


참고
Go to the end to download the full example code.
미분 자동화(autograd)에서 저장된 tensor를 위한 Hooks#
파이토치는 일반적으로 역전파를 통해 기울기를 계산합니다. 그러나 특정 작업에서는 역전파를 수행하기 위한 중간결과를 저장해야 합니다. 이번 튜토리얼에서는 이러한 tensor를 저장/검색하는 방법과 패킹/언패킹 절차를 제어하는 hooks을 정의하는 방법을 안내합니다.
# 이 튜토리얼에서는 독자가 역전파가 어떻게 동작하는지를 이론적으로 잘 알고 있다고 가정합니다.
# 아니라면, `이것 <https://colab.research.google.com/drive/1aWNdmYt7RcHMbUk-Xz2Cv5-cGFSWPXe0#scrollTo=AHcEJ6nXUb7W>`_ 을 먼저 읽어보세요.
#
저장된 tensor#
일반적으로 모델을 추론하는 것보다 학습하는 과정에서 메모리를 더 많이 사용합니다. 대략적으로 말하면 파이토치는 역전파를 호출하는데 필요한 계산 그래프를 저장해야하므로 추가 메모리 사용하기 때문입니다. 이 튜토리얼의 목표 중 하나는 이런 내용을 이해와 미세 조정을 제공하는 것입니다.
실제로 때때로 (연산) 그래프 자체는 tensor들을 전혀 복제하지 않기 때문에 많은 메모리를 소모하지는 않습니다. 하지만, 그래프는 범위에서 벗어난 tensor들에 대한 참조(reference) 는 유지할 수 있습니다. 이러한 tensor들을 저장된 tensor(saved tensor) 라고 합니다.
(일반적으로) 모델을 훈련하는데 평가보다 더 많은 메모리를 사용하는 이유는 무엇일까요?#
간단한 예제를 시작해봅시다: \(y = a \cdot b\), 변화도를 알고있는 :math: y,로 각각 :math: a and :math: b:로 합니다.
# .. math:: \frac{\partial y}{\partial a} = b
# .. math:: \frac{\partial y}{\partial b} = a
import torch
a = torch.randn(5, requires_grad=True)
b = torch.ones(5, requires_grad=True)
y = a * b
torchviz를 사용해서, 계산그래프를 시각화 할 수 있습니다. .. figure:: https://user-images.githubusercontent.com/8019486/130124513-72e016a3-c36f-42b9-88e2-53baf3e016c5.png
- width:
300
- align:
center
이 예제에서 파이토치는 중간 값 :math: a 및 :math: b 를 저장하여 역방향 동안 변화도를 계산합니다.

이러한 중간 값(위의 주황색)은 접두사 _saved``로 시작하는
``y``의 ``grad_fn 속성을 찾아 (디버깅 목적으로) 접근 할 수 있습니다.
print(y.grad_fn._saved_self)
print(y.grad_fn._saved_other)
tensor([-1.6340, 0.3721, 0.6295, 0.5244, -1.9466], requires_grad=True)
tensor([1., 1., 1., 1., 1.], requires_grad=True)
계산 그래프가 깊어질수록 *저장된 tensor*가 더 많이 저장됩니다. 한편, tensor는 그래프가 아니었다면 범위를 벗어나게 됩니다.
def f(x):
return x * x
x = torch.randn(5, requires_grad=True)
y = f(f(f(x)))
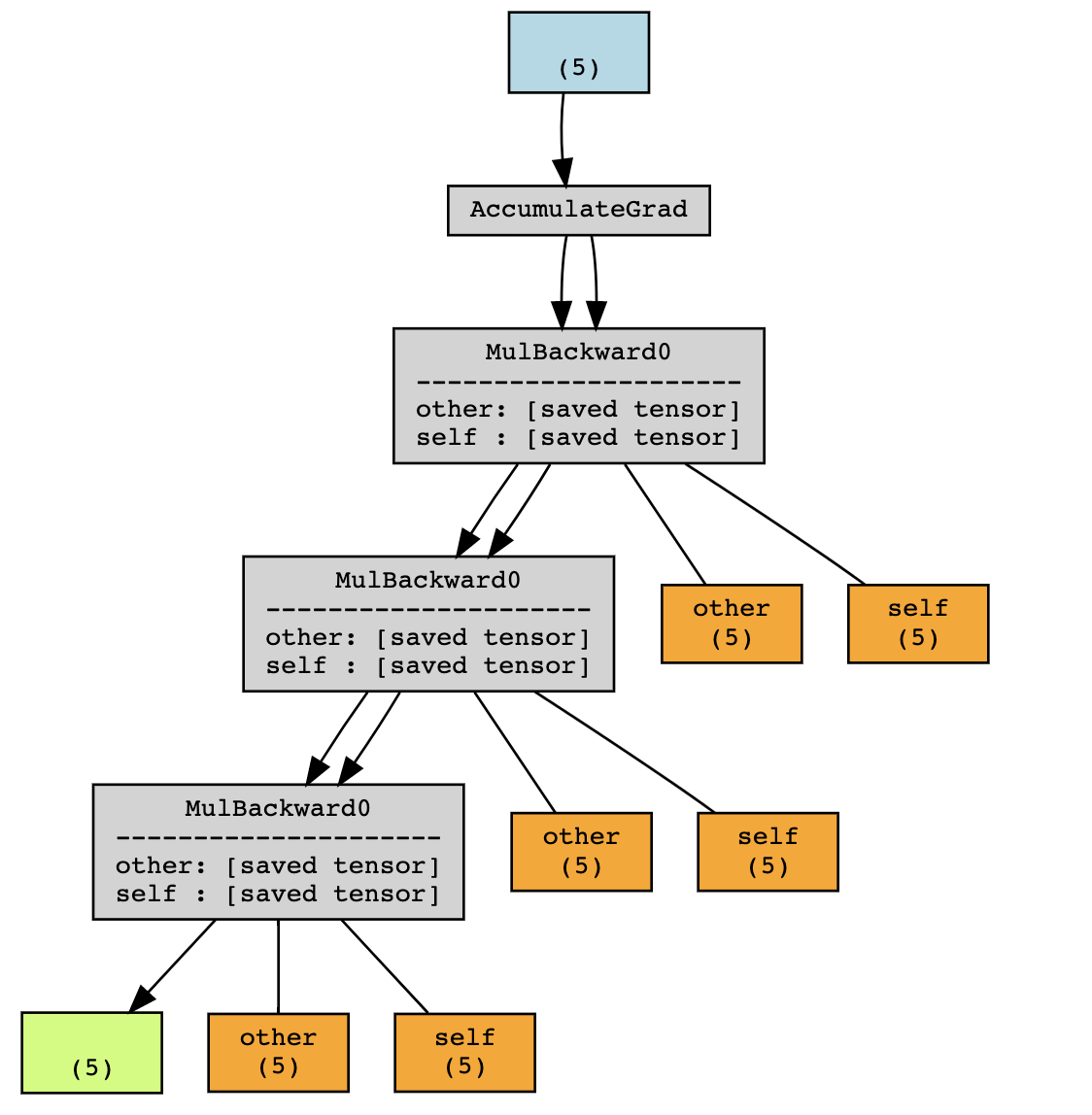
위의 예제에서 미분(grad)없이 실행하면 범위내의 x 와 y 는 유지되지만
그래프에서는 f(x) 와 f(f(x)) 가 추가로 저장됩니다.
따라서 훈련 중 정방향 경로를 실행하면 평가중에
(더 정확하게는 자동미분(auto grad)가 필요하지 않은 경우보다)
메모리 사용량이 더 많아지게 됩니다.
패킹과 언패킹의 개념#
첫 번째 예제로 돌아가서 y.grad_fn._saved_self 와 y.grad_fn._saved_other 는
각각 원래 tensor 객체 a 와 b 를 가리킵니다.
a = torch.randn(5, requires_grad=True)
b = torch.ones(5, requires_grad=True)
y = a * b
print(y.grad_fn._saved_self is a) # True
print(y.grad_fn._saved_other is b) # True
True
True
그러나 이것은 항상 같은 결과를 보여주지 않습니다.
a = torch.randn(5, requires_grad=True)
y = torch.exp(a)
print(y.grad_fn._saved_result.equal(y)) # True
print(y.grad_fn._saved_result is y) # False
True
False
내부적으로는 파이토치는 참조주기를 방지하기 위해서 tensor y 를
패킹 및 언패킹 했습니다
경험상, 역전파 저장된 tensor에 엑세스하면 원래 tensor와
동일한 tensor의 객체가 생성된다는 결과를 기대해서는 안됩니다.
그러나 tensor는 동일한 *저장소*를 공유합니다.
저장된 tensor hooks#
파이토치는 tensor들이 어떻게 패킹되고 언패킹되는지 저장할 수 있는 제어 가능한 API를 제공합니다.
def pack_hook(x):
print("Packing", x)
return x
def unpack_hook(x):
print("Unpacking", x)
return x
a = torch.ones(5, requires_grad=True)
b = torch.ones(5, requires_grad=True) * 2
with torch.autograd.graph.saved_tensors_hooks(pack_hook, unpack_hook):
y = a * b
y.sum().backward()
Packing tensor([2., 2., 2., 2., 2.], grad_fn=<MulBackward0>)
Packing tensor([1., 1., 1., 1., 1.], requires_grad=True)
Unpacking tensor([2., 2., 2., 2., 2.], grad_fn=<MulBackward0>)
Unpacking tensor([1., 1., 1., 1., 1.], requires_grad=True)
pack_hook 함수는 작업이 역전파를 위해 tensor를 저장할 때 마다 호출됩니다. 그러면
pack_hook 의 출력이 원래 tensor 대신 계산 그래프에 저장됩니다.
unpack_hook 은 해당 반환 값을 사용하여 역방향 전달 중에 실제로 사용된 tensor를 새 tensor로 계산합니다.
일반적으로 unpack_hook(pack_hook(t)) 가 t 와 같길 기대합니다.
x = torch.randn(5, requires_grad=True)
with torch.autograd.graph.saved_tensors_hooks(lambda x: x * 4, lambda x: x / 4):
y = torch.pow(x, 2)
y.sum().backward()
assert(x.grad.equal(2 * x))
한 가지 주의할 점은 unpack_hook 이 올바른 값을 가진 tensor를 파생할 수 있는 한
pack_hook 의 출력은 any 파이썬 객체 가 될 수 있다는 것입니다.
몇 가지 특이한 예제들#
먼저, 가능은 하지만 바보같아서 누구도 하고 싶어하지 않는 예제 몇가지를 살펴보겠습니다.
int 반환#
파이썬 리스트의 인덱스 반환 상대적으로는 위험하진 않지만 논란의 여지가 있는 유용성
storage = []
def pack(x):
storage.append(x)
return len(storage) - 1
def unpack(x):
return storage[x]
x = torch.randn(5, requires_grad=True)
with torch.autograd.graph.saved_tensors_hooks(pack, unpack):
y = x * x
y.sum().backward()
assert(x.grad.equal(2 * x))
튜플(tuple) 반환#
일부 tensor와 함수를 반환하고 패킹을 푸는 방법은 이런 형태로는 유용하지 않을 것입니다.
def pack(x):
delta = torch.randn(*x.size())
return x - delta, lambda x: x + delta
def unpack(packed):
x, f = packed
return f(x)
x = torch.randn(5, requires_grad=True)
with torch.autograd.graph.saved_tensors_hooks(pack, unpack):
y = x * x
y.sum().backward()
assert(torch.allclose(x.grad, 2 * x))
str 반환#
tensor의 __repr__ 반환 아마도 이렇게는 하지 않을 것입니다.
x = torch.randn(5, requires_grad=True)
with torch.autograd.graph.saved_tensors_hooks(lambda x: repr(x), lambda x: eval("torch." + x)):
y = x * x
y.sum().backward()
assert(torch.all(x.grad - 2 * x <= 1e-4))
이러한 예제는 실제로 유용하지 않을 것이지만
원래 tensor의 내용을 가져오기에 충분한 정보를 가지고 있다면
pack_hook 의 결과물이 어떤 파이썬 객체라도
될 수 있음을 보여줍니다.
다음 섹션에서는 더 유용한 응용프로그램에 중점을 두겠습니다.
tensor를 CPU에 저장하기#
매우 빈번하게, tensor 계산 그래프 GPU에 살아 있습니다. 대부분 경우에서 모델이 평가중에 정상적으로 수행되지만 훈련 중에 메모리가 부족하다면, 계산 그래프에서 tensor에 대한 참조 유지가 GPU 메모리를 부족하게 만드는 원인이 됩니다.
hooks는 이를 구현하는 매우 간단한 방법을 제공합니다.
def pack_hook(x):
return (x.device, x.cpu())
def unpack_hook(packed):
device, tensor = packed
return tensor.to(device)
x = torch.randn(5, requires_grad=True)
with torch.autograd.graph.saved_tensors_hooks(pack, unpack):
y = x * x
y.sum().backward()
torch.allclose(x.grad, (2 * x))
True
실제로 파이토치는 이러한 hooks를 편리하게 사용할 수 있는 API를 제공합니다. (고정된 메모리를 사용하는 기능도 포함).
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.w = nn.Parameter(torch.randn(5))
def forward(self, x):
with torch.autograd.graph.save_on_cpu(pin_memory=True):
# some computation
return self.w * x
x = torch.randn(5)
model = Model()
loss = model(x).sum()
loss.backward()
실제로 A100 GPU에서 배치크기가 256인 ResNet-152의 경우 이는 GPU 메모리 사용량이 48G에서 5GB로 줄어들지만, 이는 6배 느려지는 대가를 치러야합니다.
물론 네트워크 특정부분만 CPU에 저장하여 절충안을 조정할 수 있습니다.
예를 들어, 어떤 모듈을 감싸두고 해당 tensor를 CPU에 저장하는 특별한
nn.Module 을 정의할 수 있습니다.
class SaveToCpu(nn.Module):
def __init__(self, module):
super().__init__()
self.module = module
def forward(self, *args, **kwargs):
with torch.autograd.graph.save_on_cpu(pin_memory=True):
return self.module(*args, **kwargs)
model = nn.Sequential(
nn.Linear(10, 100),
SaveToCpu(nn.Linear(100, 100)),
nn.Linear(100, 10),
)
x = torch.randn(10)
loss = model(x).sum()
loss.backward()
tensor를 디스크에 저장하기#
비슷하게, 이러한 tensor를 디스크에 저장하고 싶을 수 도 있습니다. 다시 말하지만 이것은 앞서말한 hooks로 달성할 수 있습니다.
모자란 버전은 보통 이럴것입니다.
모자란 버전(naive version) - 힌트: 이렇게 하지 마시오.
import uuid
tmp_dir = "temp"
def pack_hook(tensor):
name = os.path.join(tmp_dir, str(uuid.uuid4()))
torch.save(tensor, name)
return name
def unpack_hook(name):
return torch.load(name, weights_only=True)
위의 코드가 나쁜 이유는 디스크에 저장된 파일이 누출되고 해당 파일을 지울수도 없기 때문입니다. 이 문제를 해결하는 것은 그렇게 간단하지 않아 보입니다.
잘못된 버전 - 힌트: 이렇게 하지 마시오.
import uuid
import os
import tempfile
tmp_dir_obj = tempfile.TemporaryDirectory()
tmp_dir = tmp_dir_obj.name
def pack_hook(tensor):
name = os.path.join(tmp_dir, str(uuid.uuid4()))
torch.save(tensor, name)
return name
def unpack_hook(name):
tensor = torch.load(name, weights_only=True)
os.remove(name)
return tensor
위의 코드가 작동하지 않는 이유는 unpack_hook 가 여러번 호출되기 때문입니다.
먼저 압축을 풀 때 파일을 삭제하면 처음에, 저장된 tensor에 접근시에 사용할 수 없습니다.
두 번째에는 오류가 발생합니다.
x = torch.ones(5, requires_grad=True)
with torch.autograd.graph.saved_tensors_hooks(pack_hook, unpack_hook):
y = x.pow(2)
print(y.grad_fn._saved_self)
try:
print(y.grad_fn._saved_self)
print("Double access succeeded!")
except:
print("Double access failed!")
tensor([1., 1., 1., 1., 1.], requires_grad=True)
Double access failed!
이 문제를 해결하기 위해, 파이토치는 저장된 데이터를 더이상 필요하지 않을 때 자동으로 해제(삭제) 하는 이점을 활용하는 hooks의 버전을 작성할 수 있습니다.
class SelfDeletingTempFile():
def __init__(self):
self.name = os.path.join(tmp_dir, str(uuid.uuid4()))
def __del__(self):
os.remove(self.name)
def pack_hook(tensor):
temp_file = SelfDeletingTempFile()
torch.save(tensor, temp_file.name)
return temp_file
def unpack_hook(temp_file):
return torch.load(temp_file.name, weights_only=True)
backward 를 호출하면 pack_hook 이 삭제되고,
파일이 제거되도록 하므로 더 이상 파일이 누출되지 않습니다.
다음과 같은 방식으로 모델에 사용할 수 있습니다.
# 사이즈 >=1000인 tensor만이 디스크에 저장될 수 있습니다.
SAVE_ON_DISK_THRESHOLD = 1000
def pack_hook(x):
if x.numel() < SAVE_ON_DISK_THRESHOLD:
return x
temp_file = SelfDeletingTempFile()
torch.save(tensor, temp_file.name)
return temp_file
def unpack_hook(tensor_or_sctf):
if isinstance(tensor_or_sctf, torch.Tensor):
return tensor_or_sctf
return torch.load(tensor_or_sctf.name)
class SaveToDisk(nn.Module):
def __init__(self, module):
super().__init__()
self.module = module
def forward(self, *args, **kwargs):
with torch.autograd.graph.saved_tensors_hooks(pack_hook, unpack_hook):
return self.module(*args, **kwargs)
net = nn.DataParallel(SaveToDisk(Model()))
이 마지막 예제에서는 저장해야 하는 (여기에서는 원소의 수가 1000 이상인) tensor들을 골라내는 방법과
이 기능을 nn.DataParallel 과 함께 사용하는 방법을 살펴보았습니다.
여기까지 잘 따라오셨나요? 축하합니다! 이제 저장된 tensor hooks를 어떻게 사용하는지와 연산 시 메모리 관리(trade-offs)에 유용하게 사용할 수 있는 방법을 알게 되셨습니다.
Total running time of the script: (0 minutes 5.076 seconds)

{kind=link}