


참고
Go to the end to download the full example code.
옵티마이저 단계를 backward pass에 합쳐서 메모리 절약하기#
번역: 하동훈
안녕하세요! 이 튜토리얼에서는 변화도(gradient) 가 차지하는 메모리를 줄임으로써 학습 루프(training loop)에서의 메모리 사용량을 줄이는 한 가지 방법을 소개합니다. 모델이 있는 상황에서 메모리 최적화를 통해 메모리 부족(Out of Memory, OOM) 오류를 방지하고 싶거나, GPU의 성능을 최대한 활용하고 싶은 경우 이 방법이 도움이 될 수 있습니다 (변화도가 메모리의 일부분을 차지하고 있으며, 변화도 누적(accumulation)이 필요하지 않은 경우라면 말입니다). 이 튜토리얼은 다음 내용을 다룹니다:
학습 또는 미세 조정(finetuning) 루프에서 메모리를 차지하는 요소,
병목 현상을 파악하기 위해 메모리 스냅샷(snapshot)을 캡처하고 시각화하는 방법,
새로운
Tensor.register_post_accumulate_grad_hook(hook)API,이 모든 것을 감안한 단 10줄의 코드로 메모리를 절약하는 방법.
이 튜토리얼을 실행하기 위해 필요한 것:
2.1.0 혹은 그 이상의 버전의 PyTorch와
torchvision메모리 시각화를 로컬에서 실행하려면, CUDA GPU 1개. 메모리 시각화를 제외하면 이 최적화 방법은 모든 장치에서 유사한 이점을 제공합니다.
먼저 필요한 모듈과 모델을 import 하겠습니다. 여기에서는 torchvision의 비전
트랜스포머 모델을 사용하지만, 다른 모델로 대체해도 좋습니다. 또 옵티마이저로
torch.optim.Adam 을 사용하지만, 마찬가지로 다른 옵티마이저로 대체해도
됩니다.
import torch
from torchvision import models
from pickle import dump
model = models.vit_l_16(weights='DEFAULT').cuda()
optimizer = torch.optim.Adam(model.parameters())
Downloading: "https://download.pytorch.org/models/vit_l_16-852ce7e3.pth" to /root/.cache/torch/hub/checkpoints/vit_l_16-852ce7e3.pth
0%| | 0.00/1.13G [00:00<?, ?B/s]
0%| | 128k/1.13G [00:00<1:23:49, 242kB/s]
0%| | 384k/1.13G [00:00<32:10, 630kB/s]
0%| | 640k/1.13G [00:00<22:48, 889kB/s]
0%| | 1.12M/1.13G [00:01<13:23, 1.51MB/s]
0%| | 2.25M/1.13G [00:01<06:37, 3.05MB/s]
0%| | 4.50M/1.13G [00:01<03:18, 6.10MB/s]
1%| | 8.38M/1.13G [00:01<01:49, 11.0MB/s]
1%| | 12.1M/1.13G [00:01<01:24, 14.2MB/s]
1%|▏ | 16.0M/1.13G [00:01<01:12, 16.6MB/s]
2%|▏ | 19.9M/1.13G [00:02<01:05, 18.3MB/s]
2%|▏ | 23.8M/1.13G [00:02<01:01, 19.3MB/s]
2%|▏ | 27.6M/1.13G [00:02<00:58, 20.2MB/s]
3%|▎ | 31.5M/1.13G [00:02<00:57, 20.8MB/s]
3%|▎ | 35.4M/1.13G [00:02<00:55, 21.2MB/s]
3%|▎ | 39.2M/1.13G [00:03<00:55, 21.4MB/s]
4%|▎ | 43.0M/1.13G [00:03<00:54, 21.4MB/s]
4%|▍ | 46.9M/1.13G [00:03<00:54, 21.6MB/s]
4%|▍ | 50.6M/1.13G [00:03<00:53, 21.6MB/s]
5%|▍ | 54.5M/1.13G [00:03<00:53, 21.7MB/s]
5%|▌ | 58.4M/1.13G [00:04<00:52, 21.9MB/s]
5%|▌ | 62.1M/1.13G [00:04<00:53, 21.7MB/s]
6%|▌ | 66.0M/1.13G [00:04<00:52, 21.8MB/s]
6%|▌ | 69.9M/1.13G [00:04<00:52, 21.9MB/s]
6%|▋ | 73.8M/1.13G [00:04<00:52, 21.9MB/s]
7%|▋ | 77.6M/1.13G [00:04<00:51, 22.0MB/s]
7%|▋ | 81.5M/1.13G [00:05<00:51, 21.9MB/s]
7%|▋ | 85.4M/1.13G [00:05<00:51, 22.0MB/s]
8%|▊ | 89.1M/1.13G [00:05<00:51, 21.8MB/s]
8%|▊ | 93.0M/1.13G [00:05<00:51, 21.9MB/s]
8%|▊ | 96.9M/1.13G [00:05<00:50, 22.0MB/s]
9%|▊ | 101M/1.13G [00:06<00:50, 21.8MB/s]
9%|▉ | 104M/1.13G [00:06<00:50, 21.9MB/s]
9%|▉ | 108M/1.13G [00:06<00:50, 21.9MB/s]
10%|▉ | 112M/1.13G [00:06<00:49, 22.0MB/s]
10%|▉ | 116M/1.13G [00:06<00:50, 21.7MB/s]
10%|█ | 120M/1.13G [00:06<00:49, 21.9MB/s]
11%|█ | 124M/1.13G [00:07<00:49, 22.0MB/s]
11%|█ | 128M/1.13G [00:07<00:49, 22.0MB/s]
11%|█▏ | 132M/1.13G [00:07<00:48, 22.1MB/s]
12%|█▏ | 135M/1.13G [00:07<00:48, 22.1MB/s]
12%|█▏ | 139M/1.13G [00:07<00:48, 21.9MB/s]
12%|█▏ | 143M/1.13G [00:08<00:48, 21.9MB/s]
13%|█▎ | 147M/1.13G [00:08<00:48, 21.8MB/s]
13%|█▎ | 151M/1.13G [00:08<00:48, 21.9MB/s]
13%|█▎ | 154M/1.13G [00:08<00:48, 21.9MB/s]
14%|█▎ | 158M/1.13G [00:08<00:49, 21.2MB/s]
14%|█▍ | 162M/1.13G [00:08<00:49, 21.3MB/s]
14%|█▍ | 166M/1.13G [00:09<00:48, 21.5MB/s]
15%|█▍ | 169M/1.13G [00:09<00:47, 21.7MB/s]
15%|█▍ | 173M/1.13G [00:09<00:47, 21.6MB/s]
15%|█▌ | 177M/1.13G [00:09<00:47, 21.7MB/s]
16%|█▌ | 181M/1.13G [00:09<00:47, 21.9MB/s]
16%|█▌ | 185M/1.13G [00:10<00:46, 21.9MB/s]
16%|█▌ | 188M/1.13G [00:10<00:46, 21.8MB/s]
17%|█▋ | 192M/1.13G [00:10<00:46, 21.9MB/s]
17%|█▋ | 196M/1.13G [00:10<00:46, 21.7MB/s]
17%|█▋ | 200M/1.13G [00:10<00:45, 22.0MB/s]
18%|█▊ | 204M/1.13G [00:11<00:46, 21.8MB/s]
18%|█▊ | 208M/1.13G [00:11<00:45, 21.9MB/s]
18%|█▊ | 212M/1.13G [00:11<00:45, 22.0MB/s]
19%|█▊ | 216M/1.13G [00:11<00:45, 21.9MB/s]
19%|█▉ | 219M/1.13G [00:11<00:44, 22.1MB/s]
19%|█▉ | 223M/1.13G [00:11<00:44, 22.1MB/s]
20%|█▉ | 227M/1.13G [00:12<00:44, 22.1MB/s]
20%|█▉ | 231M/1.13G [00:12<00:44, 21.9MB/s]
20%|██ | 235M/1.13G [00:12<00:44, 21.9MB/s]
21%|██ | 239M/1.13G [00:12<00:44, 21.9MB/s]
21%|██ | 242M/1.13G [00:12<00:43, 22.0MB/s]
21%|██ | 246M/1.13G [00:13<00:43, 22.0MB/s]
22%|██▏ | 250M/1.13G [00:13<00:43, 21.8MB/s]
22%|██▏ | 254M/1.13G [00:13<00:43, 21.9MB/s]
22%|██▏ | 258M/1.13G [00:13<00:43, 21.9MB/s]
23%|██▎ | 262M/1.13G [00:13<00:42, 22.0MB/s]
23%|██▎ | 266M/1.13G [00:13<00:42, 22.0MB/s]
23%|██▎ | 269M/1.13G [00:14<00:42, 21.9MB/s]
24%|██▎ | 273M/1.13G [00:14<00:42, 21.9MB/s]
24%|██▍ | 277M/1.13G [00:14<00:42, 21.9MB/s]
24%|██▍ | 281M/1.13G [00:14<00:42, 21.8MB/s]
25%|██▍ | 285M/1.13G [00:14<00:42, 21.9MB/s]
25%|██▍ | 289M/1.13G [00:15<00:41, 22.0MB/s]
25%|██▌ | 292M/1.13G [00:15<00:41, 22.0MB/s]
26%|██▌ | 296M/1.13G [00:15<00:41, 22.1MB/s]
26%|██▌ | 300M/1.13G [00:15<00:40, 22.1MB/s]
26%|██▌ | 304M/1.13G [00:15<00:41, 21.9MB/s]
27%|██▋ | 308M/1.13G [00:15<00:40, 22.0MB/s]
27%|██▋ | 312M/1.13G [00:16<00:40, 22.0MB/s]
27%|██▋ | 316M/1.13G [00:16<00:40, 22.0MB/s]
28%|██▊ | 319M/1.13G [00:16<00:40, 21.9MB/s]
28%|██▊ | 323M/1.13G [00:16<00:40, 21.9MB/s]
28%|██▊ | 327M/1.13G [00:16<00:39, 22.0MB/s]
29%|██▊ | 331M/1.13G [00:17<00:39, 22.0MB/s]
29%|██▉ | 335M/1.13G [00:17<00:39, 21.8MB/s]
29%|██▉ | 339M/1.13G [00:17<00:39, 21.9MB/s]
29%|██▉ | 342M/1.13G [00:17<00:39, 22.0MB/s]
30%|██▉ | 346M/1.13G [00:17<00:38, 22.0MB/s]
30%|███ | 350M/1.13G [00:17<00:38, 22.0MB/s]
31%|███ | 354M/1.13G [00:18<00:38, 22.1MB/s]
31%|███ | 358M/1.13G [00:18<00:38, 22.1MB/s]
31%|███ | 362M/1.13G [00:18<00:37, 22.1MB/s]
31%|███▏ | 366M/1.13G [00:18<00:38, 21.9MB/s]
32%|███▏ | 370M/1.13G [00:18<00:37, 22.0MB/s]
32%|███▏ | 373M/1.13G [00:19<00:37, 22.0MB/s]
32%|███▏ | 377M/1.13G [00:19<00:37, 22.0MB/s]
33%|███▎ | 381M/1.13G [00:19<00:37, 22.1MB/s]
33%|███▎ | 385M/1.13G [00:19<00:36, 22.1MB/s]
33%|███▎ | 389M/1.13G [00:19<00:36, 21.9MB/s]
34%|███▍ | 393M/1.13G [00:20<00:36, 22.0MB/s]
34%|███▍ | 396M/1.13G [00:20<00:36, 22.0MB/s]
34%|███▍ | 400M/1.13G [00:20<00:36, 22.0MB/s]
35%|███▍ | 404M/1.13G [00:20<00:36, 21.9MB/s]
35%|███▌ | 408M/1.13G [00:20<00:35, 22.1MB/s]
35%|███▌ | 412M/1.13G [00:20<00:35, 21.9MB/s]
36%|███▌ | 416M/1.13G [00:21<00:35, 22.0MB/s]
36%|███▌ | 420M/1.13G [00:21<00:35, 22.0MB/s]
36%|███▋ | 423M/1.13G [00:21<00:35, 21.8MB/s]
37%|███▋ | 427M/1.13G [00:21<00:35, 21.9MB/s]
37%|███▋ | 431M/1.13G [00:21<00:34, 22.0MB/s]
37%|███▋ | 435M/1.13G [00:22<00:34, 22.0MB/s]
38%|███▊ | 439M/1.13G [00:22<00:34, 22.0MB/s]
38%|███▊ | 443M/1.13G [00:22<00:34, 22.0MB/s]
38%|███▊ | 447M/1.13G [00:22<00:34, 21.9MB/s]
39%|███▉ | 450M/1.13G [00:22<00:34, 21.8MB/s]
39%|███▉ | 454M/1.13G [00:22<00:33, 21.9MB/s]
39%|███▉ | 458M/1.13G [00:23<00:33, 21.9MB/s]
40%|███▉ | 462M/1.13G [00:23<00:34, 21.6MB/s]
40%|████ | 466M/1.13G [00:23<00:33, 21.6MB/s]
40%|████ | 469M/1.13G [00:23<00:36, 20.1MB/s]
41%|████ | 472M/1.13G [00:23<00:34, 20.7MB/s]
41%|████ | 476M/1.13G [00:24<00:34, 21.1MB/s]
41%|████▏ | 480M/1.13G [00:24<00:33, 21.4MB/s]
42%|████▏ | 484M/1.13G [00:24<00:33, 21.4MB/s]
42%|████▏ | 488M/1.13G [00:24<00:32, 21.4MB/s]
42%|████▏ | 492M/1.13G [00:24<00:32, 21.6MB/s]
43%|████▎ | 496M/1.13G [00:24<00:32, 21.8MB/s]
43%|████▎ | 499M/1.13G [00:25<00:31, 21.8MB/s]
43%|████▎ | 503M/1.13G [00:25<00:32, 21.5MB/s]
44%|████▎ | 507M/1.13G [00:25<00:31, 21.6MB/s]
44%|████▍ | 511M/1.13G [00:25<00:31, 21.8MB/s]
44%|████▍ | 515M/1.13G [00:25<00:30, 21.9MB/s]
45%|████▍ | 519M/1.13G [00:26<00:30, 22.0MB/s]
45%|████▌ | 522M/1.13G [00:26<00:30, 22.0MB/s]
45%|████▌ | 526M/1.13G [00:26<00:30, 22.0MB/s]
46%|████▌ | 530M/1.13G [00:26<00:30, 22.0MB/s]
46%|████▌ | 534M/1.13G [00:26<00:29, 22.0MB/s]
46%|████▋ | 538M/1.13G [00:27<00:29, 22.0MB/s]
47%|████▋ | 542M/1.13G [00:27<00:29, 22.1MB/s]
47%|████▋ | 546M/1.13G [00:27<00:29, 22.1MB/s]
47%|████▋ | 550M/1.13G [00:27<00:29, 22.1MB/s]
48%|████▊ | 554M/1.13G [00:27<00:28, 22.1MB/s]
48%|████▊ | 557M/1.13G [00:27<00:28, 21.9MB/s]
48%|████▊ | 561M/1.13G [00:28<00:28, 21.9MB/s]
49%|████▊ | 565M/1.13G [00:28<00:28, 22.0MB/s]
49%|████▉ | 569M/1.13G [00:28<00:28, 22.0MB/s]
49%|████▉ | 573M/1.13G [00:28<00:27, 22.0MB/s]
50%|████▉ | 577M/1.13G [00:28<00:27, 22.1MB/s]
50%|████▉ | 580M/1.13G [00:29<00:27, 22.1MB/s]
50%|█████ | 584M/1.13G [00:29<00:27, 22.1MB/s]
51%|█████ | 588M/1.13G [00:29<00:27, 22.1MB/s]
51%|█████ | 592M/1.13G [00:29<00:26, 22.1MB/s]
51%|█████▏ | 596M/1.13G [00:29<00:26, 22.1MB/s]
52%|█████▏ | 600M/1.13G [00:29<00:26, 21.9MB/s]
52%|█████▏ | 604M/1.13G [00:30<00:26, 21.9MB/s]
52%|█████▏ | 608M/1.13G [00:30<00:26, 22.0MB/s]
53%|█████▎ | 611M/1.13G [00:30<00:26, 22.0MB/s]
53%|█████▎ | 615M/1.13G [00:30<00:25, 22.0MB/s]
53%|█████▎ | 619M/1.13G [00:30<00:25, 22.0MB/s]
54%|█████▎ | 623M/1.13G [00:31<00:25, 22.1MB/s]
54%|█████▍ | 627M/1.13G [00:31<00:25, 22.1MB/s]
54%|█████▍ | 631M/1.13G [00:31<00:25, 21.8MB/s]
55%|█████▍ | 634M/1.13G [00:31<00:25, 21.9MB/s]
55%|█████▍ | 638M/1.13G [00:31<00:24, 22.0MB/s]
55%|█████▌ | 642M/1.13G [00:31<00:24, 22.0MB/s]
56%|█████▌ | 644M/1.13G [00:34<02:06, 4.28MB/s]
56%|█████▌ | 646M/1.13G [00:34<01:52, 4.81MB/s]
56%|█████▌ | 649M/1.13G [00:34<01:25, 6.28MB/s]
56%|█████▋ | 653M/1.13G [00:34<01:03, 8.45MB/s]
57%|█████▋ | 657M/1.13G [00:35<00:49, 10.7MB/s]
57%|█████▋ | 661M/1.13G [00:35<00:41, 12.6MB/s]
57%|█████▋ | 665M/1.13G [00:35<00:34, 15.0MB/s]
58%|█████▊ | 669M/1.13G [00:35<00:31, 16.6MB/s]
58%|█████▊ | 672M/1.13G [00:35<00:28, 18.0MB/s]
58%|█████▊ | 676M/1.13G [00:35<00:26, 19.1MB/s]
59%|█████▊ | 680M/1.13G [00:36<00:25, 19.9MB/s]
59%|█████▉ | 684M/1.13G [00:36<00:24, 20.5MB/s]
59%|█████▉ | 688M/1.13G [00:36<00:23, 21.0MB/s]
60%|█████▉ | 692M/1.13G [00:36<00:23, 21.3MB/s]
60%|█████▉ | 696M/1.13G [00:36<00:22, 21.8MB/s]
60%|██████ | 700M/1.13G [00:37<00:22, 21.7MB/s]
61%|██████ | 704M/1.13G [00:37<00:22, 21.8MB/s]
61%|██████ | 707M/1.13G [00:37<00:21, 21.9MB/s]
61%|██████▏ | 711M/1.13G [00:37<00:21, 22.1MB/s]
62%|██████▏ | 715M/1.13G [00:37<00:20, 22.3MB/s]
62%|██████▏ | 719M/1.13G [00:37<00:20, 22.2MB/s]
62%|██████▏ | 722M/1.13G [00:38<00:21, 21.1MB/s]
63%|██████▎ | 726M/1.13G [00:38<00:21, 21.2MB/s]
63%|██████▎ | 730M/1.13G [00:38<00:21, 21.5MB/s]
63%|██████▎ | 734M/1.13G [00:38<00:20, 21.9MB/s]
64%|██████▎ | 738M/1.13G [00:38<00:20, 21.6MB/s]
64%|██████▍ | 742M/1.13G [00:39<00:20, 21.7MB/s]
64%|██████▍ | 746M/1.13G [00:39<00:19, 21.9MB/s]
65%|██████▍ | 750M/1.13G [00:39<00:19, 21.9MB/s]
65%|██████▍ | 754M/1.13G [00:39<00:19, 22.4MB/s]
65%|██████▌ | 758M/1.13G [00:39<00:19, 22.2MB/s]
65%|██████▌ | 760M/1.13G [00:39<00:20, 21.0MB/s]
66%|██████▌ | 762M/1.13G [00:40<00:20, 20.6MB/s]
66%|██████▌ | 765M/1.13G [00:40<00:17, 23.3MB/s]
66%|██████▋ | 769M/1.13G [00:40<00:17, 23.1MB/s]
67%|██████▋ | 773M/1.13G [00:40<00:17, 22.7MB/s]
67%|██████▋ | 777M/1.13G [00:40<00:17, 22.5MB/s]
67%|██████▋ | 781M/1.13G [00:40<00:17, 22.4MB/s]
68%|██████▊ | 785M/1.13G [00:41<00:17, 22.3MB/s]
68%|██████▊ | 789M/1.13G [00:41<00:17, 22.0MB/s]
68%|██████▊ | 792M/1.13G [00:41<00:17, 22.0MB/s]
69%|██████▊ | 796M/1.13G [00:41<00:17, 21.8MB/s]
69%|██████▉ | 800M/1.13G [00:41<00:17, 21.9MB/s]
69%|██████▉ | 804M/1.13G [00:42<00:16, 22.2MB/s]
70%|██████▉ | 808M/1.13G [00:42<00:16, 22.2MB/s]
70%|██████▉ | 812M/1.13G [00:42<00:16, 22.6MB/s]
70%|███████ | 816M/1.13G [00:42<00:16, 22.4MB/s]
71%|███████ | 820M/1.13G [00:42<00:15, 22.5MB/s]
71%|███████ | 824M/1.13G [00:42<00:15, 22.4MB/s]
71%|███████▏ | 828M/1.13G [00:43<00:15, 22.5MB/s]
72%|███████▏ | 832M/1.13G [00:43<00:15, 22.2MB/s]
72%|███████▏ | 836M/1.13G [00:43<00:15, 22.3MB/s]
72%|███████▏ | 840M/1.13G [00:43<00:15, 22.2MB/s]
73%|███████▎ | 843M/1.13G [00:43<00:14, 22.2MB/s]
73%|███████▎ | 847M/1.13G [00:44<00:14, 22.2MB/s]
73%|███████▎ | 851M/1.13G [00:44<00:14, 22.1MB/s]
74%|███████▎ | 855M/1.13G [00:44<00:14, 22.0MB/s]
74%|███████▍ | 859M/1.13G [00:44<00:14, 22.1MB/s]
74%|███████▍ | 863M/1.13G [00:44<00:14, 22.3MB/s]
75%|███████▍ | 867M/1.13G [00:44<00:13, 22.3MB/s]
75%|███████▍ | 871M/1.13G [00:45<00:13, 22.2MB/s]
75%|███████▌ | 874M/1.13G [00:45<00:13, 22.2MB/s]
76%|███████▌ | 878M/1.13G [00:45<00:13, 21.8MB/s]
76%|███████▌ | 882M/1.13G [00:45<00:13, 22.0MB/s]
76%|███████▋ | 886M/1.13G [00:45<00:13, 21.8MB/s]
77%|███████▋ | 889M/1.13G [00:46<00:14, 20.3MB/s]
77%|███████▋ | 893M/1.13G [00:46<00:12, 21.7MB/s]
77%|███████▋ | 897M/1.13G [00:46<00:12, 21.6MB/s]
78%|███████▊ | 901M/1.13G [00:46<00:12, 21.9MB/s]
78%|███████▊ | 905M/1.13G [00:46<00:12, 21.8MB/s]
78%|███████▊ | 909M/1.13G [00:46<00:11, 22.3MB/s]
79%|███████▊ | 913M/1.13G [00:47<00:11, 22.2MB/s]
79%|███████▉ | 917M/1.13G [00:47<00:11, 22.4MB/s]
79%|███████▉ | 920M/1.13G [00:47<00:11, 22.1MB/s]
80%|███████▉ | 924M/1.13G [00:47<00:11, 22.1MB/s]
80%|███████▉ | 928M/1.13G [00:47<00:11, 22.1MB/s]
80%|████████ | 932M/1.13G [00:48<00:10, 22.1MB/s]
81%|████████ | 936M/1.13G [00:48<00:10, 22.1MB/s]
81%|████████ | 940M/1.13G [00:48<00:10, 22.1MB/s]
81%|████████▏ | 944M/1.13G [00:48<00:10, 22.1MB/s]
82%|████████▏ | 948M/1.13G [00:48<00:10, 22.1MB/s]
82%|████████▏ | 952M/1.13G [00:49<00:09, 22.9MB/s]
82%|████████▏ | 956M/1.13G [00:49<00:09, 23.1MB/s]
83%|████████▎ | 960M/1.13G [00:49<00:09, 22.6MB/s]
83%|████████▎ | 964M/1.13G [00:49<00:09, 22.5MB/s]
83%|████████▎ | 968M/1.13G [00:49<00:09, 22.3MB/s]
84%|████████▎ | 971M/1.13G [00:49<00:08, 22.3MB/s]
84%|████████▍ | 975M/1.13G [00:50<00:08, 22.1MB/s]
84%|████████▍ | 979M/1.13G [00:50<00:08, 22.3MB/s]
85%|████████▍ | 983M/1.13G [00:50<00:08, 22.0MB/s]
85%|████████▍ | 987M/1.13G [00:50<00:08, 22.0MB/s]
85%|████████▌ | 991M/1.13G [00:50<00:08, 22.0MB/s]
86%|████████▌ | 995M/1.13G [00:51<00:07, 22.3MB/s]
86%|████████▌ | 998M/1.13G [00:51<00:07, 22.2MB/s]
86%|████████▋ | 0.98G/1.13G [00:51<00:07, 21.1MB/s]
87%|████████▋ | 0.98G/1.13G [00:51<00:07, 21.4MB/s]
87%|████████▋ | 0.99G/1.13G [00:51<00:07, 20.8MB/s]
87%|████████▋ | 0.99G/1.13G [00:51<00:07, 21.2MB/s]
88%|████████▊ | 0.99G/1.13G [00:52<00:06, 22.5MB/s]
88%|████████▊ | 1.00G/1.13G [00:52<00:06, 22.3MB/s]
88%|████████▊ | 1.00G/1.13G [00:52<00:06, 22.4MB/s]
89%|████████▊ | 1.01G/1.13G [00:52<00:06, 22.4MB/s]
89%|████████▉ | 1.01G/1.13G [00:52<00:06, 22.3MB/s]
89%|████████▉ | 1.01G/1.13G [00:53<00:05, 22.0MB/s]
90%|████████▉ | 1.02G/1.13G [00:53<00:05, 22.0MB/s]
90%|████████▉ | 1.02G/1.13G [00:53<00:05, 22.2MB/s]
90%|█████████ | 1.02G/1.13G [00:53<00:05, 22.5MB/s]
91%|█████████ | 1.03G/1.13G [00:53<00:05, 22.5MB/s]
91%|█████████ | 1.03G/1.13G [00:53<00:04, 22.6MB/s]
91%|█████████▏| 1.04G/1.13G [00:54<00:04, 22.7MB/s]
92%|█████████▏| 1.04G/1.13G [00:54<00:04, 22.8MB/s]
92%|█████████▏| 1.04G/1.13G [00:54<00:04, 22.4MB/s]
92%|█████████▏| 1.05G/1.13G [00:54<00:04, 22.3MB/s]
93%|█████████▎| 1.05G/1.13G [00:54<00:03, 22.3MB/s]
93%|█████████▎| 1.06G/1.13G [00:55<00:03, 22.6MB/s]
93%|█████████▎| 1.06G/1.13G [00:55<00:03, 22.6MB/s]
94%|█████████▎| 1.06G/1.13G [00:55<00:03, 22.7MB/s]
94%|█████████▍| 1.07G/1.13G [00:55<00:03, 22.3MB/s]
94%|█████████▍| 1.07G/1.13G [00:55<00:03, 22.0MB/s]
95%|█████████▍| 1.07G/1.13G [00:55<00:02, 22.1MB/s]
95%|█████████▌| 1.08G/1.13G [00:56<00:02, 22.0MB/s]
95%|█████████▌| 1.08G/1.13G [00:56<00:02, 22.1MB/s]
96%|█████████▌| 1.09G/1.13G [00:56<00:02, 22.1MB/s]
96%|█████████▌| 1.09G/1.13G [00:56<00:02, 22.1MB/s]
96%|█████████▋| 1.09G/1.13G [00:56<00:02, 20.0MB/s]
97%|█████████▋| 1.10G/1.13G [00:57<00:02, 20.4MB/s]
97%|█████████▋| 1.10G/1.13G [00:57<00:01, 21.1MB/s]
97%|█████████▋| 1.10G/1.13G [00:57<00:01, 21.4MB/s]
98%|█████████▊| 1.11G/1.13G [00:57<00:01, 21.4MB/s]
98%|█████████▊| 1.11G/1.13G [00:58<00:02, 12.7MB/s]
98%|█████████▊| 1.11G/1.13G [00:58<00:01, 13.8MB/s]
98%|█████████▊| 1.12G/1.13G [00:58<00:01, 15.7MB/s]
99%|█████████▊| 1.12G/1.13G [00:58<00:00, 17.3MB/s]
99%|█████████▉| 1.12G/1.13G [00:58<00:00, 18.5MB/s]
99%|█████████▉| 1.13G/1.13G [00:59<00:00, 19.2MB/s]
100%|█████████▉| 1.13G/1.13G [00:59<00:00, 20.0MB/s]
100%|█████████▉| 1.13G/1.13G [00:59<00:00, 20.4MB/s]
100%|██████████| 1.13G/1.13G [00:59<00:00, 20.5MB/s]
이제 일반적인 학습 루프를 정의해봅시다. 실제 학습 시에는 진짜 이미지를 사용해야 하지만, 이 튜토리얼에서는 가짜 입력 데이터를 사용하며 실제 데이터를 읽어들이는 것에 대해서는 신경 쓰지 않을 것입니다.
IMAGE_SIZE = 224
def train(model, optimizer):
# 가짜 이미지 입력값 생성: tensor의 형태는 batch_size, channels, height, width
fake_image = torch.rand(1, 3, IMAGE_SIZE, IMAGE_SIZE).cuda()
# forward와 backward 호출
loss = model.forward(fake_image)
loss.sum().backward()
# 옵티마이저 업데이트
optimizer.step()
optimizer.zero_grad()
학습 중의 메모리 사용량#
이제 메모리 스냅샷을 확인하려고 하므로, 이를 적절히 분석할 준비를 해야 합니다. 일반적으로 학습 메모리는 다음으로 구성됩니다:
모델 매개변수 (크기 P)
backward pass를 위해 저장된 활성화 값(activations) (크기 A)
변화도, 모델 매개변수와 같은 크기이므로 크기 G = P.
옵티마이저 상태, 매개변수 크기에 비례합니다. 예시의 경우, Adam의 상태는 모델 매개변수의 2배가 필요하므로 크기 O = 2P.
중간 단계(Intermediate) tensor, 계산 도중 할당됩니다. 보통 크기가 작고 일시적이므로 지금은 신경 쓰지 않겠습니다.
메모리 스냅샷 캡처 및 시각화#
이제 메모리 스냅샷을 가져와 봅시다! 코드가 실행되는 동안, CUDA 메모리 타임라인이 어떤 모습일지 한 번 예상해 보세요.
# CUDA에 메모리 할당 기록을 시작하도록 지시
torch.cuda.memory._record_memory_history(enabled='all')
# 학습 3회 실시
for _ in range(3):
train(model, optimizer)
# 메모리 할당 스냅샷을 저장
s = torch.cuda.memory._snapshot()
with open(f"snapshot.pickle", "wb") as f:
dump(s, f)
# CUDA에 메모리 할당 기록을 중지하도록 지시
torch.cuda.memory._record_memory_history(enabled=None)
이제 CUDA 메모리 시각화 도구(CUDA Memory Visualizer)에서 스냅샷을 열어보세요.
https://pytorch.org/memory_viz 로 들어가서 snapshot.pickle 파일을 드래그 앤
드롭하여 업로드할 수 있습니다. 메모리 타임라인이 예상과 일치하나요?
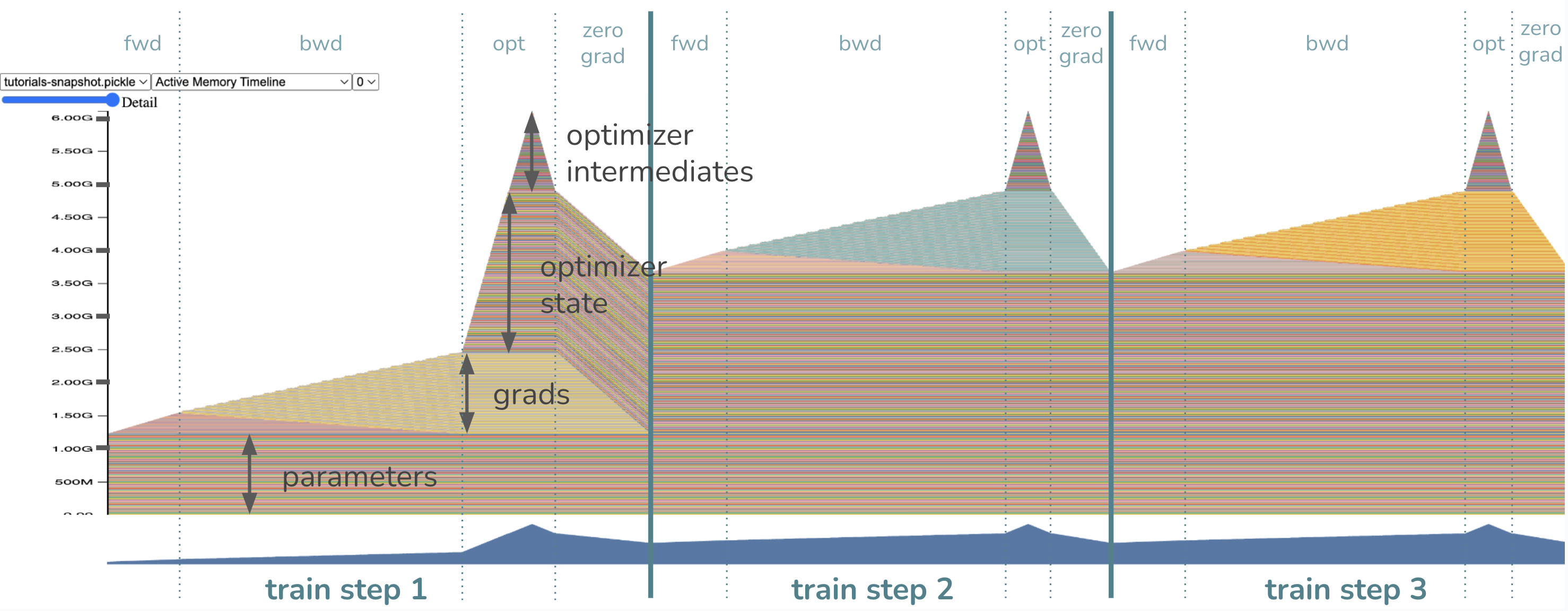
모델 매개변수는 이미 학습 루프 이전에 메모리에 로드되었으므로, 처음부터 가중치(weights)에 할당된 메모리 덩어리가 보입니다. forward pass를 시작하면, 메모리는 활성화 값을 위해 점차 할당됩니다. 이 활성화 값은 backward pass에서 변화도를 계산하기 위해 저장하는 tensor입니다. backward pass를 시작하면, 활성화 값이 점차 해제되면서 변화도가 차지하는 메모리가 쌓이기 시작합니다.
마지막으로 옵티마이저가 작동하면, 옵티마이저의 상태는 지연(lazily) 초기화되므로,
첫 번째 학습 루프의 옵티마이저 단계 동안만 옵티마이저 상태 메모리가 점차
증가하는 것을 볼 수 있습니다. 이후의 루프에서는, 옵티마이저 메모리가 그대로
유지되고, 제자리에서 업데이트됩니다. 변화도가 차지하는 메모리는 매번 학습 루프가
끝날 때에 맞춰 zero_grad 가 호출되면 해제됩니다.
이 학습 루프에서 메모리 병목 현상이 발생하는 지점은 어디일까요? 즉, 메모리 사용이 가장 높은 지점은 어디일까요?
메모리 사용량이 가장 높은 지점은 옵티마이저 단계입니다! 이때의 메모리를 보면 예상대로
~1.2GB 의 매개변수, ~1.2GB의 변화도, 그리고 ~2.4GB=2*1.2GB 의 옵티마이저 상태로
구성됩니다. 마지막 ~1.2GB는 Adam 옵티마이저가 중간 단계에 필요로 하는 메모리로,
합쳐서 총 ~6GB에 달합니다.
사실, Adam(model.parameters(), foreach=False) 로 설정하면 옵티마이저 중간
메모리인 마지막 1.2GB를 제거할 수 있는데, 이는 메모리 대신 실행 시간을 희생하는
방식입니다. 만약 이 foreach 최적화만으로도 충분히 필요한만큼 메모리가
절약되었다면 잘된 일이지만,
더 나은 방법에 대해 알고 싶다면 이 튜토리얼을 계속 읽어보세요!
이제 곧 소개할 방법을 사용한다면, ~1.2GB의 변화도 메모리 와 옵티마이저 중간
단계 메모리 가 필요 없게 되어 최대 메모리 사용량을 낮출 수 있습니다.
그렇다면, 새로운 최대 메모리 사용량은 얼마가 될까요?
정답은 다음 스냅샷에서 공개됩니다.
주의 사항: 이 방법은 모든 경우에 적합한 것은 아님#
잠시 진정하고, 먼저 이 방법이 당신 의 사용 사례에 적합한지 고려해야 합니다. 이 방법은 결코 만능 해결책이 아닙니다! 옵티마이저 단계를 backward 과정에 합치는 이 방법은 변화도 메모리의 감소만을 목표로 합니다 (그리고 부수적으로 옵티마이저 중간 단계 메모리도 줄입니다). 따라서 변화도가 차지하는 메모리가 클수록, 메모리 절약 효과가 더욱 커집니다. 위의 예시에서 변화도는 메모리 총량의 20%를 차지하는데, 이는 꽤나 큰 비율이죠!
그러나 때에 따라 이러한 상황에 해당하지 않을 수 있습니다. 예를 들어, 이미 가중치가 매우 작다면 (LoRa 적용 등의 이유로), 변화도가 학습 루프에서 공간을 많이 차지하지 않을 것이고, 그렇다면 이 방법의 이점이 그다지 크지 않을 수 있습니다. 이런 경우에는 먼저 활성화 값 체크포인팅, 분산 학습, 양자화, 배치 크기 축소와 같은 다른 기술을 시도해 보세요. 그런 다음, 변화도가 다시 병목의 일부가 될 때 이 튜토리얼로 돌아오세요!
아직 여기에 계신가요? 좋습니다, 이제 Tensor의 새로운 register_post_accumulate_grad_hook(hook)
API를 소개하겠습니다.
Tensor.register_post_accumulate_grad_hook(hook) API와 우리가 사용할 방법#
이 방법은 backward() 동안 변화도를 저장하지 않아도 된다는 점에 의존합니다.
대신, 기울기가 누적되면 즉시 해당 매개변수에 대해 옵티마이저를 적용하고, 해당
변화도를 완전히 제거합니다! 이렇게 하면 옵티마이저 단계를 위해 큰 변화도 버퍼를
유지할 필요가 없어집니다.
그렇다면 옵티마이저를 더 즉시(eagerly) 적용하는 동작을 어떻게 하면 활성화할 수 있을까요? 2.1
버전에서 새로 추가된 API인 torch.Tensor.register_post_accumulate_grad_hook()
을 사용하면, Tensor의 .grad 필드(field)가 누적된 후에 훅(hook)을 추가할 수 있습니다.
우리는 이 훅에 옵티마이저 단계를 캡슐화(encapsulate)할 것입니다. 어떻게요?
이 모든 것을 단 10줄의 코드로 통합하는 방법#
초반에 사용했던 모델과 옵티마이저 설정을 기억하시나요? 코드 재실행에 리소스를 낭비하지 않도록 아래에 주석으로 남겨두겠습니다.
model = models.vit_l_16(weights='DEFAULT').cuda()
optimizer = torch.optim.Adam(model.parameters())
# *단일* 옵티마이저 대신, 각 매개변수마다 하나씩 옵티마이저를 만들고 ``딕셔너리``
# 하나에 저장하여 훅에서 참조할 수 있도록 하겠습니다.
optimizer_dict = {p: torch.optim.Adam([p], foreach=False) for p in model.parameters()}
# 옵티마이저의 ``step()`` 및 ``zero_grad()`` 를 호출할 훅을 정의합니다.
def optimizer_hook(parameter) -> None:
optimizer_dict[parameter].step()
optimizer_dict[parameter].zero_grad()
# 모든 매개변수에 훅을 등록합니다.
for p in model.parameters():
p.register_post_accumulate_grad_hook(optimizer_hook)
# 이전의 ``train()`` 함수 기억하시나요? 옵티마이저가 backward에 합쳐졌으므로,
# 옵티마이저의 step 및 zero_grad 호출을 제거할 수 있습니다.
def train(model):
# 가짜 이미지 입력값 생성: tensor의 형태는 batch_size, channels, height, width
fake_image = torch.rand(1, 3, IMAGE_SIZE, IMAGE_SIZE).cuda()
# forward와 backward 호출
loss = model.forward(fake_image)
loss.sum().backward()
# 옵티마이저 업데이트 --> 이제 필요 없습니다!
# optimizer.step()
# optimizer.zero_grad()
샘플 모델에서는 약 10줄의 코드 변경으로 끝났습니다. 깔끔하네요.
하지만 실제 모델에서는 옵티마이저를 옵티마이저 딕셔너리로 교체하는 것이
꽤나 거슬리는 변경이 될 수 있습니다.
특히 LRScheduler 를 사용하거나 학습 에폭 동안 옵티마이저 구성을
조작하는 경우에는 더욱 그렇습니다.
그러한 상황에서 이 API를 사용하려면 더 복잡할 것이고, 더 많은 구성 요소를
전역(global) 상태로 이동시켜야 할 수도 있지만, 불가능하지는 않을 것입니다.
그렇긴 하지만, 조만간 PyTorch가 이 API를 LRScheduler나 기존의 다른
기능들과 더 쉽게 통합할 수 있도록 이 API를 개선하길 바라 봅니다.
다시 돌아와서, 이 방법이 써볼 만한 가치가 있다는 설득을 이어 나가 보겠습니다. 우리의 친구, 메모리 스냅샷을 살펴보겠습니다.
# 이전의 옵티마이저 메모리를 삭제하여 다음 메모리 스냅샷을 위한 깨끗한 상태를
# 만듭니다.
del optimizer
# CUDA에 메모리 할당 기록을 시작하도록 지시
torch.cuda.memory._record_memory_history(enabled='all')
# 학습 3회 실시. 이제 더 이상 train() 함수에 옵티마이저를 전달하지 않는다는 점에 유의하세요.
for _ in range(3):
train(model)
# 메모리 할당 스냅샷을 저장
s = torch.cuda.memory._snapshot()
with open(f"snapshot-opt-in-bwd.pickle", "wb") as f:
dump(s, f)
# CUDA에 메모리 할당 기록을 중지하도록 지시
torch.cuda.memory._record_memory_history(enabled=None)
좋아요, CUDA Memory Visualizer에 스냅샷을 드래그 앤 드롭해 봅시다.
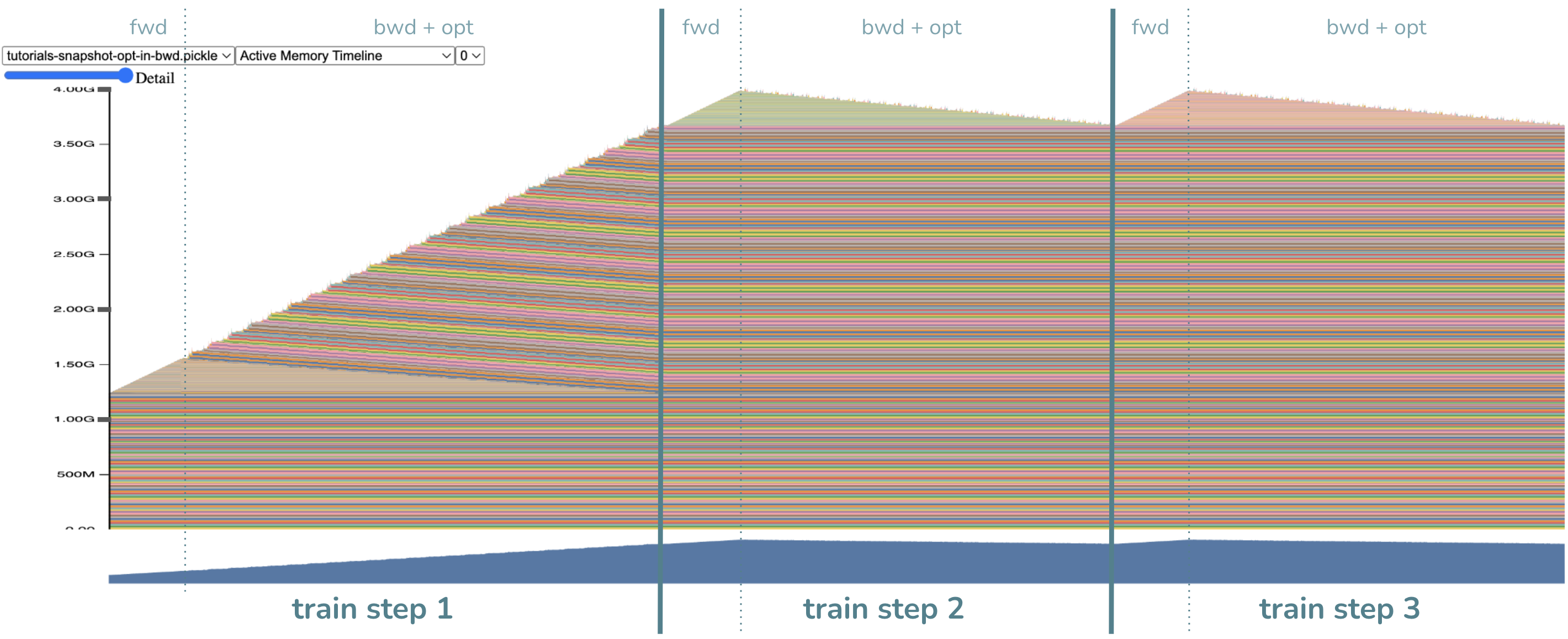
- 몇 가지 주요 관찰 사항:
더 이상 옵티마이저 단계가 없습니다! 맞아요… backward 과정에 합쳐졌죠.
마찬가지로, backward 과정이 더 길어지고 중간 단계를 위한 임시 메모리 할당이 더 많아졌습니다. 이는 예상된 결과인데, 옵티마이저 단계가 중간 단계를 필요로 하기 때문입니다.
가장 중요한 점! 최대 메모리 사용량이 낮아졌습니다! 이제 ~4GB 정도입니다 (예상하셨던 수치와 얼추 비슷하길 바랍니다).
더 이상 변화도를 위해 할당된 큰 메모리 덩어리가 없다는 점에 주목하세요.
이에 따라 이전과 비교해 보았을 때 ~1.2GB 의 메모리 절약이 이루어졌습니다. 대신,
변화도가 계산되자마자 매우 빠르게 해제되었는데, 이는 가능한 한 옵티마이저 단계를
앞당겼기 때문입니다. 야호! 참고로, 나머지 ~1.2GB 의 메모리 절약은 옵티마이저를
매개변수별 옵티마이저로 나누면서 중간 단계의 메모리 사용량이 줄어든 덕분입니다.
하지만 이것은 기울기 메모리 절약보다는 덜 중요한 부분인데, 왜냐하면 중간 단계의
메모리 절약은 이 기술 없이도 foreach=False 옵션을 수정해 주는 것만으로
달성할 수 있기 때문입니다.
이런 의문이 생길 수 있습니다: 2.4GB의 메모리가 절약되었다면, 왜 최대 메모리 사용량이 6GB - 2.4GB = 3.6GB가 아닌가요? 아, 그건 최대 메모리 사용량의 시점이 바뀌었기 때문입니다! 최대 메모리 사용량은 이제 backward 과정의 시작 부분으로 이동했습니다. 이제는 이 시점에 메모리에 활성화 값이 남아있으며, 이전에는 옵티마이저 단계에서 활성화 값이 해제된 후 최대 메모리 사용량이 발생했습니다. ~4.0GB와 ~3.6GB 간의 ~0.4GB의 차이는 바로 이 활성화 값의 메모리 때문입니다. 따라서 이 기술을 활성화 값 체크포인팅과 함께 사용하면 더 큰 메모리 절약을 이룰 수 있을 것입니다.
결론#
이번 튜토리얼에서는 새로운 Tensor.register_post_accumulate_grad_hook()
API를 사용하여 옵티마이저를 backward 단계에 합치는 메모리 절약 기술과 이를 언제
적용해야 하는지(변화도 메모리 양이 상당한 경우)에 대해 배웠습니다. 또한 메모리
최적화에 일반적으로 유용한 메모리 스냅샷에 대해서도 학습했습니다.
Total running time of the script: (1 minutes 44.579 seconds)
