importtorchimporttorch.nnasnnimporttorch.nn.functionalasFclassMNISTConvNet(nn.Module):def__init__(self):# 여기에 모든 모듈을 생성해두고,# 나중에 여기에서 선언해둔 이름으로 사용할 수 있습니다.super(MNISTConvNet,self).__init__()self.conv1=nn.Conv2d(1,10,5)self.pool1=nn.MaxPool2d(2,2)self.conv2=nn.Conv2d(10,20,5)self.pool2=nn.MaxPool2d(2,2)self.fc1=nn.Linear(320,50)self.fc2=nn.Linear(50,10)# 순전파 함수에서는 신경망의 구조를 정의합니다.# 여기에서는 단 하나의 입력만 받지만, 필요하면 더 받도록 변경하면 됩니다.defforward(self,input):x=self.pool1(F.relu(self.conv1(input)))x=self.pool2(F.relu(self.conv2(x)))# 모델 구조를 정의할 때는 어떤 Python 코드를 사용해도 괜찮습니다.# 모든 코드는 autograd에 의해 올바르고 완벽하게 처리될 것입니다.# if x.gt(0) > x.numel() / 2:# ...## 심지어 반복문을 만들고 그 안에서 동일한 모듈을 재사용해도 됩니다.# 모듈은 더 이상 일시적인 상태를 갖고 있지 않으므로,# 순전파 단계에서 여러 번 사용해도 괜찮습니다.# while x.norm(2) < 10:# x = self.conv1(x)x=x.view(x.size(0),-1)x=F.relu(self.fc1(x))x=F.relu(self.fc2(x))returnx
지금까지 가중치와 변화도에 대해서 살펴봤습니다. 그렇다면 계층의 출력이나
grad_output 을 살펴보거나 수정하려면 어떻게 해야 할까요?
이런 목적으로 사용할 수 있는 훅(Hook) 을 소개합니다.
Module 이나 Tensor 에 함수를 등록할 수 있습니다.
훅은 순전파 훅과 역전파 훅이 있는데, 순전파 훅은 순전파가 일어날 때,
역전파 훅은 역전파가 일어날 때 실행됩니다.
예제를 살펴보겠습니다.
conv2에 순전파 훅을 등록하고 몇 가지 정보를 출력해보겠습니다.
defprintnorm(self,input,output):# input is a tuple of packed inputs# output is a Tensor. output.data is the Tensor we are interestedprint('Inside '+self.__class__.__name__+' forward')print('')print('input: ',type(input))print('input[0]: ',type(input[0]))print('output: ',type(output))print('')print('input size:',input[0].size())print('output size:',output.data.size())print('output norm:',output.data.norm())net.conv2.register_forward_hook(printnorm)out=net(input)
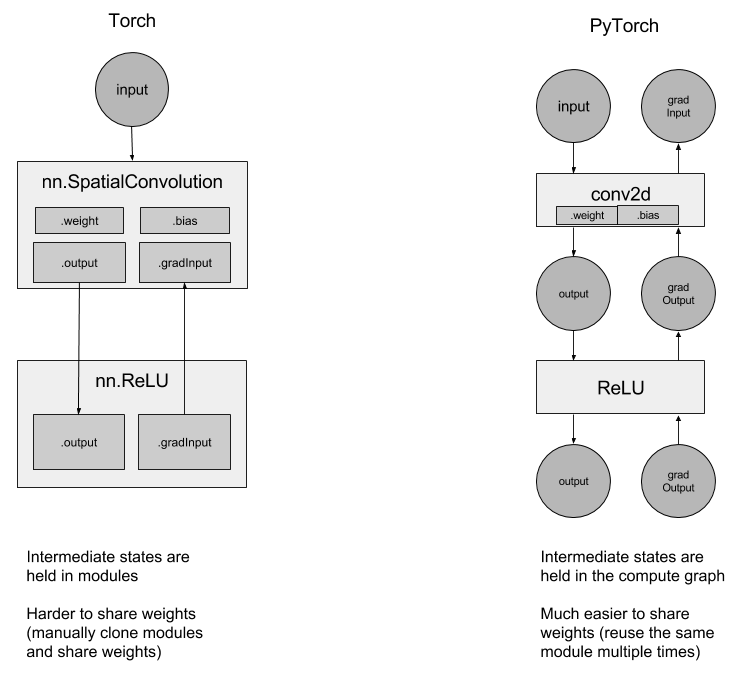
신경망의 상태는 각 계층이 아닌 그래프에 저장되므로, 간단히 nn.Linear을
생성한 후 순환할 때마다 계속해서 재사용하면 됩니다.
classRNN(nn.Module):# you can also accept arguments in your model constructordef__init__(self,data_size,hidden_size,output_size):super(RNN,self).__init__()self.hidden_size=hidden_sizeinput_size=data_size+hidden_sizeself.i2h=nn.Linear(input_size,hidden_size)self.h2o=nn.Linear(hidden_size,output_size)defforward(self,data,last_hidden):input=torch.cat((data,last_hidden),1)hidden=self.i2h(input)output=self.h2o(hidden)returnhidden,outputrnn=RNN(50,20,10)
LSTM과 Penn Tree-bank를 사용한 좀 더 완벽한 언어 모델링 예제는
여기
에 있습니다.
PyTorch는 합성곱 신경망과 순환 신경망에 CuDNN 연동을 기본적으로 지원하고 있습니다.
loss_fn=nn.MSELoss()batch_size=10TIMESTEPS=5# Create some fake databatch=torch.randn(batch_size,50)hidden=torch.zeros(batch_size,20)target=torch.zeros(batch_size,10)loss=0fortinrange(TIMESTEPS):# yes! you can reuse the same network several times,# sum up the losses, and call backward!hidden,output=rnn(batch,hidden)loss+=loss_fn(output,target)loss.backward()
Total running time of the script: (0 minutes 4.124 seconds)
To analyze traffic and optimize your experience, we serve cookies on this site. By clicking or navigating, you agree to allow our usage of cookies. As the current maintainers of this site, Facebook’s Cookies Policy applies. Learn more, including about available controls: Cookies Policy.