


Getting Started with DeviceMesh#
Author: Iris Zhang, Wanchao Liang
참고
 View and edit this tutorial in github.
View and edit this tutorial in github.
Prerequisites:
Python 3.8 - 3.11
PyTorch 2.2
Setting up distributed communicators, i.e. NVIDIA Collective Communication Library (NCCL) communicators, for distributed training can pose a significant challenge. For workloads where users need to compose different parallelisms,
users would need to manually set up and manage NCCL communicators (for example, ProcessGroup) for each parallelism solution. This process could be complicated and susceptible to errors.
DeviceMesh can simplify this process, making it more manageable and less prone to errors.
What is DeviceMesh#
DeviceMesh is a higher level abstraction that manages ProcessGroup. It allows users to effortlessly
create inter-node and intra-node process groups without worrying about how to set up ranks correctly for different sub process groups.
Users can also easily manage the underlying process_groups/devices for multi-dimensional parallelism via DeviceMesh.
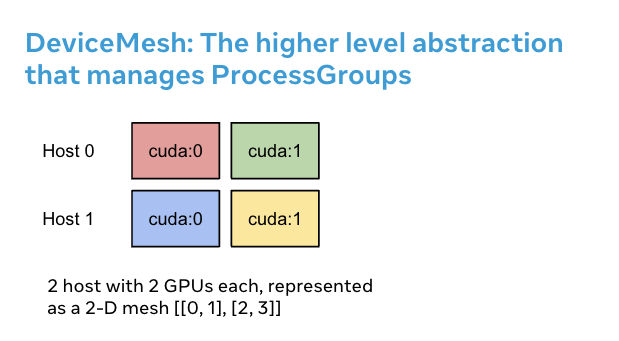
Why DeviceMesh is Useful#
DeviceMesh is useful when working with multi-dimensional parallelism (i.e. 3-D parallel) where parallelism composability is required. For example, when your parallelism solutions require both communication across hosts and within each host. The image above shows that we can create a 2D mesh that connects the devices within each host, and connects each device with its counterpart on the other hosts in a homogeneous setup.
Without DeviceMesh, users would need to manually set up NCCL communicators, cuda devices on each process before applying any parallelism, which could be quite complicated.
The following code snippet illustrates a hybrid sharding 2-D Parallel pattern setup without DeviceMesh.
First, we need to manually calculate the shard group and replicate group. Then, we need to assign the correct shard and
replicate group to each rank.
import os
import torch
import torch.distributed as dist
# Understand world topology
rank = int(os.environ["RANK"])
world_size = int(os.environ["WORLD_SIZE"])
print(f"Running example on {rank=} in a world with {world_size=}")
# Create process groups to manage 2-D like parallel pattern
dist.init_process_group("nccl")
torch.cuda.set_device(rank)
# Create shard groups (e.g. (0, 1, 2, 3), (4, 5, 6, 7))
# and assign the correct shard group to each rank
num_node_devices = torch.cuda.device_count()
shard_rank_lists = list(range(0, num_node_devices // 2)), list(range(num_node_devices // 2, num_node_devices))
shard_groups = (
dist.new_group(shard_rank_lists[0]),
dist.new_group(shard_rank_lists[1]),
)
current_shard_group = (
shard_groups[0] if rank in shard_rank_lists[0] else shard_groups[1]
)
# Create replicate groups (for example, (0, 4), (1, 5), (2, 6), (3, 7))
# and assign the correct replicate group to each rank
current_replicate_group = None
shard_factor = len(shard_rank_lists[0])
for i in range(num_node_devices // 2):
replicate_group_ranks = list(range(i, num_node_devices, shard_factor))
replicate_group = dist.new_group(replicate_group_ranks)
if rank in replicate_group_ranks:
current_replicate_group = replicate_group
To run the above code snippet, we can leverage PyTorch Elastic. Let’s create a file named 2d_setup.py.
Then, run the following torch elastic/torchrun command.
torchrun --nproc_per_node=8 --rdzv_id=100 --rdzv_endpoint=localhost:29400 2d_setup.py
참고
For simplicity of demonstration, we are simulating 2D parallel using only one node. Note that this code snippet can also be used when running on multi hosts setup.
With the help of init_device_mesh(), we can accomplish the above 2D setup in just two lines, and we can still
access the underlying ProcessGroup if needed.
from torch.distributed.device_mesh import init_device_mesh
mesh_2d = init_device_mesh("cuda", (2, 4), mesh_dim_names=("replicate", "shard"))
# Users can access the underlying process group thru `get_group` API.
replicate_group = mesh_2d.get_group(mesh_dim="replicate")
shard_group = mesh_2d.get_group(mesh_dim="shard")
Let’s create a file named 2d_setup_with_device_mesh.py.
Then, run the following torch elastic/torchrun command.
torchrun --nproc_per_node=8 2d_setup_with_device_mesh.py
How to use DeviceMesh with HSDP#
Hybrid Sharding Data Parallel(HSDP) is 2D strategy to perform FSDP within a host and DDP across hosts.
Let’s see an example of how DeviceMesh can assist with applying HSDP to your model with a simple setup. With DeviceMesh, users would not need to manually create and manage shard group and replicate group.
import torch
import torch.nn as nn
from torch.distributed.device_mesh import init_device_mesh
from torch.distributed.fsdp import fully_shard as FSDP
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
# HSDP: MeshShape(2, 4)
mesh_2d = init_device_mesh("cuda", (2, 4), mesh_dim_names=("dp_replicate", "dp_shard"))
model = FSDP(
ToyModel(), device_mesh=mesh_2d
)
Let’s create a file named hsdp.py.
Then, run the following torch elastic/torchrun command.
torchrun --nproc_per_node=8 hsdp.py
How to use DeviceMesh for your custom parallel solutions#
When working with large scale training, you might have more complex custom parallel training composition. For example, you may need to slice out sub-meshes for different parallelism solutions. DeviceMesh allows users to slice child mesh from the parent mesh and re-use the NCCL communicators already created when the parent mesh is initialized.
from torch.distributed.device_mesh import init_device_mesh
mesh_3d = init_device_mesh("cuda", (2, 2, 2), mesh_dim_names=("replicate", "shard", "tp"))
# Users can slice child meshes from the parent mesh.
hsdp_mesh = mesh_3d["replicate", "shard"]
tp_mesh = mesh_3d["tp"]
# Users can access the underlying process group thru `get_group` API.
replicate_group = hsdp_mesh["replicate"].get_group()
shard_group = hsdp_mesh["shard"].get_group()
tp_group = tp_mesh.get_group()
Conclusion#
In conclusion, we have learned about DeviceMesh and init_device_mesh(), as well as how
they can be used to describe the layout of devices across the cluster.
For more information, please see the following:
