


참고
Go to the end to download the full example code.
Torchvision 모델의 미세 조정(Finetuning)#
Author: Nathan Inkawhich 번역: 송채영
이 튜토리얼에서는 1000개의 클래스의 ImageNet 데이터셋에서 사전 학습된 torchvision 모델, 을 미세 조정하고 특징을 추출하는 방법에 대해 자세히 살펴보겠습니다. 여러 최신 CNN 아키텍처로 작업하는 방법을 심도 있게 살펴보고, PyTorch 모델을 미세 조정할 수 있는 직관력을 키울 것입니다. 각 모델의 아키텍처가 다르기 때문에 모든 시나리오에서 작동하는 상용구 형식의 미세 조정 코드는 없습니다. 오히려, 연구자가 기존의 아키텍처를 살펴보고 각 모델에 맞게 커스텀 조정을 해야합니다.
#
# 이 문서에서는 두 가지 유형의 전이 학습을 수행합니다. 미세 조정과 특징 추출입니다.
# **미세 조정** 에서는, 사전 학습된 모델로 시작해
# 새로운 작업을 위해 모델의 매개변수 *모두* 를 업데이트 하여 본질적으로 전체 모델을 재학습합니다.
# **특징 추출**에서는, 사전 학습된 모델로 시작해
# 예측을 도출하는 최종 레이어의 가중치만 업데이트합니다.
# 사전 학습된 CNN을 고정된 특징 추출기(feature-extractor)로 사용하고
# 출력 레이어만 변경하기 때문에 이를 특징 추출이라고 합니다.
# 전송(transfer)에 대한 자세한 기술 정보는
# `여기 <https://cs231n.github.io/transfer-learning/>`__ 와
# `여기 <https://ruder.io/transfer-learning/>`__ 를 재구성합니다.
#
# 일반적으로 두 전이 학습 방법 모두 몇 가지 단계를 동일하게 따릅니다.
#
# - 사전 훈련된 모델을 초기화합니다.
# - 최종 레이어를 재구성하여 새 데이터 집합의 클래스 수와 동일한 수의 출력을 갖도록 합니다.
# - 새 데이터셋의 클래스 수와 동일한 출력 수를 갖도록 최종 레이어를 재구성합니다.
# - 훈련 중에 업데이트할 매개변수를 최적화 알고리즘에 맞게 정의합니다.
# - 학습 단계를 실행합니다.
#
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
print("PyTorch Version: ",torch.__version__)
print("Torchvision Version: ",torchvision.__version__)
PyTorch Version: 2.8.0+cu128
Torchvision Version: 0.23.0+cu128
입력#
실행을 위해 변경할 모든 매개변수는 다음과 같습니다.
hymenoptera_data 데이터셋을 여기 에서
다운받아 사용하겠습니다. 이 데이터셋에는
벌 과 개미 라는 두 개의 클래스가 포함되어 있으며
사용자 정의 데이터셋을 직접 작성하지 않고
ImageFolder
데이터셋을 사용할 수 있도록 구조화되어 있습니다.
데이터를 다운로드하고 data_dir 입력을 데이터셋의 루트(root) 디렉토리로 설정합니다.
model_name 입력은 사용하려는 모델의 이름이며
아래의 목록에서 선택해야 합니다.
[resnet, alexnet, vgg, squeezenet, densenet, inception]
다른 입력은 다음과 같습니다. num_classes 은 데이터셋의 클래스 수,
batch_size 는 훈련에 사용되는 배치 크기로
모델의 성능에 따라 조정할 수 있으며,
num_epochs 는 실행하려는 훈련 에폭 수,
feature_extract 는 미세 조정 또는 특징 추출 여부를 정의하는 부울(boolean)입니다.
``feature_extract = False``이면 모델이 미세 조정되고
모든 모델의 매개변수가 업데이트됩니다.
``feature_extract = True``인 경우 마지막 레이어의 매개변수만 업데이트되고
다른 매개변수는 고정된 상태로 유지됩니다.
# 최상위 데이터 디렉토리입니다. 여기서는 디렉토리 형식이
# ImageFolder 구조를 따른다고 가정합니다.
data_dir = "./data/hymenoptera_data"
# [resnet, alexnet, vgg, squeezenet, densenet, inception] 이 중 모델을 선택합니다.
model_name = "squeezenet"
# 데이터 집합의 클래스 수
num_classes = 2
# 훈련을 위한 배치 크기 (메모리 용량에 따라 변경됩니다.)
batch_size = 8
# 훈련할 에폭 수
num_epochs = 15
# 특징 추출을 위한 플래그(flag)입니다. False일 경우, 전체 모델을 미세 조정하고
# True일 경우 재형성된 레이어어의 매개변수만 업데이트합니다.
feature_extract = True
도우미 함수(Helper Functions)#
모델을 조정하는 코드를 작성하기 전에 몇 가지 도우미 함수(Helper Functions)를 정의해 보겠습니다.
모델 훈련 및 검증 코드#
train_model 함수는 주어진 모델의 학습과 검증을 처리합니다.
이 함수는 PyTorch 모델, 데이터로더(dataloader) 딕셔너리, 손실 함수,
옵티마이저, 훈련 및 검증을 위해 정해진 에폭 수,
그리고 Inception 모델일 때를 나타내는 부울 플래그(boolean flag)를 입력으로 받습니다.
이 아키텍처는 보조(auxiliary) 출력을 사용하고, 전체 모델 손실은
여기 에 설명된 대로
보조(auxiliary) 출력과 최종 출력을 모두 존중하므로
is_inception 플래그(flag)는 Inception v3 모델을 수용하는 데 사용됩니다.
이 함수는 지정된 에폭 수 동안 학습하고
각 에폭이 끝난 후 전체 검증 단계를 실행합니다.
또한, 검증 정확도 측면에서 가장 성능이 좋은 모델을 추적하고
학습이 끝나면 해당 모델을 반환합니다.
각 에폭이 끝나면 훈련 및 검증 정확도를 볼 수 있습니다.
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 각 에폭은 학습 단계와 검증 단계를 갖습니다.
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 학습 모드로 모델 설정
else:
model.eval() # 평가 모드로 모델 설정
running_loss = 0.0
running_corrects = 0
# 데이터를 반복
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 매개변수 경사도를 0으로 설정
optimizer.zero_grad()
# 순방향
# 훈련 하는 동안만 기록을 추적합니다.
with torch.set_grad_enabled(phase == 'train'):
# 모델의 출력을 가져오고 손실을 계산합니다.
# 학습 시 보조(auxiliary) 출력이 있는 inception의 특별한 경우입니다.
# 학습 모드에서는 최종 출력과 보조(auxiliary) 출력을 합산해 손실을 계산하지만
# 테스트에서는 최종 출력만 고려합니다.
if is_inception and phase == 'train':
# https://discuss.pytorch.org/t/how-to-optimize-inception-model-with-auxiliary-classifiers/7958 에서
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# 학습 단계인 경우 역전파 + 최적화
if phase == 'train':
loss.backward()
optimizer.step()
# 통계
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 모델을 깊은 복사(deep copy)함
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'val':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 최고의 모델 가중치 불러오기
model.load_state_dict(best_model_wts)
return model, val_acc_history
모델 매개변수의 .requires_grad 속성 설정#
이 도우미 함수(Helper Functions)는 특징 추출 시
모델에 있는 매개변수의 .requires_grad 속성을 False로 설정합니다.
기본적으로, 사전 학습된 모델을 읽어 들일 때 모든 매개변수가
``.requires_grad=True``로 설정되어 있으므로
처음부터 학습하거나 미세 조정하는 경우라면 괜찮습니다.
그러나 특징 추출 중이고 새로 초기화된 레이어에 대한 경사도만 계산하려는 경우
다른 모든 매개변수에는 경사도가 필요하지 않아야 합니다.
이것은 나중에 더 이해를 할 수 있을 것입니다.
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
네트워크 초기화 및 재구성하기#
이제 가장 흥미로운 부분입니다. 여기서는 각 네트워크의 재구성을 처리합니다. 이 절차는 자동 절차가 아니며 각 모델마다 고유합니다. CNN 모델의 최종 레이어(FC layer라고도 불림)는 데이터셋의 출력 클래스 수와 동일한 수의 노드를 가지고 있습니다. 모든 모델은 이미 ImageNet에서 사전 학습 되었기 때문에 각 클래스당 하나의 노드씩 1000 크기의 출력 레이어를 가지고 있습니다. 여기서의 목표는 이전과 동일한 수의 입력을 갖고, 데이터셋의 클래스 수와 동일한 수의 출력을 갖도록 마지막 레이어를 재구성하는 것입니다. 다음 섹션에서는 각 모델의 아키텍처를 개별적으로 변경하는 방법에 대해 설명하겠습니다. 하지만 먼저, 미세 조정과 특징 추출의 차이점에 대한 한 가지 중요한 세부 사항이 있습니다.
특징 추출 시 마지막 레이어의 매개변수만 업데이트 하고 싶을 때 다시 말해, 재구성하는 레이어의 매개변수만 업데이트를 하고 싶은 경우가 있습니다. 이런 경우에는 변경하지 않는 매개변수의 경사도를 계산할 필요가 없으므로 효율성을 위해 .requires_grad 속성을 False로 설정합니다. 기본적으로 이 속성은 True로 설정되어 있기 때문에 이 설정은 중요합니다. 그런 다음 새 레이어를 초기화할 때 기본적으로 새 매개변수에는 ``.requires_grad=True``가 있으므로 새 레이어의 매개변수만 업데이트됩니다. 미세 조정할 때는 모든 .requires_grad를 기본값인 True로 설정할 수 있습니다.
마지막으로, inception_v3는 입력 크기를 (299,299)로 요구하지만, 다른 모든 모델은 (224,224)를 기대한다는 점을 기억하세요.
Resnet#
Resnet은 ‘Deep Residual Learning for Image Recognition <https://arxiv.org/abs/1512.03385>`__ 논문에서 소개되었습니다. Resnet18, Resnet34, Resnet50, Resnet101, and Resnet152 등 다양한 크기의 여러 가지 변형이 있으며 모두 torchvision 모델에서 사용할 수 있습니다. 여기서는 데이터셋이 작고 클래스가 두 개 뿐인 Resnet18을 사용합니다. 모델을 출력하면 아래 그림과 같이 마지막 레이어가 완전히 연결된 레이어임을 알 수 있습니다.
(fc): Linear(in_features=512, out_features=1000, bias=True)
입력 특징이 512개, 출력 특징이 2개인 선형 레이어가 되도록 ``model.fc``를 다시 초기화해야 합니다.
model.fc = nn.Linear(512, num_classes)
Alexnet#
Alexnet은 ImageNet Classification with Deep Convolutional Neural Networks 논문에 소개된 바 있으며 ImageNet 데이터셋에서 최초로 매우 성공적인 CNN을 구현한 바 있습니다. 모델의 아키텍처를 출력하면 모델 출력이 분류기(classifier)의 6번째 레이어에서 나오는 것을 볼 수 있습니다.
(classifier): Sequential(
...
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
데이터셋과 함께 모델을 사용하려면 이 레이어를 다음과 같이 다시 초기화합니다.
model.classifier[6] = nn.Linear(4096,num_classes)
VGG#
VGG는 Very Deep Convolutional Networks for Large-Scale Image Recognition 논문에서 소개되었습니다. Torchvision 다양한 길이와 배치 정규화 레이어가 있는 8가지 버전의 VGG를 제공합니다. 여기서는 배치 정규화 기능이 있는 VGG-11을 사용합니다. 출력 레이어는 Alexnet과 유사합니다.
(classifier): Sequential(
...
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
따라서 동일한 기술을 사용해 출력 레이어를 수정합니다.
model.classifier[6] = nn.Linear(4096,num_classes)
Squeezenet#
Squeeznet 아키텍처는 SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size 논문에 설명되어 있고, AlexNet 수준의 정확도를 제공하면서 여기에 표시된 모델들과는 다른 출력 구조를 사용합니다. Torchvision에는 두 가지 버전의 Squeezenet이 있고 여기서는 1.0 버전을 사용합니다. 출력은 분류기(classifier)의 첫 번째 레이어인 1x1 합성곱 레이어에서 나옵니다.
(classifier): Sequential(
(0): Dropout(p=0.5)
(1): Conv2d(512, 1000, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace)
(3): AvgPool2d(kernel_size=13, stride=1, padding=0)
)
네트워크를 수정하기 위해 Conv2d 레이어를 다시 초기화하여 깊이 2의 특징 맵을 다음과 같이 출력합니다.
model.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
Densenet#
Densenet Densely Connected Convolutional Networks 논문에서 소개되었습니다. Torchvision에는 4가지의 변형 Densenet이 있지만 여기서는 Densenet-121만 사용합니다. 출력 레이는 1024개의 입력 특징을 가진 선형 레이어 입니다.
(classifier): Linear(in_features=1024, out_features=1000, bias=True)
네트워크를 재구성하기 위해 분류기(classifier)의 선형 레이어를 다음과 같이 다시 초기화합니다.
model.classifier = nn.Linear(1024, num_classes)
Inception v3#
마지막으로 Inception v3은 Rethinking the Inception Architecture for Computer Vision 에서 처음 설명했습니다. 이 네트워크는 학습 시 두 개의 출력 레이어가 있다는 점이 독특합니다. 두 번째 출력은 보조(axuiliary) 출력으로 알려져 있으며 네트워크의 AuxLogits 부분에 포함되어 있습니다. 기본 출력은 네트워크 끝에 있는 선형 레이어이며 테스트할 때는 기본 출력만 고려합니다. 읽어 들인 모델의 보조(auxiliary) 출력과 기본 출력은 다음과 같이 출력됩니다.
(AuxLogits): InceptionAux(
...
(fc): Linear(in_features=768, out_features=1000, bias=True)
)
...
(fc): Linear(in_features=2048, out_features=1000, bias=True)
이 모델을 미세 조정하려면 두 레이어를 다음과 같이 모두 재구성해야 합니다.
model.AuxLogits.fc = nn.Linear(768, num_classes)
model.fc = nn.Linear(2048, num_classes)
많은 모델이 비슷한 출력 구조를 가지고 있지만, 각각은 약간 다르게 처리되어야 합니다. 또한, 재구성된 네트워크의 출력 모델 구조를 확인하고 출력 기능의 수가 데이터셋의 클래스 수와 동일한지 확인해야 합니다.
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# 이 if 문에서 설정할 변수를 초기화 합니다.
# 각 변수는 모델에 따라 다릅니다.
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# 보조 네트워크(auxilary net) 처리
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# 주 네트워크(primary net) 처리
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
# 실행을 위한 모델 초기화
model_ft, input_size = initialize_model(model_name, num_classes, feature_extract, use_pretrained=True)
# 방금 인스턴스화한 모델 출력
print(model_ft)
/opt/conda/lib/python3.11/site-packages/torchvision/models/_utils.py:208: UserWarning:
The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
/opt/conda/lib/python3.11/site-packages/torchvision/models/_utils.py:223: UserWarning:
Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=SqueezeNet1_0_Weights.IMAGENET1K_V1`. You can also use `weights=SqueezeNet1_0_Weights.DEFAULT` to get the most up-to-date weights.
Downloading: "https://download.pytorch.org/models/squeezenet1_0-b66bff10.pth" to /root/.cache/torch/hub/checkpoints/squeezenet1_0-b66bff10.pth
0%| | 0.00/4.78M [00:00<?, ?B/s]
100%|██████████| 4.78M/4.78M [00:00<00:00, 79.8MB/s]
SqueezeNet(
(features): Sequential(
(0): Conv2d(3, 96, kernel_size=(7, 7), stride=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(3): Fire(
(squeeze): Conv2d(96, 16, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(16, 64, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(16, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(4): Fire(
(squeeze): Conv2d(128, 16, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(16, 64, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(16, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(5): Fire(
(squeeze): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(6): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(7): Fire(
(squeeze): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(8): Fire(
(squeeze): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(48, 192, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(48, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(9): Fire(
(squeeze): Conv2d(384, 48, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(48, 192, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(48, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(10): Fire(
(squeeze): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(11): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(12): Fire(
(squeeze): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
)
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Conv2d(512, 2, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace=True)
(3): AdaptiveAvgPool2d(output_size=(1, 1))
)
)
데이터 읽어 들이기#
입력 크기를 알았으니 이제 데이터 전이(transform), 이미지 데이터셋, 그리고 데이터로더(dataloader)를 초기화할 수 있습니다. 여기 에서 설명된 대로 모델은 하드코딩(hard-coded)된 정규화 값으로 사전 학습되었습니다.
# 학습을 위한 데이터 증강 및 정규화
# 검증을 위한 정규화만 수행
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
print("Initializing Datasets and Dataloaders...")
# 학습 및 검증 데이터셋 생성
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
# 학습 및 검증 데이터로더(dataloader) 생성
dataloaders_dict = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=4) for x in ['train', 'val']}
# 사용 가능한 GPU 탐지
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
Initializing Datasets and Dataloaders...
옵티마이저 생성#
이제 모델 구조가 정확해졌으니, 미세 조정 및 특징 추출을 위한 마지막 단계는
원하는 매개변수만 업데이트하는 옵티마이저를 생성하는 것입니다.
사전 학습된 모델을 읽어 들인 후 구조를 재조정하기 전에
feature_extract=True``인 경우 매개변수의
모든 ``.requires_grad 속성을 일일이 False로 설정한 것을 기억하세요.
그러면 재초기화된 레이어의 파라미터는
기본적으로 ``.requires_grad=True``를 갖습니다.
이제 .requires_grad=True인 모든 매개변수가
최적화되어야 한다는 것을 알았습니다.
다음으로 이러한 매개변수 목록을 만들고
이 목록을 SGD 알고리즘 생성자(constructor)에 입력합니다.
이를 확인하려면 출력된 매개변수를 확인하여 학습하세요. 미세 조정할 때 이 목록은 길어야 하며 모든 모델의 매개변수를 포함해야 합니다. 하지만, 특징을 추출할 때는 이 목록이 짧아야 하며 재구성된 레이어의 가중치와 편향(bias)만 포함해야 합니다.
# GPU로 모델 전송
model_ft = model_ft.to(device)
# 이 실행에서 최적화/업데이트할 매개변수를 수집합니다.
# 미세 조정을 하는 경우 모든 매개변수를 업데이트합니다.
# 하지만, 특징 추출 방법을 사용하는 경우에는
# 방금 초기화한 매개변수, 즉 requires_grad가 Ture인 매개변수만 업데이트합니다.
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
# 모든 매개변수가 최적화되고 있는지 확인합니다.
optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
Params to learn:
classifier.1.weight
classifier.1.bias
학습 및 검증 단계 실행#
마지막 단계는 모델에 대한 손실을 설정한 다음 설정된 에폭 수에 대해 학습 및 검증 함수(validation function)를 실행하는 것입니다. 이 단계는 에폭 수에 따라 CPU에서는 시간이 걸릴 수 있습니다. 또한, 기본 학습률은 모든 모델에 최적이 아니므로 최대 정확도를 얻으려면 각 모델에 대해 개별적으로 조정해야 합니다.
# 손실 함수 설정
criterion = nn.CrossEntropyLoss()
# 학습 및 평가
model_ft, hist = train_model(model_ft, dataloaders_dict, criterion, optimizer_ft, num_epochs=num_epochs, is_inception=(model_name=="inception"))
Epoch 0/14
----------
train Loss: 0.5197 Acc: 0.7377
val Loss: 0.3218 Acc: 0.8889
Epoch 1/14
----------
train Loss: 0.3047 Acc: 0.8852
val Loss: 0.2838 Acc: 0.8954
Epoch 2/14
----------
train Loss: 0.2320 Acc: 0.8893
val Loss: 0.2880 Acc: 0.9150
Epoch 3/14
----------
train Loss: 0.2131 Acc: 0.9262
val Loss: 0.2946 Acc: 0.9216
Epoch 4/14
----------
train Loss: 0.1815 Acc: 0.9262
val Loss: 0.3670 Acc: 0.9150
Epoch 5/14
----------
train Loss: 0.1677 Acc: 0.9221
val Loss: 0.3186 Acc: 0.9216
Epoch 6/14
----------
train Loss: 0.1863 Acc: 0.9262
val Loss: 0.3685 Acc: 0.8954
Epoch 7/14
----------
train Loss: 0.1349 Acc: 0.9385
val Loss: 0.3709 Acc: 0.9020
Epoch 8/14
----------
train Loss: 0.1751 Acc: 0.9098
val Loss: 0.5201 Acc: 0.8497
Epoch 9/14
----------
train Loss: 0.2799 Acc: 0.8730
val Loss: 0.3116 Acc: 0.9150
Epoch 10/14
----------
train Loss: 0.1438 Acc: 0.9549
val Loss: 0.3341 Acc: 0.9281
Epoch 11/14
----------
train Loss: 0.1545 Acc: 0.9303
val Loss: 0.3258 Acc: 0.9085
Epoch 12/14
----------
train Loss: 0.1401 Acc: 0.9344
val Loss: 0.3512 Acc: 0.9020
Epoch 13/14
----------
train Loss: 0.1455 Acc: 0.9303
val Loss: 0.3301 Acc: 0.9216
Epoch 14/14
----------
train Loss: 0.1322 Acc: 0.9426
val Loss: 0.3269 Acc: 0.9346
Training complete in 0m 11s
Best val Acc: 0.934641
처음부터 학습된 모델과의 비교#
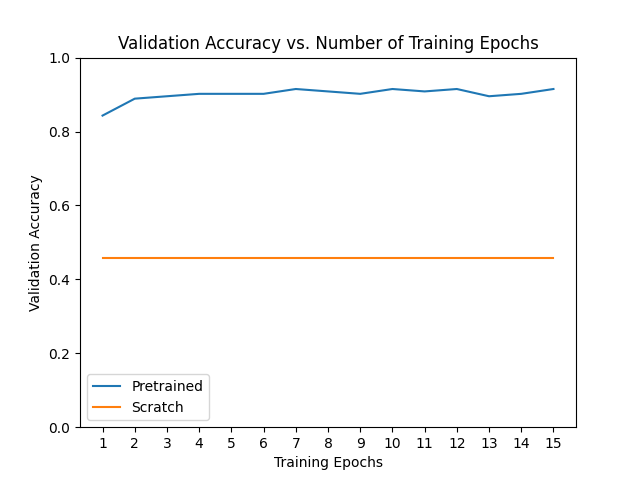
재미로, 전이 학습을 사용하지 않을 경우 모델이 어떻게 학습하는지 살펴봅시다. 미세 조정과 특징 추출의 성능은 데이터셋에 따라 크게 다르지만 일반적으로 두 전이 학습 방법은 처음부터 학습한 모델에 비해 학습 시간 및 전반적인 정확도 측면에서 유리한 결과를 제공합니다.
# 이 실행에 사용된 모델의 사전 학습되지 않은 버전을 초기화합니다.
scratch_model,_ = initialize_model(model_name, num_classes, feature_extract=False, use_pretrained=False)
scratch_model = scratch_model.to(device)
scratch_optimizer = optim.SGD(scratch_model.parameters(), lr=0.001, momentum=0.9)
scratch_criterion = nn.CrossEntropyLoss()
_,scratch_hist = train_model(scratch_model, dataloaders_dict, scratch_criterion, scratch_optimizer, num_epochs=num_epochs, is_inception=(model_name=="inception"))
# 전이 학습 방법과 처음부터 학습된 모델에 대한
# 검증 정확도 vs. 학습 에폭 수에 대한 학습 곡선을 표시합니다.
ohist = []
shist = []
ohist = [h.cpu().numpy() for h in hist]
shist = [h.cpu().numpy() for h in scratch_hist]
plt.title("Validation Accuracy vs. Number of Training Epochs")
plt.xlabel("Training Epochs")
plt.ylabel("Validation Accuracy")
plt.plot(range(1,num_epochs+1),ohist,label="Pretrained")
plt.plot(range(1,num_epochs+1),shist,label="Scratch")
plt.ylim((0,1.))
plt.xticks(np.arange(1, num_epochs+1, 1.0))
plt.legend()
plt.show()
/opt/conda/lib/python3.11/site-packages/torchvision/models/_utils.py:223: UserWarning:
Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
Epoch 0/14
----------
train Loss: 0.7011 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 1/14
----------
train Loss: 0.6936 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 2/14
----------
train Loss: 0.6951 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 3/14
----------
train Loss: 0.6930 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 4/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 5/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 6/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 7/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 8/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 9/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 10/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 11/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 12/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 13/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Epoch 14/14
----------
train Loss: 0.6931 Acc: 0.5041
val Loss: 0.6931 Acc: 0.4575
Training complete in 0m 13s
Best val Acc: 0.457516
최종 생각과 앞으로의 방향#
다른 모델 몇 가지를 실행해보고 정확도가 얼마나 좋아지는지 확인해 보세요. 또한, 역방향 패스에서는 대부분의 변화도를 계산할 필요가 없기 때문에 특징 추출에 시간이 덜 걸린다는 점에 주목하세요. 여기에서 할 수 있는 것은 많으며 다음과 같이 할 수 있습니다.
더 어려운 데이터 집합으로 이 코드를 실행하고 전이 학습의 몇 가지 이점을 더 확인해 보세요.
여기에 설명된 방법을 사용하거나 전이 학습을 사용하여 새로운 domain(예: NLP, 오디오 등)에서 다른 모델을 업데이트합니다.
모델이 만족하면 ONNX 모델로 내보내거나 하이브리드 프론트엔드를 사용해 더 빠른 속도와 최적화 기회를 얻을 수 있습니다.
Total running time of the script: (0 minutes 28.330 seconds)
