


참고
Go to the end to download the full example code.
Semi-Supervised Learning using USB built upon PyTorch#
Author: Hao Chen
Unified Semi-supervised learning Benchmark (USB) is a semi-supervised
learning (SSL) framework built upon PyTorch.
Based on Datasets and Modules provided by PyTorch, USB becomes a flexible,
modular, and easy-to-use framework for semi-supervised learning.
It supports a variety of semi-supervised learning algorithms, including
FixMatch, FreeMatch, DeFixMatch, SoftMatch, and so on.
It also supports a variety of imbalanced semi-supervised learning algorithms.
The benchmark results across different datasets of computer vision, natural
language processing, and speech processing are included in USB.
This tutorial will walk you through the basics of using the USB lighting
package.
Let’s get started by training a FreeMatch/SoftMatch model on
CIFAR-10 using pretrained Vision Transformers (ViT)!
And we will show it is easy to change the semi-supervised algorithm and train
on imbalanced datasets.
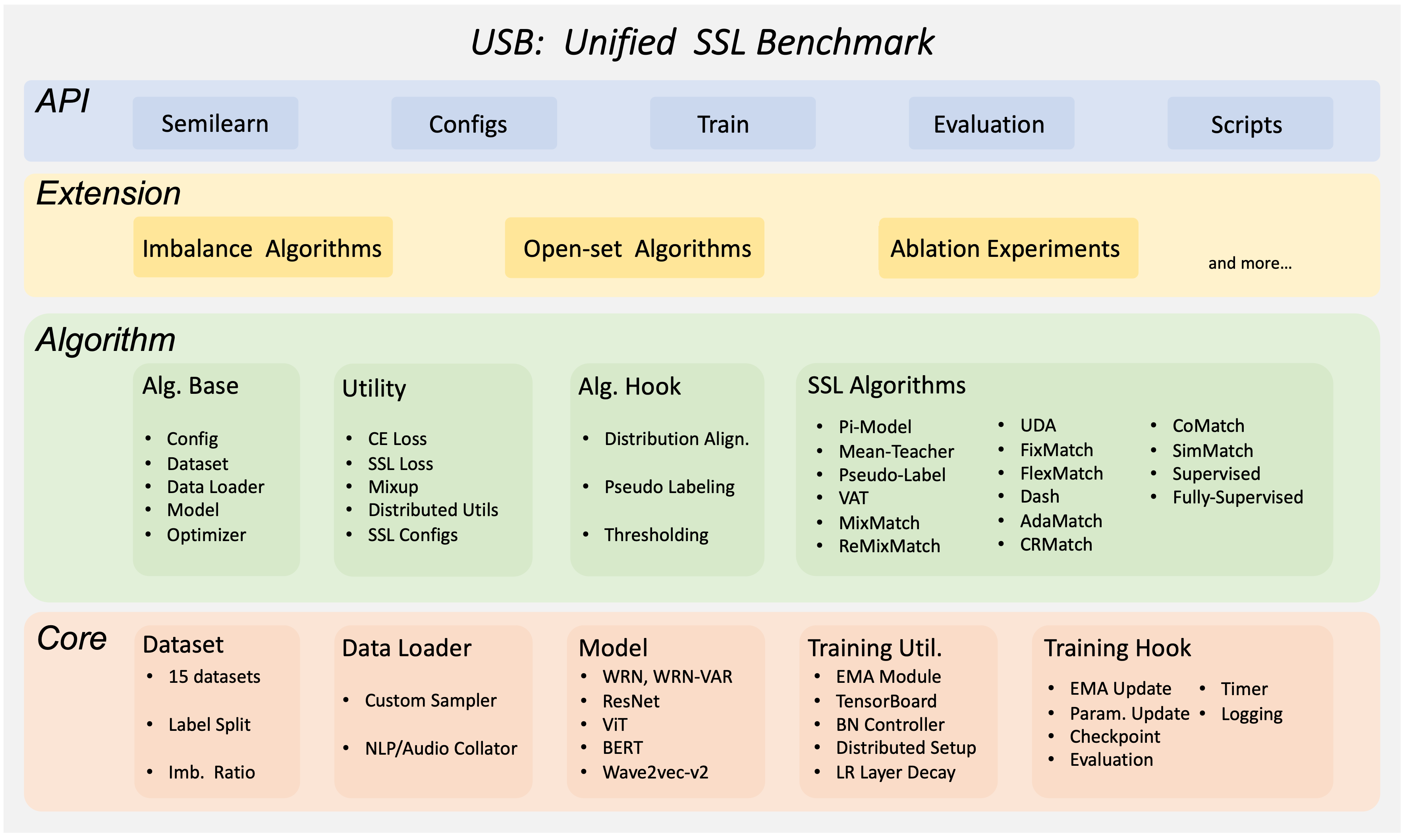
Introduction to FreeMatch and SoftMatch in Semi-Supervised Learning#
Here we provide a brief introduction to FreeMatch and SoftMatch.
First, we introduce a famous baseline for semi-supervised learning called FixMatch.
FixMatch is a very simple framework for semi-supervised learning, where it
utilizes a strong augmentation to generate pseudo labels for unlabeled data.
It adopts a confidence thresholding strategy to filter out the low-confidence
pseudo labels with a fixed threshold set.
FreeMatch and SoftMatch are two algorithms that improve upon FixMatch.
FreeMatch proposes adaptive thresholding strategy to replace the fixed
thresholding strategy in FixMatch. The adaptive thresholding progressively
increases the threshold according to the learning status of the model on each
class. SoftMatch absorbs the idea of confidence thresholding as an
weighting mechanism. It proposes a Gaussian weighting mechanism to overcome
the quantity-quality trade-off in pseudo-labels. In this tutorial, we will
use USB to train FreeMatch and SoftMatch.
Use USB to Train FreeMatch/SoftMatch on CIFAR-10 with only 40 labels#
USB is easy to use and extend, affordable to small groups, and comprehensive for developing and evaluating SSL algorithms. USB provides the implementation of 14 SSL algorithms based on Consistency Regularization, and 15 tasks for evaluation from CV, NLP, and Audio domain. It has a modular design that allows users to easily extend the package by adding new algorithms and tasks. It also supports a Python API for easier adaptation to different SSL algorithms on new data.
Now, let’s use USB to train FreeMatch and SoftMatch on CIFAR-10.
First, we need to install USB package semilearn and import necessary API
functions from USB.
If you are running this in Google Colab, install semilearn by running:
!pip install semilearn.
Below is a list of functions we will use from semilearn:
get_datasetto load dataset, here we use CIFAR-10get_data_loaderto create train (labeled and unlabeled) and test data
loaders, the train unlabeled loaders will provide both strong and weak
augmentation of unlabeled data
- get_net_builder to create a model, here we use pretrained ViT
- get_algorithm to create the semi-supervised learning algorithm,
here we use FreeMatch and SoftMatch
- get_config: to get default configuration of the algorithm
- Trainer: a Trainer class for training and evaluating the
algorithm on dataset
Note that a CUDA-enabled backend is required for training with the semilearn package.
See Enabling CUDA in Google Colab for instructions
on enabling CUDA in Google Colab.
import semilearn
from semilearn import get_dataset, get_data_loader, get_net_builder, get_algorithm, get_config, Trainer
Traceback (most recent call last):
File "/workspace/tutorials-kr/advanced_source/usb_semisup_learn.py", line 87, in <module>
import semilearn
File "/opt/conda/lib/python3.11/site-packages/semilearn/__init__.py", line 4, in <module>
from .core.utils import get_dataset, get_data_loader, get_net_builder
File "/opt/conda/lib/python3.11/site-packages/semilearn/core/__init__.py", line 5, in <module>
from .algorithmbase import AlgorithmBase, ImbAlgorithmBase
File "/opt/conda/lib/python3.11/site-packages/semilearn/core/algorithmbase.py", line 13, in <module>
from semilearn.core.hooks import (
File "/opt/conda/lib/python3.11/site-packages/semilearn/core/hooks/__init__.py", line 13, in <module>
from .wandb import WANDBHook
File "/opt/conda/lib/python3.11/site-packages/semilearn/core/hooks/wandb.py", line 5, in <module>
import wandb
File "/opt/conda/lib/python3.11/site-packages/wandb/__init__.py", line 25, in <module>
from wandb import sdk as wandb_sdk
File "/opt/conda/lib/python3.11/site-packages/wandb/sdk/__init__.py", line 25, in <module>
from .artifacts.artifact import Artifact
File "/opt/conda/lib/python3.11/site-packages/wandb/sdk/artifacts/artifact.py", line 40, in <module>
from wandb import data_types, env
File "/opt/conda/lib/python3.11/site-packages/wandb/data_types.py", line 16, in <module>
from .sdk.data_types.audio import Audio
File "/opt/conda/lib/python3.11/site-packages/wandb/sdk/data_types/audio.py", line 11, in <module>
from .base_types.media import BatchableMedia
File "/opt/conda/lib/python3.11/site-packages/wandb/sdk/data_types/base_types/media.py", line 13, in <module>
from .wb_value import WBValue
File "/opt/conda/lib/python3.11/site-packages/wandb/sdk/data_types/base_types/wb_value.py", line 4, in <module>
from wandb.sdk import wandb_setup
File "/opt/conda/lib/python3.11/site-packages/wandb/sdk/wandb_setup.py", line 39, in <module>
from . import wandb_settings
File "/opt/conda/lib/python3.11/site-packages/wandb/sdk/wandb_settings.py", line 23, in <module>
from pydantic import BaseModel, ConfigDict, Field
ImportError: cannot import name 'ConfigDict' from 'pydantic' (/opt/conda/lib/python3.11/site-packages/pydantic/__init__.py)
After importing necessary functions, we first set the hyper-parameters of the algorithm.
config = {
'algorithm': 'freematch',
'net': 'vit_tiny_patch2_32',
'use_pretrain': True,
'pretrain_path': 'https://github.com/microsoft/Semi-supervised-learning/releases/download/v.0.0.0/vit_tiny_patch2_32_mlp_im_1k_32.pth',
# optimization configs
'epoch': 1,
'num_train_iter': 500,
'num_eval_iter': 500,
'num_log_iter': 50,
'optim': 'AdamW',
'lr': 5e-4,
'layer_decay': 0.5,
'batch_size': 16,
'eval_batch_size': 16,
# dataset configs
'dataset': 'cifar10',
'num_labels': 40,
'num_classes': 10,
'img_size': 32,
'crop_ratio': 0.875,
'data_dir': './data',
'ulb_samples_per_class': None,
# algorithm specific configs
'hard_label': True,
'T': 0.5,
'ema_p': 0.999,
'ent_loss_ratio': 0.001,
'uratio': 2,
'ulb_loss_ratio': 1.0,
# device configs
'gpu': 0,
'world_size': 1,
'distributed': False,
"num_workers": 4,
}
config = get_config(config)
Then, we load the dataset and create data loaders for training and testing. And we specify the model and algorithm to use.
dataset_dict = get_dataset(config, config.algorithm, config.dataset, config.num_labels, config.num_classes, data_dir=config.data_dir, include_lb_to_ulb=config.include_lb_to_ulb)
train_lb_loader = get_data_loader(config, dataset_dict['train_lb'], config.batch_size)
train_ulb_loader = get_data_loader(config, dataset_dict['train_ulb'], int(config.batch_size * config.uratio))
eval_loader = get_data_loader(config, dataset_dict['eval'], config.eval_batch_size)
algorithm = get_algorithm(config, get_net_builder(config.net, from_name=False), tb_log=None, logger=None)
We can start training the algorithms on CIFAR-10 with 40 labels now. We train for 500 iterations and evaluate every 500 iterations.
trainer = Trainer(config, algorithm)
trainer.fit(train_lb_loader, train_ulb_loader, eval_loader)
Finally, let’s evaluate the trained model on the validation set.
After training 500 iterations with FreeMatch on only 40 labels of
CIFAR-10, we obtain a classifier that achieves around 87% accuracy on the validation set.
trainer.evaluate(eval_loader)
Use USB to Train SoftMatch with specific imbalanced algorithm on imbalanced CIFAR-10#
Now let’s say we have imbalanced labeled set and unlabeled set of CIFAR-10,
and we want to train a SoftMatch model on it.
We create an imbalanced labeled set and imbalanced unlabeled set of CIFAR-10,
by setting the lb_imb_ratio and ulb_imb_ratio to 10.
Also, we replace the algorithm with softmatch and set the imbalanced
to True.
config = {
'algorithm': 'softmatch',
'net': 'vit_tiny_patch2_32',
'use_pretrain': True,
'pretrain_path': 'https://github.com/microsoft/Semi-supervised-learning/releases/download/v.0.0.0/vit_tiny_patch2_32_mlp_im_1k_32.pth',
# optimization configs
'epoch': 1,
'num_train_iter': 500,
'num_eval_iter': 500,
'num_log_iter': 50,
'optim': 'AdamW',
'lr': 5e-4,
'layer_decay': 0.5,
'batch_size': 16,
'eval_batch_size': 16,
# dataset configs
'dataset': 'cifar10',
'num_labels': 1500,
'num_classes': 10,
'img_size': 32,
'crop_ratio': 0.875,
'data_dir': './data',
'ulb_samples_per_class': None,
'lb_imb_ratio': 10,
'ulb_imb_ratio': 10,
'ulb_num_labels': 3000,
# algorithm specific configs
'hard_label': True,
'T': 0.5,
'ema_p': 0.999,
'ent_loss_ratio': 0.001,
'uratio': 2,
'ulb_loss_ratio': 1.0,
# device configs
'gpu': 0,
'world_size': 1,
'distributed': False,
"num_workers": 4,
}
config = get_config(config)
Then, we re-load the dataset and create data loaders for training and testing. And we specify the model and algorithm to use.
dataset_dict = get_dataset(config, config.algorithm, config.dataset, config.num_labels, config.num_classes, data_dir=config.data_dir, include_lb_to_ulb=config.include_lb_to_ulb)
train_lb_loader = get_data_loader(config, dataset_dict['train_lb'], config.batch_size)
train_ulb_loader = get_data_loader(config, dataset_dict['train_ulb'], int(config.batch_size * config.uratio))
eval_loader = get_data_loader(config, dataset_dict['eval'], config.eval_batch_size)
algorithm = get_algorithm(config, get_net_builder(config.net, from_name=False), tb_log=None, logger=None)
We can start Train the algorithms on CIFAR-10 with 40 labels now. We train for 500 iterations and evaluate every 500 iterations.
trainer = Trainer(config, algorithm)
trainer.fit(train_lb_loader, train_ulb_loader, eval_loader)
Finally, let’s evaluate the trained model on the validation set.
trainer.evaluate(eval_loader)
References: - [1] USB: microsoft/Semi-supervised-learning - [2] Kihyuk Sohn et al. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence - [3] Yidong Wang et al. FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning - [4] Hao Chen et al. SoftMatch: Addressing the Quantity-Quality Trade-off in Semi-supervised Learning
Total running time of the script: (0 minutes 4.795 seconds)
