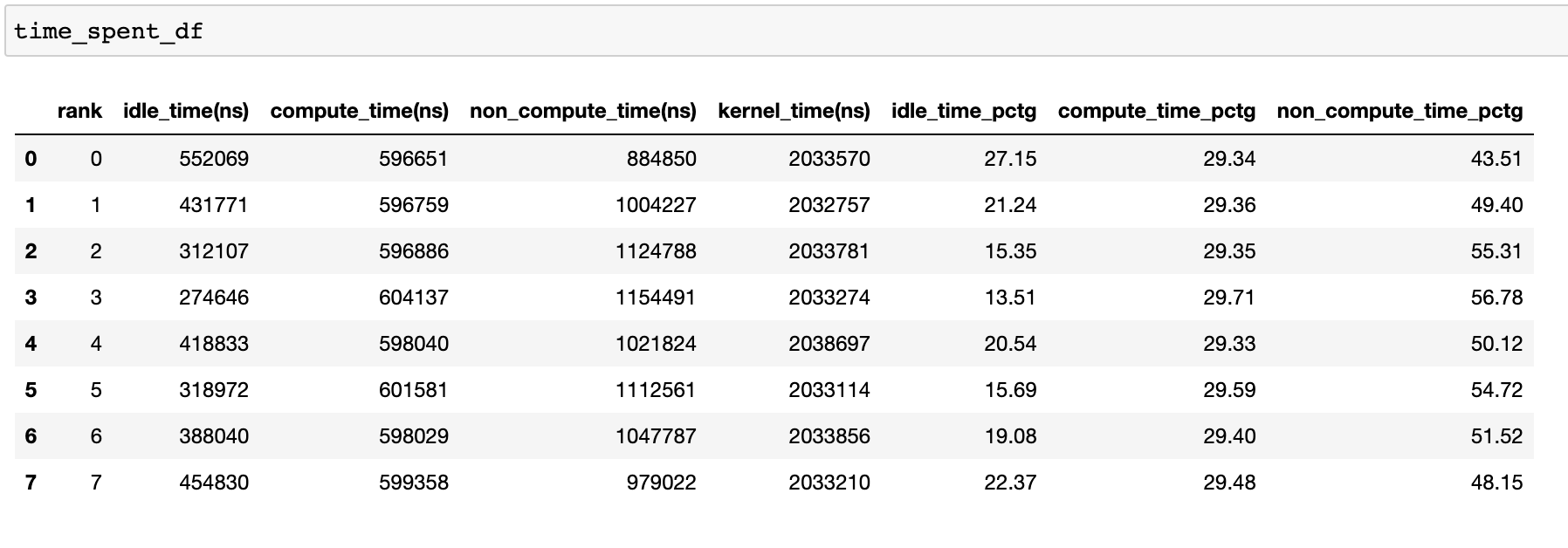
get_temporal_breakdown 함수에서 visualize 인수를 ``True``로 설정하면 랭크별 분석을 나타내는 막대 그래프도 생성됩니다.
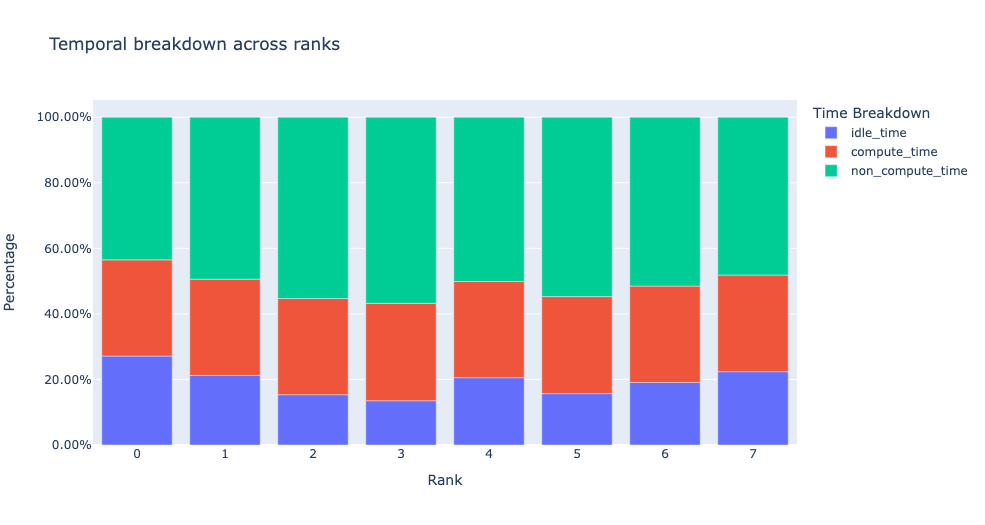
유휴 시간 분석#
GPU가 유휴 상태로 보내는 시간과 그 이유에 대한 통찰을 얻으면 최적화 전략을 수립하는 데 도움이 될 수 있습니다. GPU에서 실행 중인 커널이 없을 때 GPU는 유휴 상태로 간주됩니다. 우리는 유휴 시간을 세 가지 뚜렷한 범주로 분류하는 알고리즘을 개발했습니다:
호스트 대기: CPU가 GPU를 완전히 활용하기 위해 충분히 빠르게 커널을 대기열에 넣지 않아 발생하는 GPU의 유휴 시간을 말합니다. 해당 유형의 비효율성을 해결하기 위해 속도 저하에 기여하는 CPU 연산자를 검사하고, 배치 크기를 늘리고, 연산자 융합을 적용할 수 있습니다.
커널 대기: GPU에서 연속적인 커널을 실행하는 것과 관련된 간단한 오버헤드를 말합니다. 이 범주에 속하는 유휴 시간은 CUDA 그래프 최적화를 사용하여 최소화할 수 있습니다.
기타 대기: 현재 정보가 부족하여 특정 원인을 파악할 수 없는 유휴 시간이 이 범주에 포함됩니다. 가능한 원인으로는 CUDA 이벤트를 사용한 CUDA 스트림 간의 동기화와 커널 실행 지연 등이 있습니다.
호스트 대기 시간은 CPU로 인해 GPU가 정체되는 시간으로 해석할 수 있습니다. 유휴 시간을 커널 대기로 분류하기 위해 우리는 다음과 같은 휴리스틱(heuristic)을 사용합니다:
연속적인 커널 사이의 간격 < 임계값
기본 임계값은 30 나노초이며 consecutive_kernel_delay 인수를 사용하여 구성할 수 있습니다. 기본적으로 유휴 시간 분석은 랭크 0에 대해서만 계산됩니다. 다른 랭크에 대해 분석을 계산하려면 get_idle_time_breakdown 함수에서 ranks 인수를 사용하세요. 유휴 시간 분석은 다음과 같이 생성할 수 있습니다:
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
idle_time_df = analyzer.get_idle_time_breakdown()
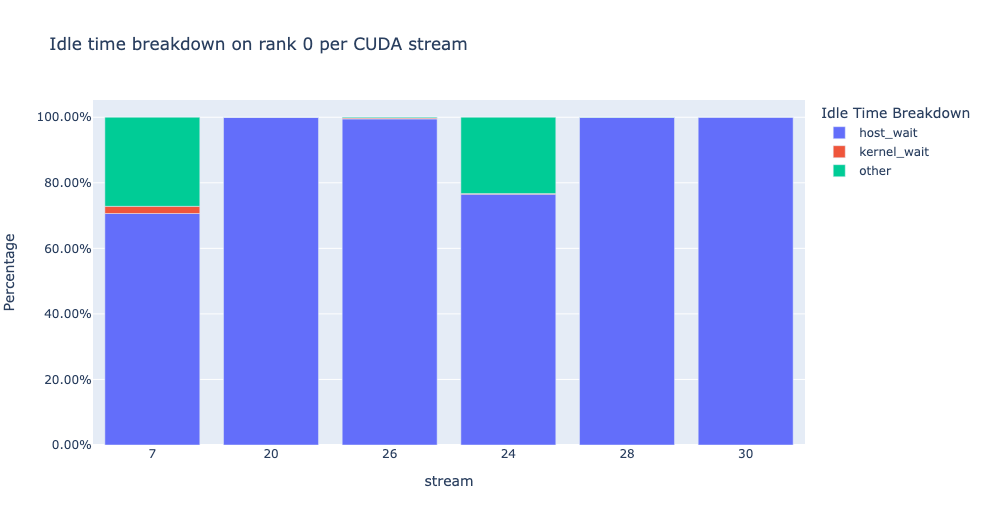
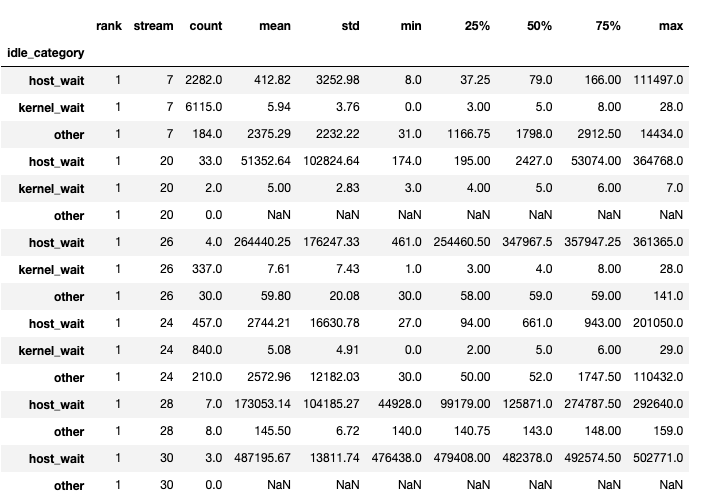
이 함수는 데이터프레임 튜플을 반환합니다. 첫 번째 데이터프레임은 각 랭크의 각 스트림에 대한 유휴 시간 범주별 시간을 포함합니다.
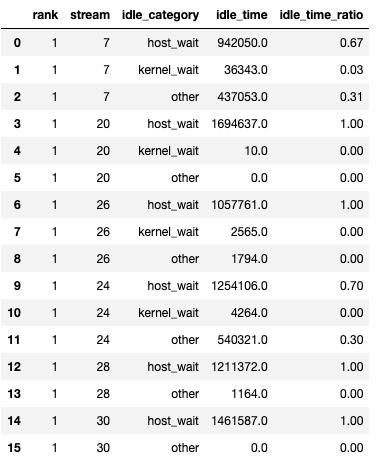
두 번째 데이터프레임은 `show_idle_interval_stats`가 `True`로 설정되었을 때 생성됩니다. 이 데이터프레임은 각 랭크의 각 스트림에 대한 유휴 시간의 요약 통계를 포함합니다.
팁
기본적으로 유휴 시간 분석은 각 유휴 시간 범주의 백분율을 표시합니다. visualize_pctg 인수를 `False`로 설정하면 함수는 y축에 절대 시간을 표시합니다.
커널 분석#
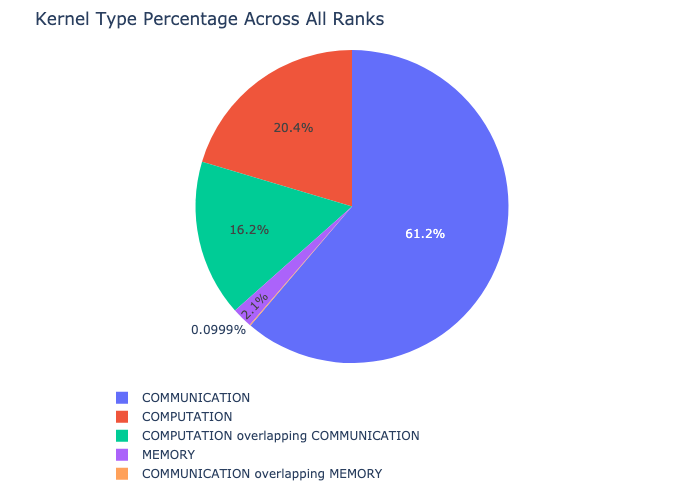
커널 분석 기능은 모든 랭크에서 통신(COMM), 계산(COMP), 메모리(MEM)와 같은 각 커널 유형에 대해 사용된 시간을 분석하고 각 범주에서 사용된 시간의 비율을 제시합니다. 다음은 각 범주에서 사용된 시간의 백분율을 원형 차트로 나타낸 것입니다:
커널 분석은 다음과 같이 계산할 수 있습니다:
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
kernel_type_metrics_df, kernel_metrics_df = analyzer.get_gpu_kernel_breakdown()
함수가 반환하는 첫 번째 데이터프레임은 원형 차트를 생성하는 데 사용된 원래 값을 포함합니다.
커널 기간 분포#
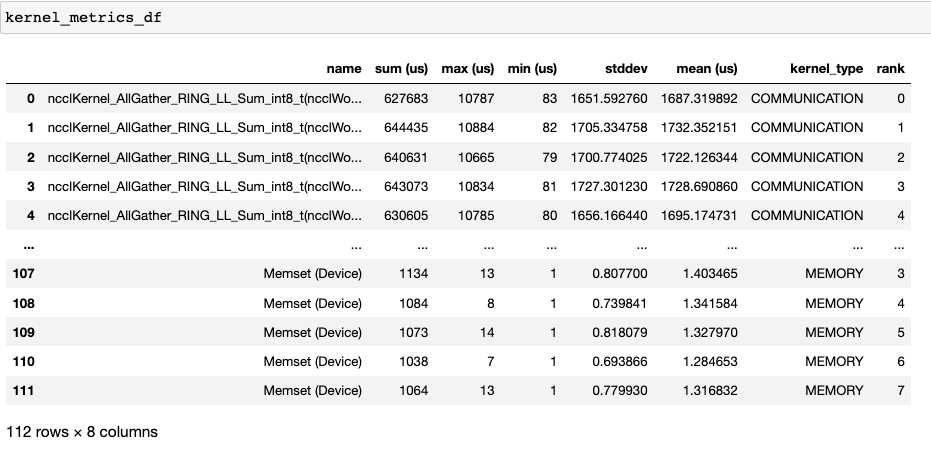
get_gpu_kernel_breakdown 함수가 반환하는 두 번째 데이터프레임에는 각 커널에 대한 기간 요약 통계가 포함되어 있습니다. 특히, 이는 각 커널에 대해 랭크별로 카운트, 최소, 최대, 평균, 표준 편차, 합계, 그리고 커널 유형을 포함합니다.
이 데이터를 사용하여 HTA는 성능 병목 현상을 식별하기 위한 여러 시각화를 생성합니다.
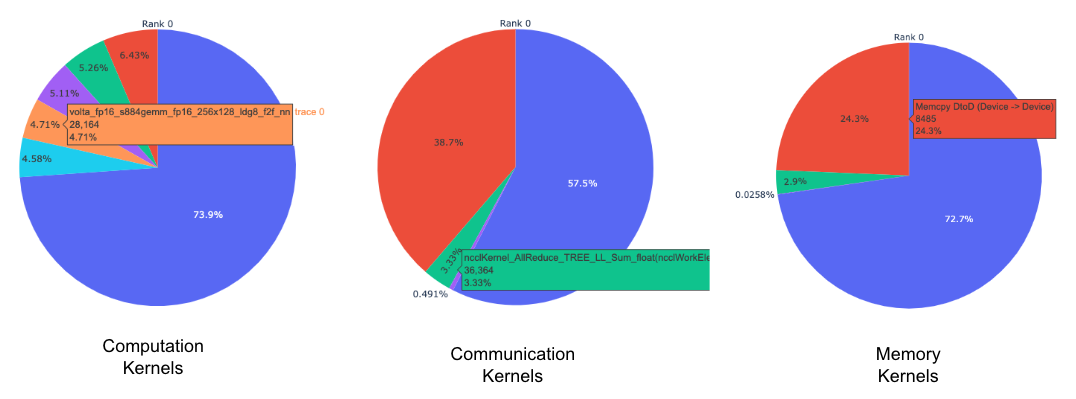
각 랭크별로 각 커널 유형에 대한 상위 커널의 원형 차트.
상위 커널 및 각 커널 유형에 대해 모든 랭크에 걸친 평균 기간의 막대 그래프.
모든 이미지는 plotly를 사용하여 생성됩니다. 그래프 위에 마우스를 올리면 우측 상단에 모드 바가 나타나며, 이를 통해 확대, 이동, 선택 및 그래프 다운로드가 가능합니다.
위의 원형 차트는 상위 5개의 계산, 통신, 메모리 커널을 보여줍니다. 각 랭크에 대해 유사한 원형 차트가 생성됩니다. 원형 차트는 get_gpu_kernel_breakdown 함수에 전달된 num_kernels 인자를 사용하여 상위 k개의 커널을 보여주도록 설정할 수 있습니다. 또한, duration_ratio 인자를 사용하여 분석될 시간의 비율을 조정할 수 있습니다. num_kernels`와 `duration_ratio 모두 지정된 경우, `num_kernels`가 우선합니다.
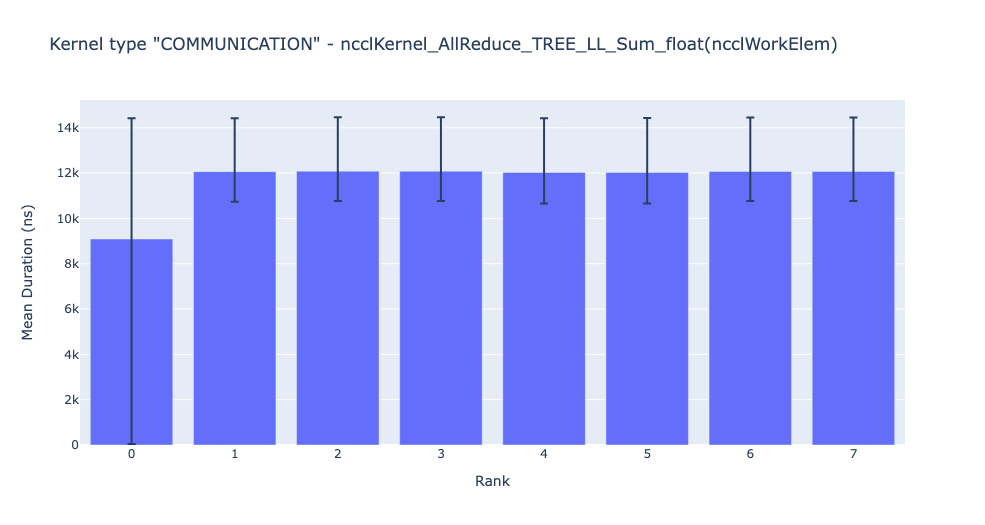
위의 막대 그래프는 모든 랭크에 걸친 NCCL AllReduce 커널의 평균 기간을 보여줍니다. 검은 선은 각 랭크에서의 최소 및 최대 시간을 나타냅니다.
경고
jupyter-lab을 사용할 때 “image_renderer” 인자의 값을 “jupyterlab”으로 설정해야 노트북에서 그래프가 렌더링됩니다.
이 기능에 대한 자세한 설명은 저장소의 예제 폴더에 있는 `gpu_kernel_breakdown notebook <facebookresearch/HolisticTraceAnalysis>`_을 참조하세요.
통신 계산 중첩#
분산 학습에서 상당한 시간이 GPU 간의 통신 및 동기화 이벤트에 소비됩니다. 높은 GPU 효율성(TFLOPS/GPU)을 달성하기 위해서는 GPU가 계산 커널로 과도하게 할당된 상태를 유지하는 것이 중요합니다. 즉, GPU는 해결되지 않은 데이터 의존성으로 인해 차단되어서는 안 됩니다. 계산이 데이터 의존성에 의해 차단되는 정도를 측정하는 한 가지 방법은 통신 계산 중첩을 계산하는 것입니다. 통신 이벤트가 계산 이벤트와 겹칠 때 더 높은 GPU 효율성이 관찰됩니다. 통신과 계산의 중첩이 부족하면 GPU가 유휴 상태가 되어 낮은 효율성으로 이어집니다. 요약하자면, 더 높은 통신 계산 중첩이 바람직합니다. 각 랭크에 대한 중첩 비율을 계산하기 위해 다음 비율을 측정합니다:
(통신 중에 소비된 계산 시간) / (통신에 소비된 시간)
통신 계산 중첩은 다음과 같이 계산할 수 있습니다:
analyzer = TraceAnalysis(trace_dir="/path/to/trace/folder")
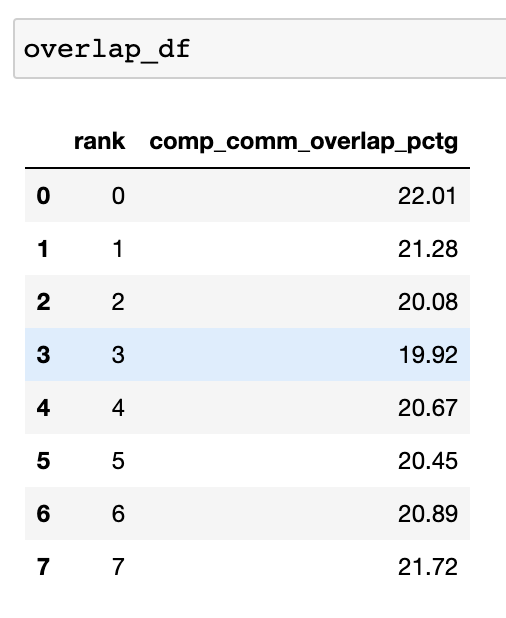
overlap_df = analyzer.get_comm_comp_overlap()
이 함수는 각 랭크에 대한 중첩 비율을 포함하는 데이터프레임을 반환합니다.
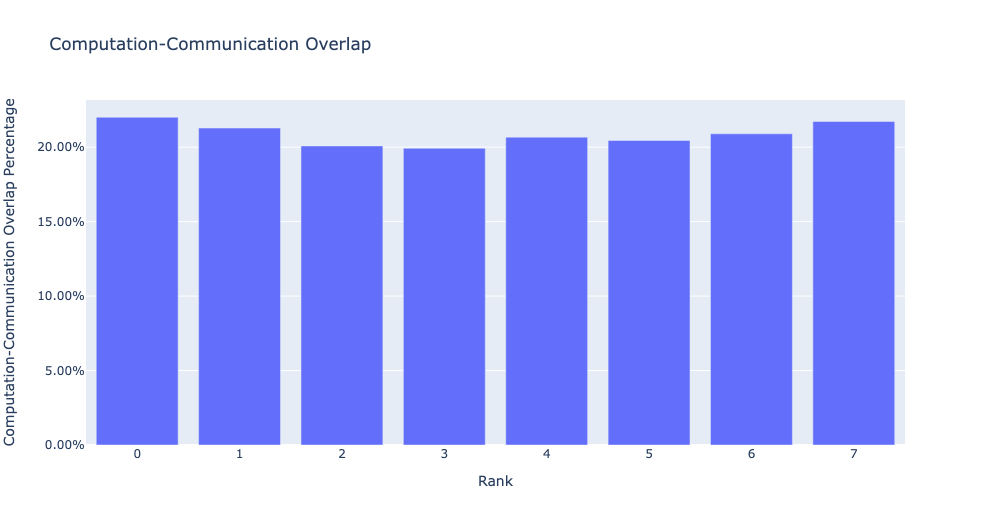
visualize 인자가 True로 설정되면, get_comm_comp_overlap 함수는 또한 랭크별 중첩을 나타내는 막대 그래프를 생성합니다.
증강된 카운터#
메모리 대역폭 & 큐 길이 카운터#
메모리 대역폭 카운터는 메모리 복사(memcpy) 및 메모리 설정(memset) 이벤트에 의해 데이터를 H2D, D2H 및 D2D로 복사할 때 사용된 메모리 복사 대역폭을 측정합니다. HTA는 또한 각 CUDA 스트림에서 진행 중인 작업의 수를 계산합니다. 우리는 이를 **큐 길이**라고 부릅니다. 스트림의 큐 길이가 1024 이상일 때, 그 스트림에 새로운 이벤트가 스케줄될 수 없으며, GPU 스트림의 이벤트가 처리될 때까지 CPU는 멈춰있습니다.
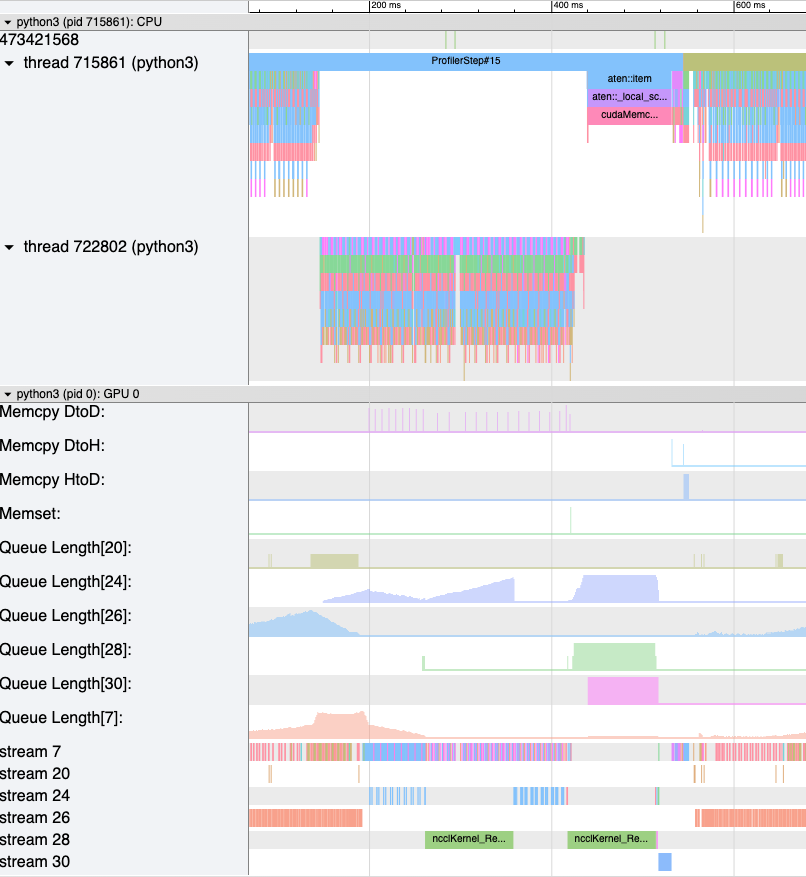
generate_trace_with_counters API는 메모리 대역폭 및 큐 길이 카운터가 포함된 새로운 추적 파일을 출력합니다. 새로운 추적 파일에는 memcpy/memset 작업에 의해 사용된 메모리 대역폭을 나타내는 트랙과 각 스트림의 큐 길이를 나타내는 트랙이 포함됩니다. 기본적으로, 이러한 카운터는 랭크 0 추적 파일을 사용하여 생성되며, 새 파일의 이름에는 ``_with_counters``라는 접미사가 포함됩니다. 사용자는 generate_trace_with_counters API의 ranks 인수를 사용하여 여러 랭크에 대한 카운터를 생성할 수 있습니다.
analyzer = TraceAnalysis(trace_dir="/path/to/trace/folder")
analyzer.generate_trace_with_counters()
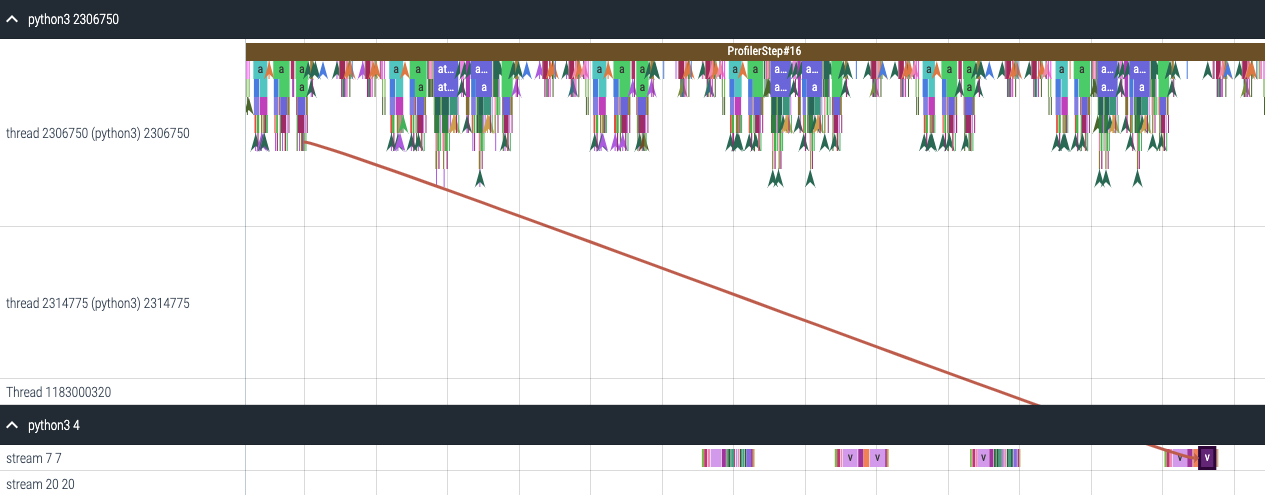
증강된 카운터가 포함된 생성된 추적 파일의 스크린샷.
HTA는 또한 다음 API를 사용하여 프로파일된 코드 부분에 대한 메모리 복사 대역폭 및 큐 길이 카운터의 요약과 시계열을 제공합니다:
요약 및 시계열을 보기 위해 다음을 사용하세요:
# 요약 생성
mem_bw_summary = analyzer.get_memory_bw_summary()
queue_len_summary = analyzer.get_queue_length_summary()
# 시계열 가져오기
mem_bw_series = analyzer.get_memory_bw_time_series()
queue_len_series = analyzer.get_queue_length_series()
요약에는 카운트, 최소, 최대, 평균, 표준 편차, 25번째, 50번째, 75번째 백분위수가 포함됩니다.
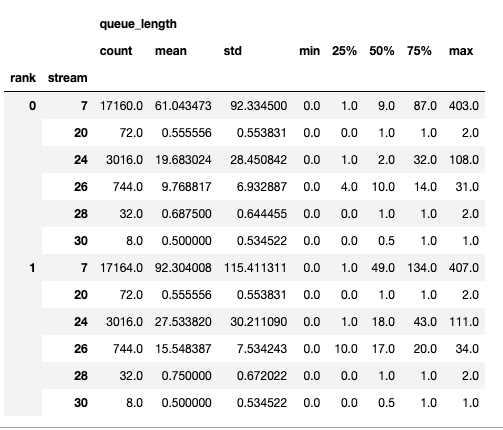
시계열은 값이 변경될 때만 포인트를 포함합니다. 일단 값이 관찰되면 다음 업데이트까지 시계열은 일정하게 유지됩니다. 메모리 대역폭 및 큐 길이 시계열 함수는 키가 랭크이고 값이 그 랭크에 대한 시계열인 딕셔너리를 반환합니다. 기본적으로, 시계열은 랭크 0에 대해서만 계산됩니다.
CUDA 커널 실행 통계#
GPU에서 실행된 각 이벤트에는 CudaLaunchKernel, CudaMemcpyAsync, `CudaMemsetAsync`와 같은 CPU에서의 대응하는 스케줄링 이벤트가 있습니다. 이러한 이벤트는 추적에서 공통의 상관 ID로 연결됩니다 - 위의 그림을 참조하세요. 이 기능은 CPU 런타임 이벤트의 지속 시간, 해당 GPU 커널 및 실행 지연을 계산합니다. 예를 들어, GPU 커널 시작과 CPU 오퍼레이터 종료 간의 차이입니다. 커널 실행 정보는 다음과 같이 생성할 수 있습니다:
analyzer = TraceAnalysis(trace_dir="/path/to/trace/dir")
kernel_info_df = analyzer.get_cuda_kernel_launch_stats()
생성된 데이터프레임의 스크린샷은 아래에 있습니다.
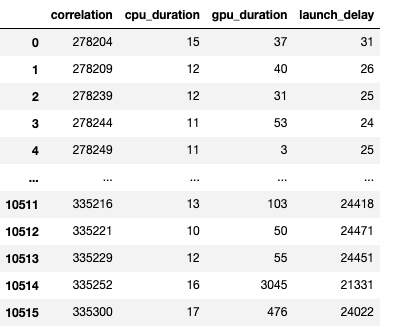
CPU 오퍼레이션의 지속 시간, GPU 커널, 그리고 실행 지연을 통해 다음을 찾을 수 있습니다:
짧은 GPU 커널 - GPU 커널의 지속 시간이 해당 CPU 런타임 이벤트보다 짧은 경우.
런타임 이벤트 이상치 - 과도한 지속 시간을 가진 CPU 런타임 이벤트.
실행 지연 이상치 - 스케줄되기까지 너무 오래 걸리는 GPU 커널.
HTA는 위에서 언급한 세 가지 카테고리 각각에 대한 분포 플롯을 생성합니다.
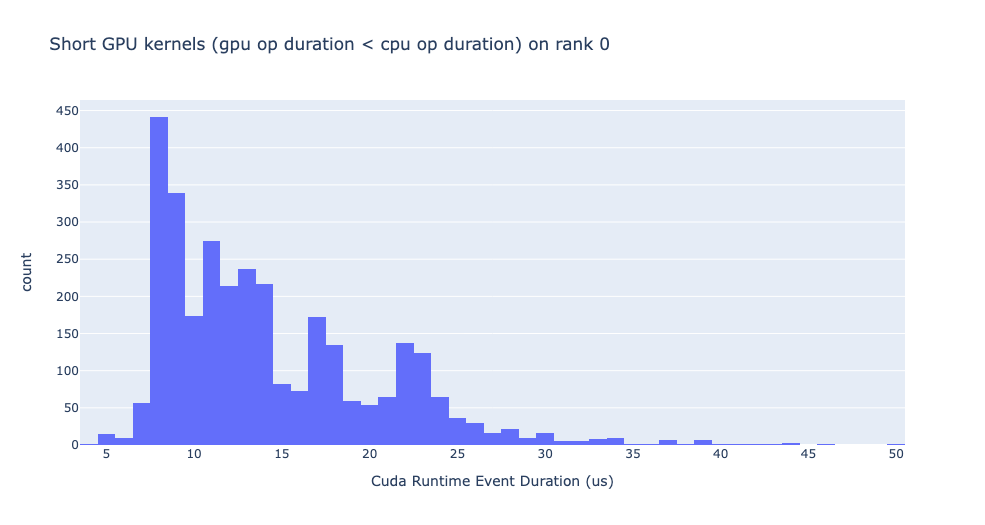
짧은 GPU 커널
일반적으로 CPU 측에서의 실행 시간은 5-20 마이크로초 범위입니다. 어떤 경우에는 GPU 실행 시간이 실행 시간보다 더 짧습니다. 아래 그래프는 이러한 사례가 코드에서 얼마나 자주 발생하는지 찾는 데 도움이 됩니다.
런타임 이벤트 이상치
런타임 이상치는 이상치를 분류하는 데 사용된 컷오프에 따라 다릅니다, 따라서 get_cuda_kernel_launch_stats API는 값을 구성하기 위한 runtime_cutoff 인수를 제공합니다.
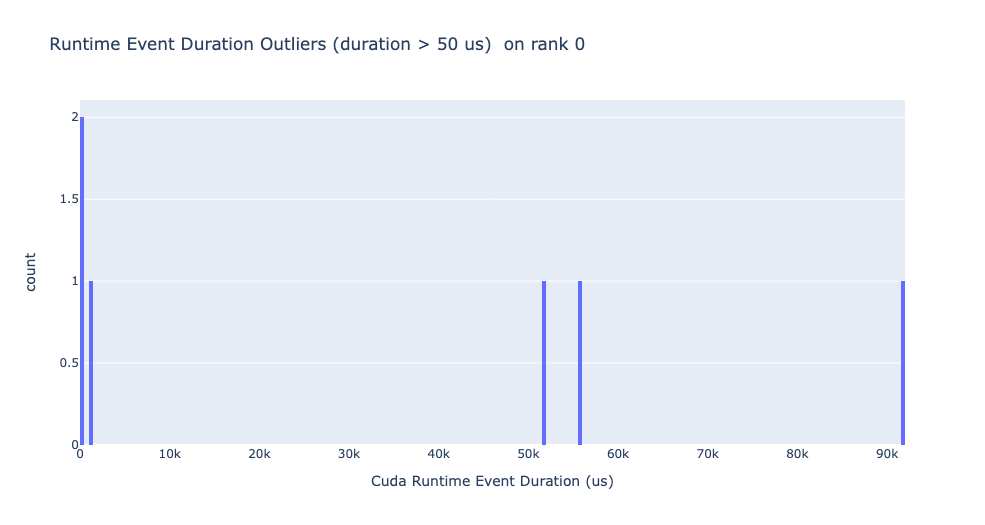
실행 지연 이상치
실행 지연 이상치는 이상치를 분류하는 데 사용된 컷오프에 따라 다릅니다, 따라서 get_cuda_kernel_launch_stats API는 값을 구성하기 위한 launch_delay_cutoff 인수를 제공합니다.
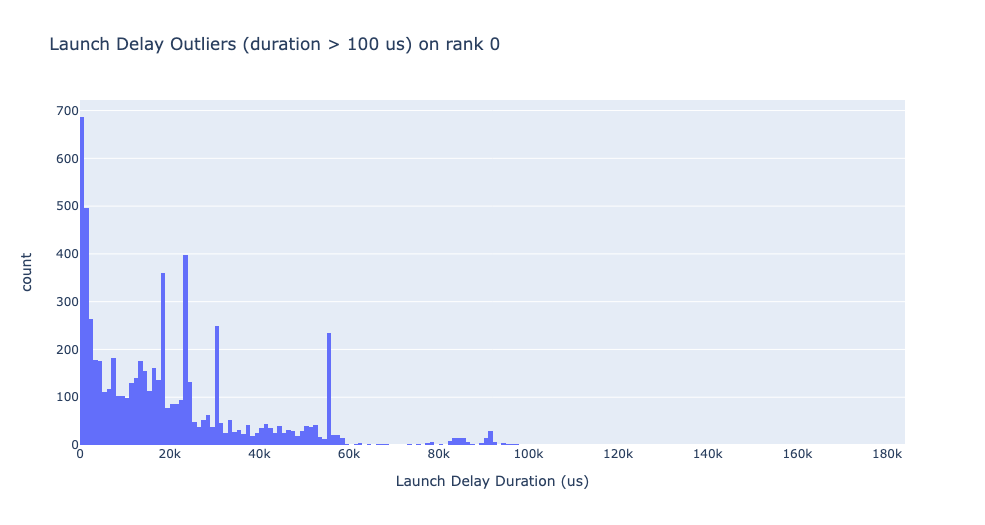
결론#
이 튜토리얼에서 HTA를 설치하고 사용하는 방법을 배웠습니다. HTA는 분산 학습 워크플로우에서 병목 현상을 분석할 수 있게 해주는 성능 도구입니다. HTA 도구를 사용하여 트레이스 비교 분석을 수행하는 방법에 대해 더 배우려면, Trace Diff using Holistic Trace Analysis 를 참조하세요.
