


참고
Click here to download the full example code
PyTorch FX Numeric Suite Core APIs Tutorial¶
Introduction¶
Quantization is good when it works, but it is difficult to know what is wrong when it does not satisfy the accuracy we expect. Debugging the accuracy issue of quantization is not easy and time-consuming.
One important step of debugging is to measure the statistics of the float model and its corresponding quantized model to know where they differ most. We built a suite of numeric tools called PyTorch FX Numeric Suite Core APIs in PyTorch quantization to enable the measurement of the statistics between quantized module and float module to support quantization debugging efforts. Even for the quantized model with good accuracy, PyTorch FX Numeric Suite Core APIs can still be used as the profiling tool to better understand the quantization error within the model and provide the guidance for further optimization.
PyTorch FX Numeric Suite Core APIs currently supports models quantized through both static quantization and dynamic quantization with unified APIs.
In this tutorial we will use MobileNetV2 as an example to show how to use PyTorch FX Numeric Suite Core APIs to measure the statistics between static quantized model and float model.
Setup¶
We’ll start by doing the necessary imports:
# Imports and util functions
import copy
import torch
import torchvision
import torch.quantization
import torch.ao.ns._numeric_suite_fx as ns
import torch.quantization.quantize_fx as quantize_fx
import matplotlib.pyplot as plt
from tabulate import tabulate
torch.manual_seed(0)
plt.style.use('seaborn-whitegrid')
# a simple line graph
def plot(xdata, ydata, xlabel, ylabel, title):
_ = plt.figure(figsize=(10, 5), dpi=100)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.title(title)
ax = plt.axes()
ax.plot(xdata, ydata)
plt.show()
Then we load the pretrained float MobileNetV2 model, and quantize it.
# create float model
mobilenetv2_float = torchvision.models.quantization.mobilenet_v2(
pretrained=True, quantize=False).eval()
# create quantized model
qconfig_dict = {
'': torch.quantization.get_default_qconfig('fbgemm'),
# adjust the qconfig to make the results more interesting to explore
'module_name': [
# turn off quantization for the first couple of layers
('features.0', None),
('features.1', None),
# use MinMaxObserver for `features.17`, this should lead to worse
# weight SQNR
('features.17', torch.quantization.default_qconfig),
]
}
# Note: quantization APIs are inplace, so we save a copy of the float model for
# later comparison to the quantized model. This is done throughout the
# tutorial.
datum = torch.randn(1, 3, 224, 224)
mobilenetv2_prepared = quantize_fx.prepare_fx(
copy.deepcopy(mobilenetv2_float), qconfig_dict, (datum,))
mobilenetv2_prepared(datum)
# Note: there is a long standing issue that we cannot copy.deepcopy a
# quantized model. Since quantization APIs are inplace and we need to use
# different copies of the quantized model throughout this tutorial, we call
# `convert_fx` on a copy, so we have access to the original `prepared_model`
# later. This is done throughout the tutorial.
mobilenetv2_quantized = quantize_fx.convert_fx(
copy.deepcopy(mobilenetv2_prepared))
Downloading: "https://download.pytorch.org/models/mobilenet_v2-b0353104.pth" to /root/.cache/torch/hub/checkpoints/mobilenet_v2-b0353104.pth
0%| | 0.00/13.6M [00:00<?, ?B/s]
56%|#####6 | 7.62M/13.6M [00:00<00:00, 79.9MB/s]
100%|##########| 13.6M/13.6M [00:00<00:00, 92.1MB/s]
1. Compare the weights of float and quantized models¶
The first analysis we can do is comparing the weights of the fp32 model and the int8 model by calculating the SQNR between each pair of weights.
The extract_weights API can be used to extract weights from linear, convolution and LSTM layers. It works for dynamic quantization as well as PTQ/QAT.
# Note: when comparing weights in models with Conv-BN for PTQ, we need to
# compare weights after Conv-BN fusion for a proper comparison. Because of
# this, we use `prepared_model` instead of `float_model` when comparing
# weights.
# Extract conv and linear weights from corresponding parts of two models, and
# save them in `wt_compare_dict`.
mobilenetv2_wt_compare_dict = ns.extract_weights(
'fp32', # string name for model A
mobilenetv2_prepared, # model A
'int8', # string name for model B
mobilenetv2_quantized, # model B
)
# calculate SQNR between each pair of weights
ns.extend_logger_results_with_comparison(
mobilenetv2_wt_compare_dict, # results object to modify inplace
'fp32', # string name of model A (from previous step)
'int8', # string name of model B (from previous step)
torch.ao.ns.fx.utils.compute_sqnr, # tensor comparison function
'sqnr', # the name to use to store the results under
)
# massage the data into a format easy to graph and print
mobilenetv2_wt_to_print = []
for idx, (layer_name, v) in enumerate(mobilenetv2_wt_compare_dict.items()):
mobilenetv2_wt_to_print.append([
idx,
layer_name,
v['weight']['int8'][0]['prev_node_target_type'],
v['weight']['int8'][0]['values'][0].shape,
v['weight']['int8'][0]['sqnr'][0],
])
# plot the SQNR between fp32 and int8 weights for each layer
plot(
[x[0] for x in mobilenetv2_wt_to_print],
[x[4] for x in mobilenetv2_wt_to_print],
'idx',
'sqnr',
'weights, idx to sqnr'
)
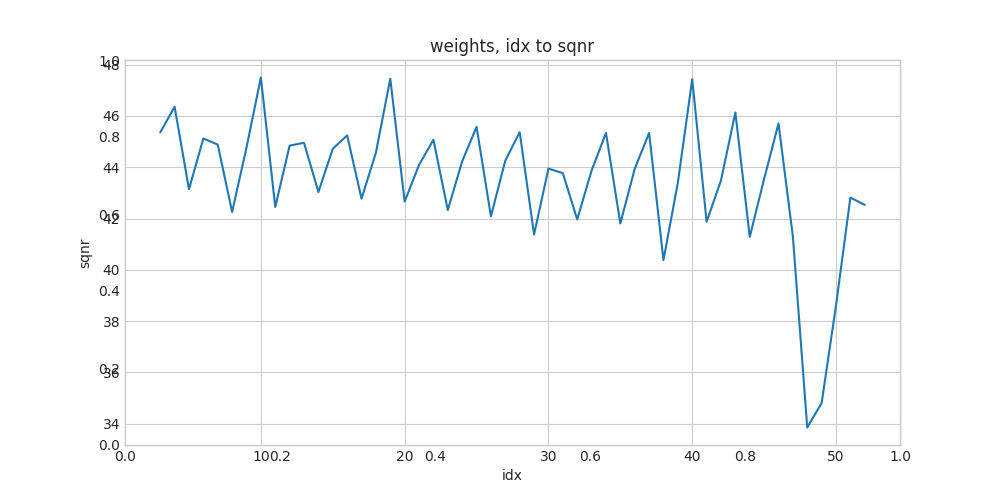
Also print out the SQNR, so we can inspect the layer name and type:
print(tabulate(
mobilenetv2_wt_to_print,
headers=['idx', 'layer_name', 'type', 'shape', 'sqnr']
))
idx layer_name type shape sqnr
----- -------------------- --------------------------------------------------------- ----------------------------- --------
0 features_0_0 torch.ao.nn.intrinsic.modules.fused.ConvReLU2d torch.Size([32, 3, 3, 3]) inf
1 features_1_conv_0_0 torch.ao.nn.intrinsic.modules.fused.ConvReLU2d torch.Size([32, 1, 3, 3]) inf
2 features_1_conv_1 torch.nn.modules.conv.Conv2d torch.Size([16, 32, 1, 1]) inf
3 features_2_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([96, 16, 1, 1]) 45.3583
4 features_2_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([96, 1, 3, 3]) 46.3591
5 features_2_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([24, 96, 1, 1]) 43.1405
6 features_3_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([144, 24, 1, 1]) 45.1226
7 features_3_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([144, 1, 3, 3]) 44.8846
8 features_3_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([24, 144, 1, 1]) 42.2562
9 features_4_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([144, 24, 1, 1]) 44.7671
10 features_4_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([144, 1, 3, 3]) 47.5017
11 features_4_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([32, 144, 1, 1]) 42.4501
12 features_5_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([192, 32, 1, 1]) 44.8431
13 features_5_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([192, 1, 3, 3]) 44.955
14 features_5_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([32, 192, 1, 1]) 43.0342
15 features_6_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([192, 32, 1, 1]) 44.7193
16 features_6_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([192, 1, 3, 3]) 45.2428
17 features_6_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([32, 192, 1, 1]) 42.7734
18 features_7_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([192, 32, 1, 1]) 44.5686
19 features_7_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([192, 1, 3, 3]) 47.4552
20 features_7_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([64, 192, 1, 1]) 42.6587
21 features_8_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([384, 64, 1, 1]) 44.091
22 features_8_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([384, 1, 3, 3]) 45.0733
23 features_8_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([64, 384, 1, 1]) 42.3311
24 features_9_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([384, 64, 1, 1]) 44.2334
25 features_9_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([384, 1, 3, 3]) 45.5776
26 features_9_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([64, 384, 1, 1]) 42.0875
27 features_10_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([384, 64, 1, 1]) 44.2595
28 features_10_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([384, 1, 3, 3]) 45.3682
29 features_10_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([64, 384, 1, 1]) 41.3764
30 features_11_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([384, 64, 1, 1]) 43.9487
31 features_11_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([384, 1, 3, 3]) 43.7704
32 features_11_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([96, 384, 1, 1]) 41.963
33 features_12_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([576, 96, 1, 1]) 43.8682
34 features_12_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([576, 1, 3, 3]) 45.3413
35 features_12_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([96, 576, 1, 1]) 41.8074
36 features_13_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([576, 96, 1, 1]) 43.9367
37 features_13_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([576, 1, 3, 3]) 45.3374
38 features_13_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([96, 576, 1, 1]) 40.3783
39 features_14_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([576, 96, 1, 1]) 43.3986
40 features_14_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([576, 1, 3, 3]) 47.4357
41 features_14_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([160, 576, 1, 1]) 41.8716
42 features_15_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([960, 160, 1, 1]) 43.4877
43 features_15_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([960, 1, 3, 3]) 46.1367
44 features_15_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([160, 960, 1, 1]) 41.2812
45 features_16_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([960, 160, 1, 1]) 43.5446
46 features_16_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([960, 1, 3, 3]) 45.7084
47 features_16_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([160, 960, 1, 1]) 41.2971
48 features_17_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([960, 160, 1, 1]) 33.8474
49 features_17_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([960, 1, 3, 3]) 34.8042
50 features_17_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([320, 960, 1, 1]) 38.6114
51 features_18_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1280, 320, 1, 1]) 42.8171
52 classifier_1 torch.ao.nn.quantized.modules.linear.Linear torch.Size([1000, 1280]) 42.5315
2. Compare activations API¶
The second tool allows for comparison of activations between float and quantized models at corresponding locations for the same input.
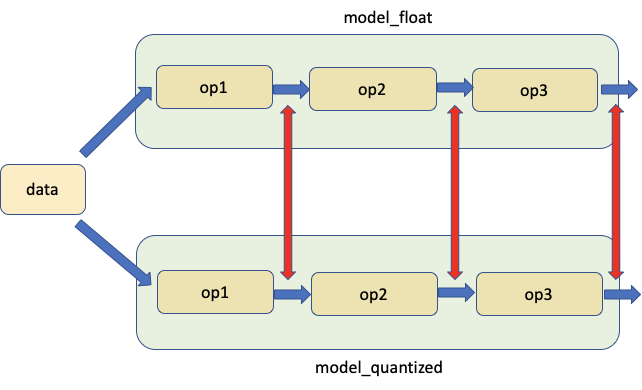
The add_loggers/extract_logger_info API can be used to to extract activations from any layer with a torch.Tensor return type. It works for dynamic quantization as well as PTQ/QAT.
# Compare unshadowed activations
# Create a new copy of the quantized model, because we cannot `copy.deepcopy`
# a quantized model.
mobilenetv2_quantized = quantize_fx.convert_fx(
copy.deepcopy(mobilenetv2_prepared))
mobilenetv2_float_ns, mobilenetv2_quantized_ns = ns.add_loggers(
'fp32', # string name for model A
copy.deepcopy(mobilenetv2_prepared), # model A
'int8', # string name for model B
mobilenetv2_quantized, # model B
ns.OutputLogger, # logger class to use
)
# feed data through network to capture intermediate activations
mobilenetv2_float_ns(datum)
mobilenetv2_quantized_ns(datum)
# extract intermediate activations
mobilenetv2_act_compare_dict = ns.extract_logger_info(
mobilenetv2_float_ns, # model A, with loggers (from previous step)
mobilenetv2_quantized_ns, # model B, with loggers (from previous step)
ns.OutputLogger, # logger class to extract data from
'int8', # string name of model to use for layer names for the output
)
# add SQNR comparison
ns.extend_logger_results_with_comparison(
mobilenetv2_act_compare_dict, # results object to modify inplace
'fp32', # string name of model A (from previous step)
'int8', # string name of model B (from previous step)
torch.ao.ns.fx.utils.compute_sqnr, # tensor comparison function
'sqnr', # the name to use to store the results under
)
# massage the data into a format easy to graph and print
mobilenet_v2_act_to_print = []
for idx, (layer_name, v) in enumerate(mobilenetv2_act_compare_dict.items()):
mobilenet_v2_act_to_print.append([
idx,
layer_name,
v['node_output']['int8'][0]['prev_node_target_type'],
v['node_output']['int8'][0]['values'][0].shape,
v['node_output']['int8'][0]['sqnr'][0]])
# plot the SQNR between fp32 and int8 activations for each layer
plot(
[x[0] for x in mobilenet_v2_act_to_print],
[x[4] for x in mobilenet_v2_act_to_print],
'idx',
'sqnr',
'unshadowed activations, idx to sqnr',
)
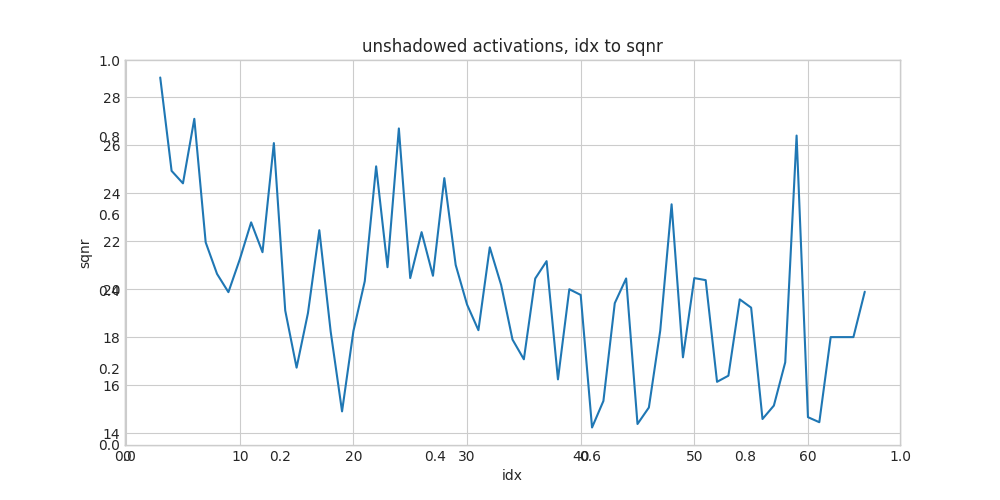
Also print out the SQNR, so we can inspect the layer name and type:
print(tabulate(
mobilenet_v2_act_to_print,
headers=['idx', 'layer_name', 'type', 'shape', 'sqnr']
))
idx layer_name type shape sqnr
----- -------------------- --------------------------------------------------------- ----------------------------- --------
0 features_0_0 torch.ao.nn.intrinsic.modules.fused.ConvReLU2d torch.Size([1, 32, 112, 112]) inf
1 features_1_conv_0_0 torch.ao.nn.intrinsic.modules.fused.ConvReLU2d torch.Size([1, 32, 112, 112]) inf
2 features_1_conv_1 torch.nn.modules.conv.Conv2d torch.Size([1, 16, 112, 112]) inf
3 features_2_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 96, 112, 112]) 28.8309
4 features_2_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 96, 56, 56]) 24.9368
5 features_2_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 24, 56, 56]) 24.4167
6 features_3_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 144, 56, 56]) 27.1074
7 features_3_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 144, 56, 56]) 21.9543
8 features_3_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 24, 56, 56]) 20.6387
9 add torch._ops.quantized.PyCapsule.add torch.Size([1, 24, 56, 56]) 19.8779
10 features_4_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 144, 56, 56]) 21.244
11 features_4_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 144, 28, 28]) 22.7892
12 features_4_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 32, 28, 28]) 21.5443
13 features_5_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 192, 28, 28]) 26.0957
14 features_5_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 192, 28, 28]) 19.1121
15 features_5_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 32, 28, 28]) 16.729
16 add_1 torch._ops.quantized.PyCapsule.add torch.Size([1, 32, 28, 28]) 19.0073
17 features_6_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 192, 28, 28]) 22.4615
18 features_6_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 192, 28, 28]) 18.2326
19 features_6_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 32, 28, 28]) 14.9052
20 add_2 torch._ops.quantized.PyCapsule.add torch.Size([1, 32, 28, 28]) 18.2546
21 features_7_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 192, 28, 28]) 20.3349
22 features_7_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 192, 14, 14]) 25.1257
23 features_7_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 64, 14, 14]) 20.9186
24 features_8_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 384, 14, 14]) 26.7062
25 features_8_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 384, 14, 14]) 20.466
26 features_8_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 64, 14, 14]) 22.3811
27 add_3 torch._ops.quantized.PyCapsule.add torch.Size([1, 64, 14, 14]) 20.5608
28 features_9_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 384, 14, 14]) 24.6337
29 features_9_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 384, 14, 14]) 21.0127
30 features_9_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 64, 14, 14]) 19.3615
31 add_4 torch._ops.quantized.PyCapsule.add torch.Size([1, 64, 14, 14]) 18.2917
32 features_10_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 384, 14, 14]) 21.7471
33 features_10_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 384, 14, 14]) 20.1782
34 features_10_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 64, 14, 14]) 17.901
35 add_5 torch._ops.quantized.PyCapsule.add torch.Size([1, 64, 14, 14]) 17.0778
36 features_11_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 384, 14, 14]) 20.4463
37 features_11_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 384, 14, 14]) 21.1711
38 features_11_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 96, 14, 14]) 16.2402
39 features_12_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 576, 14, 14]) 20.0003
40 features_12_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 576, 14, 14]) 19.7622
41 features_12_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 96, 14, 14]) 14.2331
42 add_6 torch._ops.quantized.PyCapsule.add torch.Size([1, 96, 14, 14]) 15.3402
43 features_13_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 576, 14, 14]) 19.4187
44 features_13_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 576, 14, 14]) 20.449
45 features_13_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 96, 14, 14]) 14.3788
46 add_7 torch._ops.quantized.PyCapsule.add torch.Size([1, 96, 14, 14]) 15.0659
47 features_14_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 576, 14, 14]) 18.2698
48 features_14_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 576, 7, 7]) 23.5424
49 features_14_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 160, 7, 7]) 17.1604
50 features_15_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 960, 7, 7]) 20.4648
51 features_15_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 960, 7, 7]) 20.379
52 features_15_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 160, 7, 7]) 16.138
53 add_8 torch._ops.quantized.PyCapsule.add torch.Size([1, 160, 7, 7]) 16.394
54 features_16_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 960, 7, 7]) 19.5766
55 features_16_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 960, 7, 7]) 19.2316
56 features_16_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 160, 7, 7]) 14.5871
57 add_9 torch._ops.quantized.PyCapsule.add torch.Size([1, 160, 7, 7]) 15.1467
58 features_17_conv_0_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 960, 7, 7]) 16.9515
59 features_17_conv_1_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 960, 7, 7]) 26.4096
60 features_17_conv_2 torch.ao.nn.quantized.modules.conv.Conv2d torch.Size([1, 320, 7, 7]) 14.6639
61 features_18_0 torch.nn.intrinsic.quantized.modules.conv_relu.ConvReLU2d torch.Size([1, 1280, 7, 7]) 14.4532
62 adaptive_avg_pool2d torch.nn.functional.adaptive_avg_pool2d torch.Size([1, 1280, 1, 1]) 18.0029
63 flatten torch._VariableFunctionsClass.flatten torch.Size([1, 1280]) 18.0029
64 classifier_0 torch.ao.nn.quantized.modules.dropout.Dropout torch.Size([1, 1280]) 18.0029
65 classifier_1 torch.ao.nn.quantized.modules.linear.Linear torch.Size([1, 1000]) 19.8965
Total running time of the script: ( 0 minutes 6.514 seconds)